By Paulo Freitas de Araujo Filho
This is the third blog post of our series “Empowering Intrusion Detection Systems with Machine Learning”. In this post, we discuss how to detect malicious activities using one-class novelty detection algorithms. Don’t worry, it is just a fancy name. Let’s dig into it.
As shown in our previous posts, machine learning algorithms can be used to classify data patterns into different classes. For example, they can be used to classify between images of cats and dogs or between benign and malicious data from networks and systems. A common approach for training such classifiers is to provide them with data examples from all classes. That is, we give to the classifier a bunch of images from cats and dogs or a bunch of benign and malicious data so that it learns how to distinguish between the samples from each class [1].
However, while it may be easy to have a lot of cat and dog images, and even benign data from networks and systems, it might be extremely difficult and expensive to acquire malicious samples from cyber-attacks [2]. Thus, an alternative approach for training such a binary classifier, i.e., a classifier that distinguishes between two classes, is to train it with data from only one of the classes so that it learns to identify data samples that lie within the data distribution of the training samples. In a simpler way, the classifier learns to identify the samples that belong to the class considered in training and those that do not conform to that pattern. Those classifiers are called one-class novelty detection classifiers and they can be trained with only benign data of networks and systems so that they are used in intrusion detection systems (IDSs) to distinguish between benign and not benign, i.e., malicious samples [3].
One-Class Classifiers
There are many one-class novelty detection algorithms. In general, we can divide them into two groups: traditional machine learning techniques and deep learning methods. The former includes several techniques that rely on traditional machine learning algorithms, such as one-class support vector machines (OCSVM) [4] and isolation forests (iForest) [5], which are largely adopted in anomaly detection tasks [3], [4], [6]. The latter rely on deep learning algorithms and frameworks, such as autoencoders [7] and generative adversarial networks (GANs) [8], which have been showing promising results at detecting intrusions. In this blog post, we focus on the traditional techniques, while autoencoders and GANs will be discussed in the following blog posts of this series.
One-Class Support Vector Machines
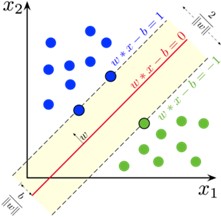
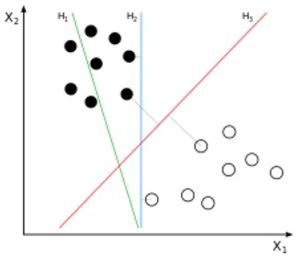
The one-class support vector machine (OCSVM) algorithm constructs an optimal hyperplane for separating data samples that are similar to the ones considered in training from those that are not, i.e., that separates data samples from two classes. The hyperplane works as a decision boundary function f that returns +1 for data samples that lie within one side of the hyperplane and -1 otherwise. To minimize mistakes, i.e., false positives and false negatives, the OCSVM finds such a decision boundary by solving an optimization problem that maximizes the separation margins between each class [6]. Figure 1 shows data samples from two classes and three possible hyperplanes. Hyperplane H1 cannot separate the two classes. H2 separates them but without maximizing the margins as the samples from one of the classes are much closer to the hyperplane than the others. Finally, H3 separates the two classes with the maximal margin, which illustrates the decision boundary whose OCSVM aims to find. Figure 2 further details the OCSVM’s hyperplane, which maximizes the margins between two classes.
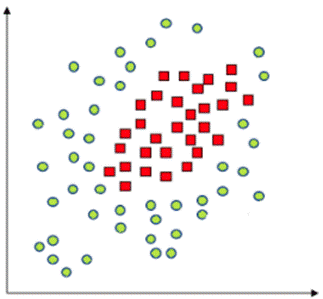
As shown in Figures 1 and 2, the OCSVM algorithm is quite intuitive when the two considered classes are linearly separable, i.e., when their data samples can be separated by a hyperplane. However, this is not always the case. For instance, there is no hyperplane that can separate the two classes of Figure 3. In this case, the OCSVM relies on a kernel transformation that maps the samples to another dimension where they are separable [10]. Figure 4 illustrates such a transformation.
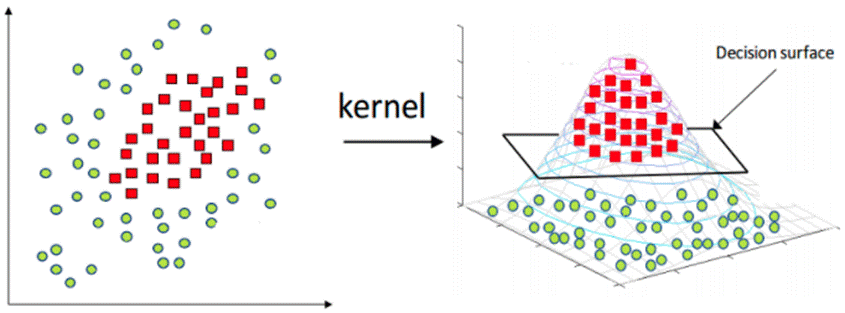
Therefore, the OCSVM combined with the kernel transformation represents a powerful algorithm, strongly based on mathematical and optimization concepts, for classifying between two classes, such as benign and malicious samples. Several researchers have relied on such a strategy to propose IDSs [4], [6].
Isolation Forest
Suppose that we have a group of data samples from a network or system. Each of them has several attributes, such as the number of bytes and packets transmitted over a network. We can randomly pick one of the samples’ attributes and a split value between the maximum and minimum values of that selected attribute to separate the samples according to that split value. That is, we separate the samples whose value of the selected attribute is above or below the selected threshold value. Then, we repeat this process several times and keep randomly selecting an attribute and a split value to separate the samples until all samples are isolated from each other [5], [6].
Since anomalies are considered to make up a small percentage of the normal data and have very different attributes than normal data, they tend to be isolated with fewer partitions than normal data. In other words, since the bening samples are the majority, we expect them to be isolated from each other with many split operations. On the other hand, we expect that malicious samples, which are the minority, to be separated from each other with fewer split operations [5], [6]. The left side of Figure 5 illustrates that many separation operations are required to isolate benign samples. The right side of Figure 5 illustrates that just a few separation operations are required to isolate malicious samples.
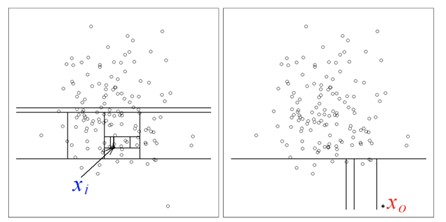
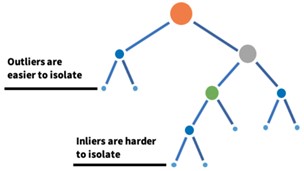
Such a recursive partitioning can be represented by a tree structure so that the number of splittings required to isolate a sample is equivalent to the path length from the root node to the terminating node. Hence, since anomalies require less partitionings, they are closer to the root of the tree. Figure 6 represents such a tree structure, which is called an isolation tree [5], [6].
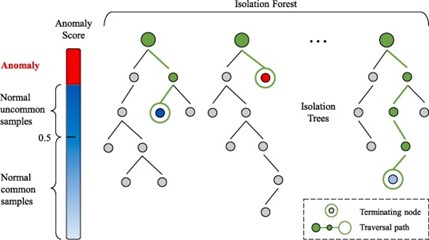
Since each partitioning is conducted based on the random choice of an attribute and a split value, deciding that a sample is malicious or not based on just those choices may introduce a lot of errors. Thus, the isolation forest algorithm considers an ensemble of many isolation trees and decides whether a sample is malicious or not based on an anomaly score that averages the path length of all isolation trees [5], [6]. Therefore, the isolation forest algorithm explicitly identifies anomalies by averaging the path length of isolation trees, which produce noticeable shorter paths for anomalies [6]. Figure 7 shows the isolation forest structure.
Challenges and drawbacks
While traditional one-class novelty detection algorithms, such as the OCSVM and the isolation forest algorithms have shown to be very accurate and fast at detecting malicious activities [6], they also present limitations and drawbacks.
First, although those algorithms are trained with samples from only one class, we need to ensure that all training data are actually from the desired same class. For example, to train an OCSVM or an isolation forest with only bening data from a network, we cannot have malicious samples contaminating the bening training data. Otherwise, our trained model could be misled to believe that those malicious samples are bening. Providing such a guarantee is very challenging and might require the training data to be first analyzed with clustering techniques [2], [15].
Moreover, although such traditional algorithms present low false positive and false negative rates, they require an extra effort for selecting and extracting the features that will grant those good results. On the other hand, deep learning-based techniques, such as autoencoders and GANs, do not require such a feature engineering as the deep neural networks themselves have the ability to automatically select and extract features [8].
Conclusion
In this post, we discussed traditional one-class novelty detection methods. Precisely, we showed how the OCSVM and the isolation forest algorithms can be used to detect malicious activities while being trained with only bening data. At Tempest, we are investigating and relying on such techniques to better protect your business! Stay tuned for our next post!
References
[1] N. Chaabouni, M. Mosbah, A. Zemmari, C. Sauvignac, and P. Faruki, “Network Intrusion Detection for IoT Security Based on Learning Techniques,” IEEE Commun. Surveys & Tut., vol. 21, no. 3, pp. 2671–2701, 2019. doi: 10.1109/COMST.2019.2896380.
[2] A. Nisioti, A. Mylonas, P. D. Yoo and V. Katos, “From Intrusion Detection to Attacker Attribution: A Comprehensive Survey of Unsupervised Methods,” in IEEE Commun. Surveys & Tut., vol. 20, no. 4, pp. 3369-3388, Fourth quarter 2018, doi: 10.1109/COMST.2018.2854724.
[3] M. A. F. Pimentel, D. A. Clifton, L. Clifton, and L. Tarassenko, ‘‘A review of novelty detection,’’ Signal Process., vol. 99, pp. 215–249, Jun. 2014.
[4] V. Chandola, A. Banerjee, and V. Kumar, ‘‘Anomaly detection: A survey,’’ ACM Comput. Surv., vol. 41, no. 3, p. 15, 2009
[5] F. T. Liu, K. M. Ting, and Z.-H. Zhou, ‘‘Isolation-based anomaly detection,’’ ACM Trans. Knowl. Discovery Data, vol. 6, no. 1, pp. 3:1–3:39, Mar. 2012.
[6] P. Freitas De Araujo-Filho, A. J. Pinheiro, G. Kaddoum, D. R. Campelo and F. L. Soares, “An Efficient Intrusion Prevention System for CAN: Hindering Cyber-Attacks With a Low-Cost Platform,” in IEEE Access, vol. 9, pp. 166855-166869, 2021, doi: 10.1109/ACCESS.2021.3136147.
[7] Yisroel Mirsky, Tomer Doitshman, Yuval Elovici, and Asaf Shabtai. Kitsune: an ensemble of autoencoders for online network intrusion detection. arXiv preprint arXiv:1802.09089, 2018
[8] P. Freitas de Araujo-Filho, G. Kaddoum, D. R. Campelo, A. Gondim Santos, D. Macêdo and C. Zanchettin, “Intrusion Detection for Cyber–Physical Systems Using Generative Adversarial Networks in Fog Environment,” in IEEE Internet of Things J., vol. 8, no. 8, pp. 6247-6256, 15 April15, 2021, doi: 10.1109/JIOT.2020.3024800.
[9] Wikipedia. Support-vector machine. Accessed: Apr. 15, 2022. [Online]. Available: https://en.wikipedia.org/wiki/Support-vector_machine
[10] D. Wilimitis. The Kernel Trick in Support Vector Classification. Accessed: Apr. 15, 2022. [Online]. Available: https://towardsdatascience.com/the-kernel-trick-c98cdbcaeb3f
[11] G. Zhang. What is the kernel trick? Why is it important?. Accessed: Apr. 15, 2022. [Online]. Available: https://medium.com/@zxr.nju/what-is-the-kernel-trick-why-is-it-important-98a98db0961d
[12] E. Lewinson. Outlier Detection with Isolation Forest. Accessed: Apr. 15, 2022. [Online]. Available: https://towardsdatascience.com/outlier-detection-with-isolation-forest-3d190448d45e
[13] J. Verbus. Detecting and preventing abuse on LinkedIn using isolation forests. Accessed: Apr. 15, 2022. [Online]. Available: https://engineering.linkedin.com/blog/2019/isolation-forest
[14] H. Chen, H. Ma, X. Chu, and D. Xue, “Anomaly detection and critical attributes identification for products with multiple operating conditions based on isolation forest,” Advanced Engineering Informatics, vol. 46, Oct. 2020, doi: 10.1016/j.aei.2020.101139.
[15] I. Ghafir, K. G. Kyriakopoulos, F. J. Aparicio-Navarro, S. Lambotharan, B. Assadhan and H. Binsalleeh, “A Basic Probability Assignment Methodology for Unsupervised Wireless Intrusion Detection,” in IEEE Access, vol. 6, pp. 40008-40023, 2018, doi: 10.1109/ACCESS.2018.2855078.
Other articles in this series
Empowering Intrusion Detection Systems with Machine Learning – Part 1 of 5: Signature vs. Anomaly-Based Intrusion Detection Systems
Empowering Intrusion Detection Systems with Machine Learning – Part 2 of 5:
Clustering-Based Unsupervised Intrusion Detection Systems