Por Paulo Freitas de Araujo Filho
Este é o segundo post no blog da nossa série “Fortalecendo Sistemas de Detecção de Intrusão com Machine Learning”, onde discutimos como aprendizagem de máquina pode ser usada em sistemas de detecção de intrusão (Intrusion Detection Systems – IDS) para detectar ciberataques complexos e desconhecidos de forma mais eficaz. Em nosso primeiro post, discutimos que há quatro métodos que são mais comumente usados em IDSs não supervisionados do estado da arte: clustering, one-class novelty detection, autoencoders e Generative Adversarial Networks (GANs). Agora, vamos nos aprofundar um pouco mais no primeiro destes métodos e discutir como técnicas de clustering são usadas em IDSs não supervisionados.
Os algoritmos de clustering, ou agrupamento, analisam e organizam amostras de dados em grupos de acordo com sua similaridade, ou seja, amostras que são semelhantes umas às outras são reunidas no mesmo grupo, e amostras que são diferentes umas das outras são colocadas em diferentes grupos [1]-[3]. Embora a ideia de similaridade e diferença entre amostras de dados possa ser um pouco abstrata, geralmente está relacionada a uma métrica de distância escolhida. Assim, considera-se que duas amostras são semelhantes se a distância entre elas, de acordo com uma métrica escolhida, estiver abaixo de um limite. Caso contrário, elas são consideradas como diferentes [1]-[3]. Para ilustrar, imagine que cada amostra de dados seja representada por um ponto. Assim, podemos escolher a distância euclidiana, ou seja, o comprimento de um segmento de reta, e medir a distância entre os pontos dos dados para avaliar se eles estão próximos ou distantes uns dos outros.
Como as atividades maliciosas geralmente diferem do comportamento benigno, algoritmos de agrupamento podem ser usados para detectar ciberataques em IDSs [1]. A seguir, discutimos duas abordagens para detectar atividades maliciosas, e anomalias em geral, com técnicas de clustering.
Um Agrupamento Malicioso
Uma abordagem simples para detectar anomalias é usar algoritmos de clustering para analisar um grupo de amostras de dados coletadas de redes e sistemas, e agrupá-las em dois clusters (conjuntos). Como as amostras maliciosas são muito menos frequentes do que as amostras benignas, espera-se que a grande maioria delas sejam benignas. Assim, considera-se que o maior agrupamento compreende as amostras benignas e o menor agrupamento compreende as amostras maliciosas [4]. Dessa forma, no momento da detecção, as amostras são avaliadas e atribuídas ao grupo bening ou malicioso para que o conjunto ao qual são atribuídas indique se elas são benignas ou maliciosas [1].
Nenhum grupo malicioso
Uma abordagem diferente e mais robusta para detectar anomalias é deixar que o algoritmo de agrupamento forme livremente quantos clusters quiser e não ter que atribuir obrigatoriamente cada amostra a um grupo [5], [6]. Ou seja, enquanto dezenas de clusters podem ser formados, algumas amostras podem não ser atribuídas a nenhum deles. Diferentemente da abordagem anterior, que atribui as amostras maliciosas a um grupo, considera-se agora que cada grupo formado representa um comportamento de dados benignos e que as amostras maliciosas são aquelas que não são atribuídas a nenhum dos grupos construídos. No momento da detecção, as amostras são avaliadas e atribuídas a um ou nenhum dos grupos formados, de modo que neste último caso, elas são consideradas maliciosas [1].
Ajudando outros algoritmos de detecção
Embora os IDSs não supervisionados não exijam explicitamente o uso de rótulos, muitos deles precisam garantir que somente dados benignos sejam usados para o treinamento de seus modelos de detecção. Esses IDSs aprendem um padrão de dados normais e consideram os desvios desse padrão como atividades maliciosas. Portanto, eles não podem se dar ao luxo de ter amostras de treinamento maliciosas, pois isso comprometeria o padrão aprendido e, consequentemente, a acurácia do IDS. Portanto, embora as técnicas de clustering possam ser aplicadas diretamente para detectar anomalias, elas também podem ser combinadas a IDSs não supervisionados para garantir que eles sejam treinados apenas com dados benignos. Como exemplo, o trabalho em [4] utilizou o algoritmo k-means para construir dois clusters para as amostras de tráfego de uma rede Wi-Fi. Em seguida, considerou que o menor grupo formado representava tráfego malicioso e filtrou as amostras maliciosas para construir uma linha de base mais precisa de normalidade, que mais tarde foi usada para treinar outros modelos de detecção.
IDSs supervisionados, por sua vez, exigem que as amostras de treinamento sejam rotuladas como normais ou maliciosas, e inclusive como diferentes tipos de amostras maliciosas quando é necessário distinguir entre atividades maliciosas distintas. Contudo, a análise manual de grandes quantidades de amostras de dados para obtenção de rótulos é impraticável e muito cara. Assim, como técnicas de clustering reúnem amostras similares, elas podem reduzir significativamente o número de amostras analisadas manualmente, permitindo que a rotulagem de uma amostra de um agrupamento seja usada para todas as suas amostras [1].
Algoritmos de clustering
Agora que discutimos como técnicas de clustering podem ser usadas por IDSs, vamos discutir brevemente dois dos algoritmos de clustering mais utilizados: k-means [7] e Density-Based Spatial Clustering of Applications with Noise (DBSCAN) [5].
K-Means
Dado um grupo de amostras de dados, o objetivo do k-means é criar um número k de clusters de modo que cada amostra de dados pertença a um dos grupos formados [7], [8]. O primeiro passo para a construção dos clusters é selecionar aleatoriamente k centróides, que são representações do centro de cada cluster. De maneira mais simples, se cada amostra de dados pode ser representada por um ponto, o centróide de um grupo é um ponto no centro desse grupo. Em seguida, três outras etapas são repetidas para atualizar os grupos até que seus centróides tenham estabilizado e não mudem mais de lugar [4], [7], [8]:
- A distância euclidiana é calculada entre cada centróide e todas as amostras de dados.
- Cada amostra é atribuída ao centróide mais próximo que forma os grupos;
- Cada centróide de cluster é atualizado através da média da distância entre as amostras de dados dentro de cada cluster.
As figuras 1, 2, e 3 ilustram a construção dos clusters.
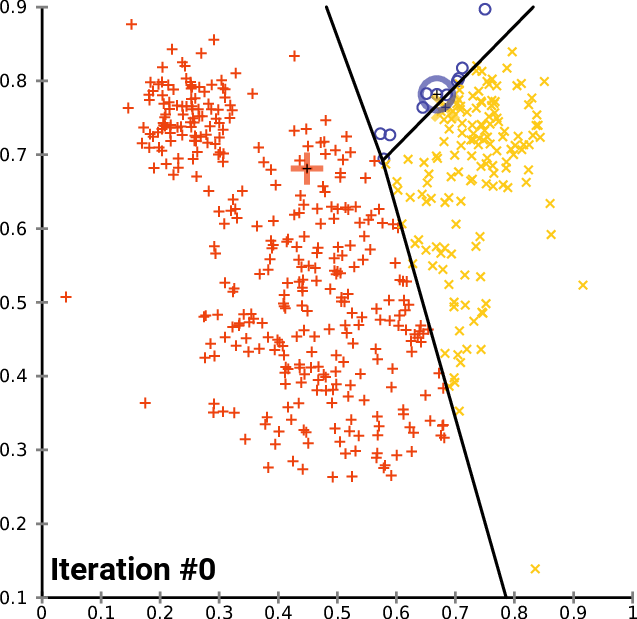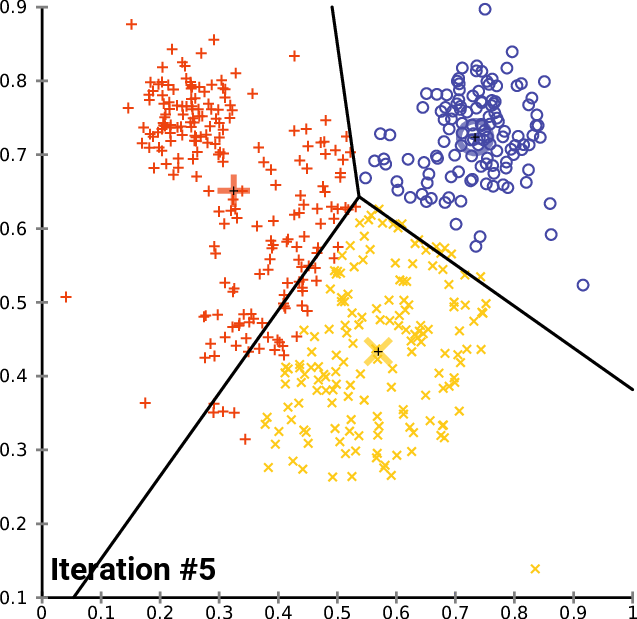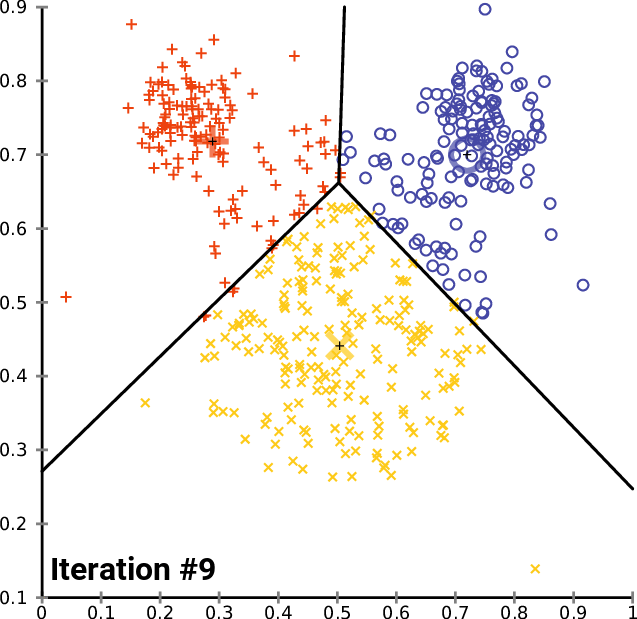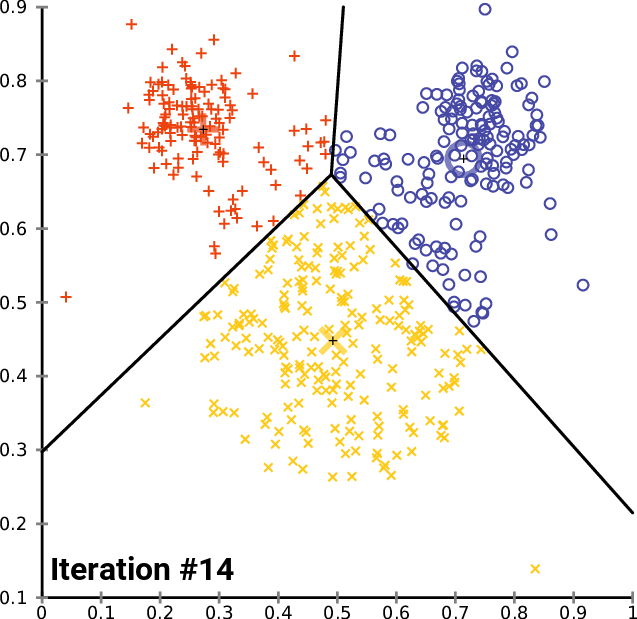

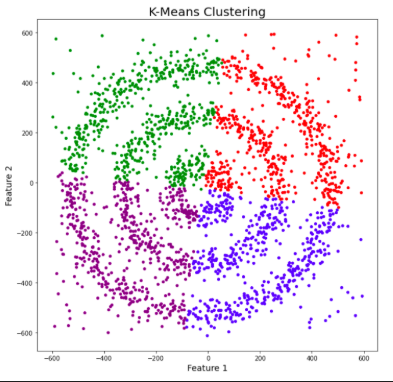
Apesar de o algoritmo k-means ser um algoritmo simples e intuitivo, ele requer que especifiquemos antecipadamente o número de clusters que serão construídos. Contudo, isso nem sempre é uma tarefa fácil. Além disso, o desempenho do k-means geralmente não é tão competitivo quanto outros algoritmos de agrupamento mais sofisticados, como o DBSCAN, pois os grupos formados assumem formatos esféricos e pequenas variações nas amostras que podem impactar significativamente os agrupamentos formados [1], [11].
DBSCAN
DBSCAN é um algoritmo de agrupamento baseado em densidade que funciona na suposição de que os agrupamentos são regiões densas no espaço separadas por regiões de menor densidade [5], [6]. Ele agrupa amostras que estão próximas umas das outras de acordo com uma métrica de distância, geralmente a distância euclidiana, e um número mínimo de amostras que devem pertencer a cada grupo. Portanto, o algoritmo DBSCAN tem dois parâmetros: o raio do círculo que é criado ao redor de cada amostra de dados, e o número mínimo de amostras que devem estar dentro de um círculo para que um grupo seja definido [5], [6].
Para um determinado raio e número mínimo de pontos, o algoritmo desenha um círculo com o raio escolhido para cada amostra de dados. As amostras cujo círculo contém pelo menos o número mínimo escolhido de amostras são consideradas como pontos centrais. Todos os pontos centrais que estão conectados entre si, ou seja, que também pertencem aos círculos dos outros pontos centrais, formam juntos um grupo. As amostras cujo círculo contém menos amostras, mas pelo menos uma outra amostra, são consideradas como pontos de borda, pois representam a borda de um grupo. Finalmente, as amostras cujo círculo não contém nenhuma outra amostra são consideradas como outliers, pois estão em regiões de baixa densidade [5], [6]. A figura 4 ilustra pontos centrais em vermelho, pontos de borda em amarelo, e outliers em azul. A figura 5 mostra três grupos em vermelho, azul e verde, e os outliers em regiões de baixa densidade.
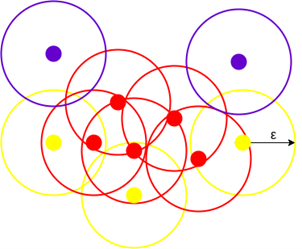
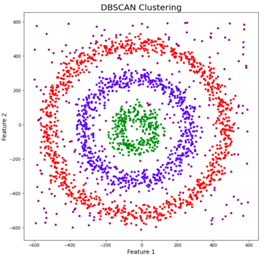
O algoritmo DBSCAN permite que amostras de dados não sejam atribuídas a nenhum dos clusters se elas estiverem em regiões de baixa densidade. Tais amostras são consideradas outliers, pois representam amostras que não estão em conformidade com os padrões dos clusters. Isto soa familiar? Sim, essas amostras de dados são anomalias que podem representar ciberataques. Portanto, o DBSCAN pode ser usado como um IDS não supervisionado [1].
Além disso, ao contrário de outras técnicas de clustering, o DBSCAN não exige que o número de agrupamentos seja especificado de antemão, o que facilita muito as coisas, pois podemos não saber com antecedência quantos padrões podem ser descobertos. Também permite a formação de clusters com formas arbitrárias, o que geralmente contribui para melhores resultados do que os algoritmos que impõem formatos esféricos [1], [11]. Por outro lado, pode ser um desafio determinar os parâmetros que devem ser usados no DBSCAN e agrupar amostras de dados com densidades muito diferentes [5], [6].
Colocando em prática
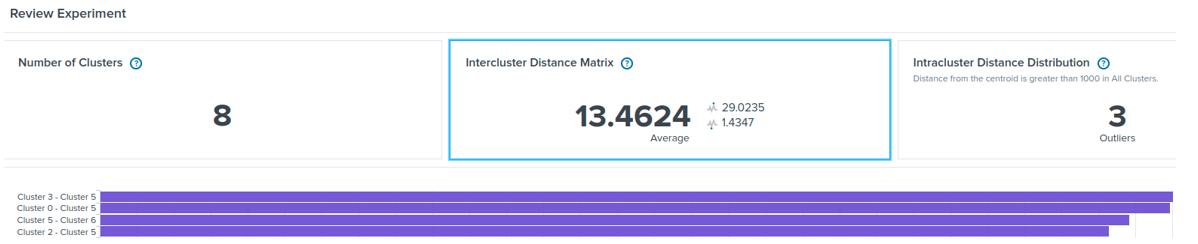
O Splunk é uma das plataformas mais utilizadas de gerenciamento de informações de segurança e eventos (security information and event management – SIEM), que reúne, gerencia e correlaciona dados e implementa regras de detecção de ataques cibernéticos. A ferramenta machine learning toolkit (MLTK) do Splunk oferece vários algoritmos de aprendizagem de máquina, tais como o K-Means e o DBSCAN. Esses algoritmos podem ser configurados, treinados e utilizados no Splunk como modelos de detecção baseados em anomalias, assim como qualquer outra regra de detecção tradicional baseada em assinatura. A Figura 6, por exemplo, mostra a distância entre oito clusters formados com o algoritmo K-Means. A Figura 7 mostra que três amostras de dados de um determinado conjunto têm uma distância maior do que a distância predefinida de um agrupamento, de modo que representam anomalias. Para mais informações, por favor, consulte [12].

Desafios e obstáculos
Embora os IDSs baseados em técnicas de clustering tenham um papel importante quando não há rótulos disponíveis, eles podem ser muito desafiadores para configurar e treinar em sistemas altamente dinâmicos em que o comportamento dos dados muda constantemente. Além disso, como os SIEMs geralmente monitoram uma quantidade enorme de dados, é muito desafiador construir conjuntos que representem bem e com eficiência os diferentes comportamentos dos dados, ao mesmo tempo em que detectam anomalias com baixas taxas de falsos positivos.
Conclusão
Conforme discutido, as técnicas de agrupamento desempenham um papel importante nos IDSs não supervisionados, detectando diretamente as anomalias ou reduzindo o número de amostras de dados que precisam ser analisadas manualmente por especialistas em cibersegurança. Na Tempest, estamos investigando o uso de técnicas de clustering e a proposta de novas técnicas para melhor proteger o seu negócio! Fique atento ao nosso próximo post!
Referências
[1] A. Nisioti, A. Mylonas, P. D. Yoo and V. Katos, “From Intrusion Detection to Attacker Attribution: A Comprehensive Survey of Unsupervised Methods,” in IEEE Commun. Surveys & Tut., vol. 20, no. 4, pp. 3369-3388, Fourth quarter 2018, doi: 10.1109/COMST.2018.2854724.
[2] N. Chaabouni, M. Mosbah, A. Zemmari, C. Sauvignac, and P. Faruki, “Network Intrusion Detection for IoT Security Based on Learning Techniques,” IEEE Commun. Surveys & Tut., vol. 21, no. 3, pp. 2671–2701, 2019. doi: 10.1109/COMST.2019.2896380.
[3] V. Chandola, A. Banerjee, and V. Kumar, “Anomaly detection: A survey,” ACM Comput. Surveys, vol. 41, no. 3, p. 15, 2009.
[4] I. Ghafir, K. G. Kyriakopoulos, F. J. Aparicio-Navarro, S. Lambotharan, B. Assadhan and H. Binsalleeh, “A Basic Probability Assignment Methodology for Unsupervised Wireless Intrusion Detection,” in IEEE Access, vol. 6, pp. 40008-40023, 2018, doi: 10.1109/ACCESS.2018.2855078.
[5] E. Schubert, J. Sander, M. Ester, H. P. Kriegel, and X. Xu, “DBSCAN revisited, revisited: Why and how you should (still) use DBSCAN,” ACM Trans. Database Syst., vol. 42, no. 3, pp. 19: 1-21, Jul. 2017.
[6] A. Sharma. How to Master the Popular DBSCAN Clustering Algorithm for Machine Learning. Acesso em: 09 de março, 2022. [Online]. Disponível: https://www.analyticsvidhya.com/blog/2020/09/how-dbscan-clustering-works/
[7] D. Arthur and S. Vassilvitskii, “K-Means++: The advantages of careful seeding,” in Proc. Symp. Discrete Algorithms, 2007, pp. 1027–1035.
[8] R. Halde. K-means Clustering: Understanding Algorithm with animation and code. Acesso em: 09 de Março, 2022. [Online]. Disponível: https://halderadhika91.medium.com/k-means-clustering-understanding-algorithm-with-animation-and-code-6e644993afab
[9] Wikimedia Commons. K-means convergence.gif. Acesso em: 09 de março, 2022. [Online]. Disponível: https://commons.wikimedia.org/wiki/File:K-means_convergence.gif
{kind=link}
[10] A. A. Shabalin. K-means clustering. Acesso em: 09 de março, 2022. [Online]. Disponível: http://shabal.in/visuals/kmeans/5.html
[11] M. G. Gumbao. Best clustering algorithms for anomaly detection. Acesso em: 09 de março, 2022. [Online]. Disponível: https://towardsdatascience.com/best-clustering-algorithms-for-anomaly-detection-d5b7412537c8
[12] Splunk. Manuals Splunk® Machine Learning Toolkit. Acesso em: 23 de junho, 2022. [Online]. Disponível: https://docs.splunk.com/Documentation/MLApp/latest
Outros artigos dessa série:
Fortalecendo Sistemas de Detecção de Intrusão com Machine Learning
Parte 1 de 5: Sistemas de Detecção de Intrusão baseados em Assinaturas versus Anomalias
Parte 2 de 5: Sistemas de Detecção de Intrusão Não Supervisionados usando Clustering
Parte 3 de 5: Sistemas de Detecção de Intrusão baseados em One-Class Novelty Detection
Parte 4 de 5: Detecção de Intrusão usando Autoencoders
Parte 5 de 5: Detecção de Intrusão usando Generative Adversarial Networks