Por Paulo Freitas de Araujo Filho
Este é o terceiro post de nosso blog da série “Fortalecendo Sistemas de Detecção de Intrusão com Machine Learning“. Neste post, discutimos como detectar atividades maliciosas usando algoritmos de detecção baseados em one-class novelty detection. Não se preocupe, é apenas um nome extravagante. Vamos começar!
Como mostrado em nossos posts anteriores, algoritmos de machine learning podem ser usados para classificar padrões de dados em diferentes classes. Por exemplo, eles podem ser usados para classificar entre imagens de cães e gatos ou dados benignos e maliciosos de redes e sistemas. Desse modo, uma abordagem comum para o treinamento de tais classificadores é fornecer para eles exemplos de dados de todas as classes, ou seja, damos ao classificador várias imagens de cães e gatos ou vários dados benignos e maliciosos para que ele aprenda a distinguir entre as amostras de cada classe [1].
Entretanto, embora possa ser fácil ter muitas imagens de cães e gatos, e até mesmo dados benignos de redes e sistemas, pode ser extremamente difícil e caro adquirir amostras maliciosas de ataques cibernéticos [2]. Assim, uma abordagem para o treinamento desse classificador binário, que distingue entre duas classes, é treiná-lo com dados de apenas uma das classes para que ele aprenda a identificar amostras de dados que se encontram dentro da distribuição de dados das amostras de treinamento. De maneira mais simples, o classificador aprende a identificar as amostras que pertencem à classe considerada no treinamento e aquelas que não estão de acordo com esse padrão. Esses classificadores são chamados classificadores baseados em one-class novelty detection e podem ser treinados apenas com dados benignos de redes e sistemas para que sejam usados em sistemas de detecção de intrusão (Intrusion Detection Systems – IDSs) para distinguir entre amostras benignas e não benignas, ou seja, amostras maliciosas [3].
Classificadores de uma classe
Há muitos algoritmos one-class novelty detection. Em geral, podemos dividi-los em dois grupos: 1) técnicas tradicionais de aprendizagem de máquina e 2) métodos de aprendizagem profunda (deep learning). O primeiro inclui várias técnicas que dependem de algoritmos tradicionais de machine learning, tais como one-class support vector machines (OCSVM) [4] e isolation forest (iForest) [5], que são amplamente adotadas em tarefas de detecção de anomalias [3], [4], [6]. O outro grupo depende de algoritmos e estruturas de deep learning, tais como autoencoders [7] e redes generativas adversariais (generative adversarial networks – GANs) [8], que têm mostrado resultados promissores na detecção de intrusões. Neste post de blog, focamos nas técnicas tradicionais, enquanto que autoencoders e GANs serão discutidos nos seguintes posts de blog desta série.
One-Class Support Vector Machines
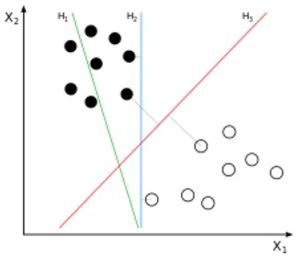
O algoritmo OCSVM constrói um hiperplano ótimo para separar amostras de dados que são similares às consideradas no treinamento daquelas que não o são, ou seja, que separa amostras de dados de duas classes. O hiperplano funciona como uma função de fronteira de decisão f que retorna +1 para amostras de dados que estão de um lado do hiperplano e -1 caso contrário. Para minimizar erros (falsos positivos e falsos negativos), o OCSVM encontra tal fronteira de decisão ao resolver um problema de otimização que maximiza as margens de separação entre cada classe [6]. A Figura 1 apresenta amostras de dados de duas classes e três possíveis hiperplanos. O hiperplano H1 não consegue separar as duas classes. H2 as separa, mas sem maximizar as margens, pois as amostras de uma das classes estão muito mais próximas do hiperplano do que as outras. Finalmente, H3 separa as duas classes com a margem máxima, o que ilustra a fronteira de decisão que o OCSVM visa encontrar. A Figura 2 detalha o hiperplano do OCSVM, maximizando as margens entre as duas classes.
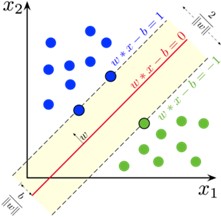
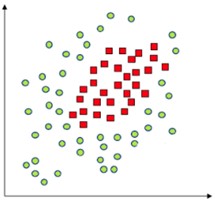
Como mostrado nas Figuras 1 e 2, o algoritmo OCSVM é bem intuitivo quando as duas classes consideradas são linearmente separáveis, ou seja, quando as amostras de dados podem ser divididas por um hiperplano. Entretanto, este nem sempre é o caso. Por exemplo, não há um hiperplano que possa separar as duas classes da Figura 3. Neste caso, o OCSVM utiliza uma transformação de kernel que mapeia as amostras para outra dimensão onde elas são separáveis [10]. A Figura 4 ilustra essa mudança.
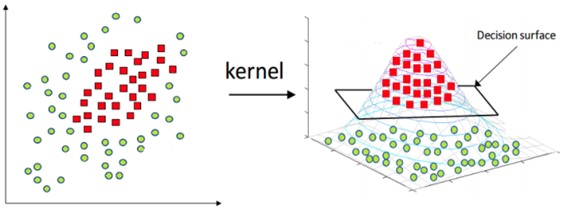
Assim, o OCSVM combinado com uma transformação de kernel é um poderoso algoritmo, fortemente baseado em conceitos matemáticos e de otimização, para classificar entre duas classes, tais como amostras benignas e maliciosas. Vários pesquisadores adotam esta estratégia para propor IDSs [4], [6].
Isolation Forest
Suponha que tenhamos um grupo de amostras de dados de uma rede ou sistema. Cada uma delas tem vários atributos, como o número de bytes e pacotes transmitidos por uma rede. Podemos escolher aleatoriamente um dos atributos das amostras e um valor de separação entre os valores máximo e mínimo do atributo selecionado para separar as amostras. Ou seja, separamos as amostras cujo valor do atributo selecionado está acima ou abaixo do valor de separação escolhido. Então, repetimos este processo várias vezes, selecionando aleatoriamente um atributo e um valor de separação para separar as amostras até que todas elas estejam isoladas umas das outras [5], [6].
Como, em geral, anomalias representam apenas uma pequena porção dos dados normais e apresentam atributos muito diferentes deles, elas tendem a ser isoladas com menos partições do que os dados normais. Em outras palavras, uma vez que as amostras benignas são a maioria, esperamos que elas sejam isoladas umas das outras com muitas operações de partição. Por outro lado, esperamos que as amostras maliciosas, que são a minoria, sejam separadas das outras amostras com menos operações [5], [6]. O lado esquerdo da Figura 5 ilustra que muitas operações de separação são necessárias para isolar amostras benignas. O lado direito da Figura 5 ilustra que apenas algumas operações de separação são necessárias para isolar amostras maliciosas.
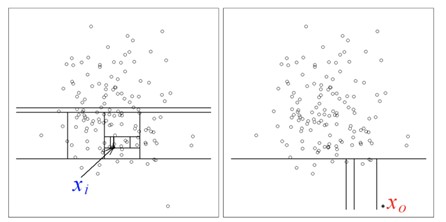
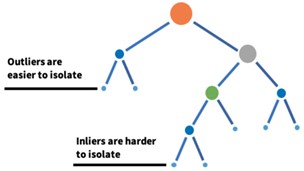
Este tipo de partição recursiva pode ser representado por uma estrutura em árvore, de modo que o número de divisões necessárias para isolar uma amostra seja equivalente ao comprimento do caminho desde o nó raiz até o nó terminal. Portanto, como as anomalias requerem menos partições, elas estão mais próximas da raiz da árvore. A Figura 6 representa tal estrutura de árvore, que é chamada de árvore de isolamento (isolation tree) [5], [6].
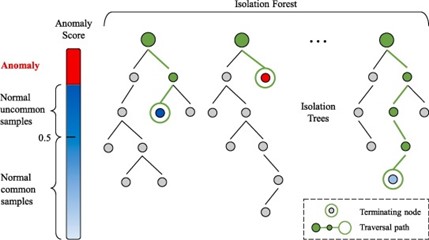
Como cada partição é conduzida com base na escolha aleatória de um atributo e um valor de separação, decidir que uma amostra é maliciosa ou não, baseada apenas nessas escolhas, pode causar muitos erros. Assim, o algoritmo isolation forest considera um conjunto de muitas isolation trees e decide se uma amostra é maliciosa ou não com base em uma pontuação de anomalia (anomaly score) dado pela média do comprimento do caminho de todas as árvores de isolamento [5], [6]. Portanto, este algoritmo identifica explicitamente as anomalias através da média do comprimento do caminho das árvores de isolamento, que produzem caminhos mais curtos para as anomalias [6]. A Figura 7 mostra a estrutura da floresta de isolamento (isolation forest).
Desafios e desvantagens
Embora algoritmos tradicionais baseados em one-class novelty detection, tais como o OCSVM e o isolation forest tenham demonstrado ser muito precisos e rápidos na detecção de atividades maliciosas [6], eles também apresentam limitações e desvantagens.
Em primeiro lugar, embora esses algoritmos sejam treinados com amostras de apenas uma classe, precisamos garantir que todos os dados de treinamento sejam realmente da mesma classe desejada. Por exemplo, para treinar o OCSVM ou o isolation forest com apenas dados benignos de uma rede, não podemos ter amostras maliciosas contaminando os dados de treinamento. Caso contrário, nosso modelo poderia ser induzido a acreditar que amostras maliciosas são benignas. Garantir isto é muito desafiador e pode requerer que os dados de treinamento sejam analisados previamente por técnicas de agrupamento (clustering) [2], [15].
Além disso, embora tais algoritmos tradicionais apresentem taxas baixas de falsos positivos e falsos negativos, eles exigem um esforço extra para selecionar e extrair os atributos (features) que garantem boas taxas de detecção. Por outro lado, técnicas baseadas em deep learning, tais como autoencoders e GANs, não exigem tal processo de engenharia de features, pois as próprias redes neurais profundas têm a capacidade de selecionar e extrair automaticamente as melhores features [8].
Conclusão
Neste post, discutimos métodos tradicionais de detecção baseados em one-class novelty detection. Precisamente, mostramos como os algoritmos OCSVM e isolation forest podem ser usados para detectar atividades maliciosas sendo treinados apenas com dados benignos. Na Tempest, estamos investigando e utilizando tais técnicas para melhor proteger seu negócio! Fique de olho para o nosso próximo post!
Referências
[1] N. Chaabouni, M. Mosbah, A. Zemmari, C. Sauvignac, and P. Faruki, “Network Intrusion Detection for IoT Security Based on Learning Techniques,” IEEE Commun. Surveys & Tut., vol. 21, no. 3, pp. 2671–2701, 2019. doi: 10.1109/COMST.2019.2896380.
[2] A. Nisioti, A. Mylonas, P. D. Yoo and V. Katos, “From Intrusion Detection to Attacker Attribution: A Comprehensive Survey of Unsupervised Methods,” in IEEE Commun. Surveys & Tut., vol. 20, no. 4, pp. 3369-3388, Fourth quarter 2018, doi: 10.1109/COMST.2018.2854724.
[3] M. A. F. Pimentel, D. A. Clifton, L. Clifton, and L. Tarassenko, ‘‘A review of novelty detection,’’ Signal Process., vol. 99, pp. 215–249, Jun. 2014.
[4] V. Chandola, A. Banerjee, and V. Kumar, ‘‘Anomaly detection: A survey,’’ ACM Comput. Surv., vol. 41, no. 3, p. 15, 2009
[5] F. T. Liu, K. M. Ting, and Z.-H. Zhou, ‘‘Isolation-based anomaly detection,’’ ACM Trans. Knowl. Discovery Data, vol. 6, no. 1, pp. 3:1–3:39, Mar. 2012.
[6] P. Freitas De Araujo-Filho, A. J. Pinheiro, G. Kaddoum, D. R. Campelo and F. L. Soares, “An Efficient Intrusion Prevention System for CAN: Hindering Cyber-Attacks With a Low-Cost Platform,” in IEEE Access, vol. 9, pp. 166855-166869, 2021, doi: 10.1109/ACCESS.2021.3136147.
[7] Yisroel Mirsky, Tomer Doitshman, Yuval Elovici, and Asaf Shabtai. Kitsune: an ensemble of autoencoders for online network intrusion detection. arXiv preprint arXiv:1802.09089, 2018
[8] P. Freitas de Araujo-Filho, G. Kaddoum, D. R. Campelo, A. Gondim Santos, D. Macêdo and C. Zanchettin, “Intrusion Detection for Cyber–Physical Systems Using Generative Adversarial Networks in Fog Environment,” in IEEE Internet of Things J., vol. 8, no. 8, pp. 6247-6256, 15 April15, 2021, doi: 10.1109/JIOT.2020.3024800.
[9] Wikipedia. Support-vector machine. Acessado: Abr. 15, 2022. [Online]. Disponível em: https://en.wikipedia.org/wiki/Support-vector_machine
[10] D. Wilimitis. The Kernel Trick in Support Vector Classification. Acessado: Abr. 15, 2022. [Online]. Disponível em: https://towardsdatascience.com/the-kernel-trick-c98cdbcaeb3f
[11] G. Zhang. What is the kernel trick? Why is it important?. Acessado: Abr. 15, 2022. [Online]. Disponível em: https://medium.com/@zxr.nju/what-is-the-kernel-trick-why-is-it-important-98a98db0961d
[12] E. Lewinson. Outlier Detection with Isolation Forest. Acessado: Abr. 15, 2022. [Online]. Disponível em: https://towardsdatascience.com/outlier-detection-with-isolation-forest-3d190448d45e
[13] J. Verbus. Detecting and preventing abuse on LinkedIn using isolation forests. Acessado: Abr. 15, 2022. [Online]. Disponível em: https://engineering.linkedin.com/blog/2019/isolation-forest
[14] H. Chen, H. Ma, X. Chu, and D. Xue, “Anomaly detection and critical attributes identification for products with multiple operating conditions based on isolation forest,” Advanced Engineering Informatics, vol. 46, Oct. 2020, doi: 10.1016/j.aei.2020.101139.
[15] I. Ghafir, K. G. Kyriakopoulos, F. J. Aparicio-Navarro, S. Lambotharan, B. Assadhan and H. Binsalleeh, “A Basic Probability Assignment Methodology for Unsupervised Wireless Intrusion Detection,” in IEEE Access, vol. 6, pp. 40008-40023, 2018, doi: 10.1109/ACCESS.2018.2855078.
Outros artigos dessa série:
Fortalecendo Sistemas de Detecção de Intrusão com Machine Learning
Parte 1 de 5: Sistemas de Detecção de Intrusão baseados em Assinaturas versus Anomalias
Parte 2 de 5: Sistemas de Detecção de Intrusão Não Supervisionados usando Clustering
Parte 3 de 5: Sistemas de Detecção de Intrusão baseados em One-Class Novelty Detection
Parte 4 de 5: Detecção de Intrusão usando Autoencoders
Parte 5 de 5: Detecção de Intrusão usando Generative Adversarial Networks