Por Lucas Deodato & Manoelito Filho
Introdução
O Zabbix é uma plataforma de monitoramento que possibilita monitorar a saúde e disponibilidade de parâmetros de rede, máquinas virtuais, servidores, aplicações, serviços, entidades de nuvem etc. Ele oferece recursos flexíveis para notificar as partes interessadas (stakeholders) através de diversos canais de comunicação (mensageiros instantâneos, serviços de e-mail, SMS etc.), possibilitando, assim, uma resposta rápida para os problemas detectados.
O SOC (em inglês, Security Operations Center) é um Centro de Operações de Segurança que contém, entre suas diversas responsabilidades, o papel de monitorar, detectar e responder incidentes de segurança. No que diz respeito a tríade CID, para além da Confidencialidade e Integridade, a Disponibilidade de determinados ativos ou serviços podem ser interpretados como incidentes de segurança críticos como, por exemplo, a indisponibilidade de um SIEM (Gerenciamento e Correlação de Eventos de Segurança). Desta forma, faz-se necessário que os times responsáveis sejam acionados com assertividade e eficácia para o restabelecimento dos sistemas.
O desafio de monitorar topologias complexas, heterogêneas e distribuídas requer uma análise minuciosa dos possíveis cenários de falha, assim como é crucial que os alertas sejam confiáveis. Nessa perspectiva, se mais de 10% do total dos alertas forem falsos positivos, os usuários tendem a não confiar na monitoração (NICOLA MAURI, 2020). Outro fenômeno indesejado é a inundação de alertas, pois se o canal principal de recebimento dos alertas acionáveis sofrer inundação, os times de Incident Handling ou de Plataforma podem não identificar os incidentes verdadeiros (SUNDARAMURTHY, 2014) e, na concepção de um SOC, estes são os piores cenários.
Objetivo
Este artigo tem como objetivo apresentar métodos de correlação e inteligência das métricas e condicionais dos alertas com intuito de reduzir os falsos positivos, mitigar inundações de alertas, bem como acionar as equipes específicas que são responsáveis por restabelecer os sistemas, sob a perspectiva de um SOC.
Ambiente
Este artigo apresenta um laboratório composto por um Zabbix Server e um host alvo da monitoração, com o intuito de simular alguns problemas recorrentes de um SOC. Para isso, foi utilizado o VirtualBox como hypervisor na versão 6.1.38, a fim de criar duas máquinas virtuais (VMs, do inglês Virtual Machines) para representar os ativos supracitados.
Ambas as máquinas utilizam sistemas operacionais baseados no Red Hat Enterprise Linux (RHEL based) por trazer maior proximidade com o cenário real de monitoração do SOC. Ademais, as VMs estão com as placas de rede em modo bridge para que possam fazer parte da rede local.
Host alvo da monitoração: Utiliza o sistema operacional CentOS 7.9, com serviço o Zabbix Agent 2 instalado na versão 5.0.21.
Zabbix Server: Serviço na versão 6.0.12 com sistema operacional Oracle Linux na versão 8.5.
Fluxo básico dos alertas Zabbix em um SOC
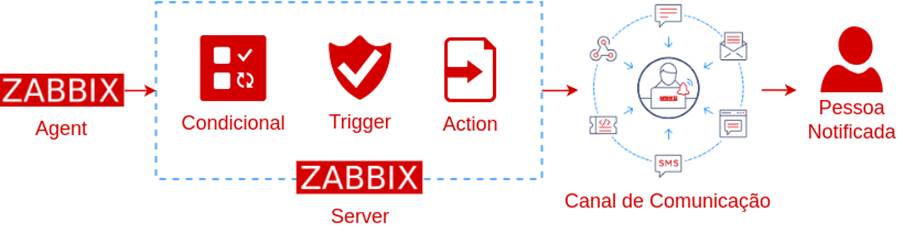
O Zabbix Agent (ou somente Agent) é responsável por coletar informações sobre o sistema a ser monitorado, como: CPU, memória, uso de disco, informações e disponibilidade de serviços etc. Já o Zabbix Server (ou somente Server) é responsável por receber e armazenar as informações coletadas pelo agente e outros dispositivos de monitoramento, como SNMP, JMX e IPMI. A porta padrão de serviço é a 10050.
O Server processa as informações coletadas através de condicionais das triggers (ou gatilhos) que, quando atendidas, podem gerar ações (actions) como notificar os stakeholders. As triggers são expressões lógicas que possuem condições para detectar cenários não desejados.
Para este artigo, quando uma trigger for ativada, o Server tomará a ação de notificar a equipe responsável por restabelecer a disponibilidade do cenário em questão.
Técnicas para redução de falsos positivos e inundações de alertas
O conceito de falso positivo para atuação de um SOC diz respeito à confiabilidade plena do alerta, descartando intermitências. Assim, deve-se criar lógicas de alertas que filtrem flutuações e interrupções passageiras da grandeza a ser monitorada, pois, conforme mencionado, os falsos positivos prejudicam a reputação do sistema de monitoramento quando interfere na confiabilidade dos alertas ao mesmo tempo que as tempestades de notificações interferem na visibilidade de problemas reais. Assim, serão demonstradas algumas técnicas eficazes para mitigar esses problemas no Zabbix.
Triggers com técnicas de anti-flapping
Primeiramente, vamos analisar uma trigger simples:
last(/CentOS/vm.memory.size[pused])>95
Bloco 1 – Trigger de exemplo.
- “last”: Função utilizada pela expressão. Considera a última (last) informação coletada.
- “CentOS”: Nome do host monitorado.
- memory.size[pused]”: Nome do objeto (item) a ser monitorado. Neste caso será o percentual de memória utilizada (pused: percentage used).
- “>95”: Indica a condição que deve ser satisfeita para que a trigger seja ativada, ou seja, quando o uso de memória utilizada em percentual for maior que 95%.
Desse modo, a trigger irá gerar um alerta no momento em que o último valor coletado do uso de memória no host CentOS ultrapassar 95%.
Existem diversas outras maneiras de analisar métricas para itens de interesse. Com base no exemplo anterior, observe as seguintes triggers no Bloco 2:
# SMTP indisponível last(/Host/net.tcp.service[tcp,,25])=0 # Serviço de SSH indisponível last(/LinuxMachine/net.tcp.service[tcp,,22])=0 # Zabbix Agent indisponível last(/ZabbixAgentHost/net.tcp.service[tcp,,10050])=0
Bloco 2 – Outras triggers de exemplo.
Você consegue identificar algum problema nessa estratégia de monitoramento? Pense bem. É comum que alguns serviços passem por oscilações ou problemas isolados por curtos períodos de tempo. Por exemplo, imagine que o serviço responsável pelo envio de e-mail ficou indisponível por cerca de quatro minutos devido à uma oscilação temporária na rede. Dessa forma, se estivéssemos monitorando a cada minuto, teríamos quatro alertas de indisponibilidade desnecessários (falsos positivos).
No contexto de monitoramento de redes, o termo flapping é utilizado para se referir a uma oscilação rápida e frequente do estado de um item monitorado e, por isso, técnicas de anti-flapping são utilizadas para evitar geração excessiva de notificações durante essas oscilações.
A técnica é simples: basta impor um período de espera baseado no comportamento histórico do objeto a ser monitorado. Normalmente, considera-se a média dos eventos de indisponibilidade mais seu desvio padrão, para caso o problema persista por um tempo, a fim de se evitar os falsos positivos. Esta escolha deve considerar a criticidade do ambiente, a severidade da indisponibilidade para os stakeholders e seu impacto a partir de uma matriz de risco.
Cenário 1: Anti-flapping.
Para simular o cenário de oscilação, foi criado um script em Python para desabilitar os serviços SSH, SMTP e Zabbix Agent durante intervalos aleatórios de no máximo 75 segundos. Após esse tempo, o programa reabilita os serviços por 45 segundos – tempo suficiente para o Zabbix detectar o restabelecimento dos serviços – e, por fim, repete todos os passos anteriores mais 4 vezes para provocar mais oscilações. Observe a quantidade de alertas gerados e os seus tempos de duração na Figura 2.

Isso ocorre porque a função last() utiliza o último valor coletado. Nesse contexto, assim que os serviços pararam, diversos alertas com o tempo de duração categoricamente curtos foram gerados, o que, por sua vez, caracteriza os falsos positivos. A solução proposta para corrigir esse problema foi realizada em dois passos:
Passo 1: Realização de análise para verificar o tempo de duração médio mais seu desvio padrão das oscilações no serviço e determinar um tempo de espera dentro de um cenário de baixo risco.
Passo 2: Implementação das técnicas de anti-flapping para modificar as expressões com a utilização de uma nova função: max().
Dessa maneira, as triggers ficaram estruturadas conforme a Figura 3.

A função max() irá retornar qual é o valor máximo coletado em um intervalo de tempo especificado, que no exemplo atual é de dez minutos. Já o igual a zero (=0) é a condição de disparo da trigger, que será disparada se o valor máximo, de todas as coletas, dentro dos últimos dez minutos for igual a zero. Em outras palavras: se cada serviço ficar impreterivelmente indisponível por dez minutos, o alerta será gerado.
O intervalo de dez minutos para a simulação em laboratório foi escolhido com base em critérios de um cenário real de um SOC. O diálogo entre o time que administra o Zabbix e o time responsável por restabelecer cada indisponibilidade é um fator importante para a monitoração, posto que o serviço pode ter alguma especificidade que precise de um intervalo menor ou até mesmo maior dada cada circunstância e contextos específicos.
As oscilações temporárias foram mapeadas e armazenadas pelo Zabbix conforme visto na Figura 4, contudo, após a aplicação das técnicas de anti-flapping não houveram mais falsos positivos no laboratório conforme visto na Figura 5.
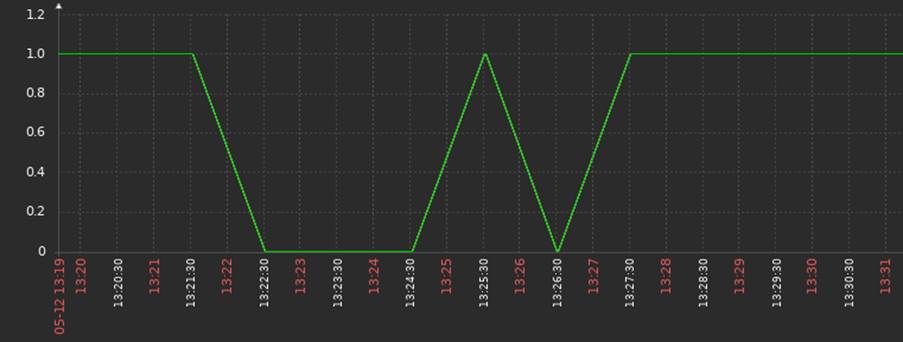
Portanto, a operação do SOC permaneceu com visibilidade das oscilações a fins de auditoria e sem qualquer característica de inundações ou falso positivos sob a perspectiva das métricas implementadas.
Correlação de lógicas para categorizar os problemas de disponibilidade
O Zabbix oferece o objeto (item) agent.ping que auxilia na monitoração da disponibilidade da resposta do serviço do Agent: caso esteja disponível retorna um e caso não esteja não retorna nada, diferente da monitoração por ICMP (do inglês Internet Control Message Protocol) que retorna suas clássicas mensagens de erro (POSTEL, 1981).
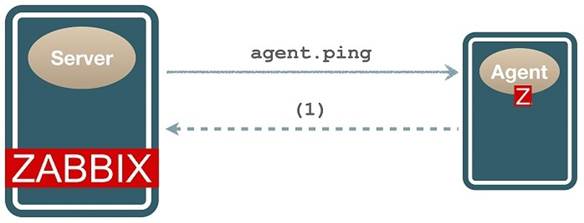
Ou seja, em um cenário em que o Agent pare de funcionar não haverá nenhum dado a ser coletado pelo Server, resultando numa lacuna no histórico da monitoração. Uma possível solução para identificar esta indisponibilidade do serviço é utilizar uma função que observa quando nenhum dado foi coletado em uma certa janela de tempo: a nodata().
Às vezes as condições lógicas ficam difíceis de serem compreendidas. O comportamento da função nodata() pode ser um pouco confuso à primeira vista por ser uma função de negação, por isso se faz importante salientar que:
- nodata()=1 indica que não houveram dados recebidos no período determinado, no caso, não houveram dados por 3 minutos.
- nodata()=0 indica que houveram dados recebidos no período determinado, logo, a trigger não dispara.
Logo, internalize a seguinte forma: nodata()=1 pode ser lido como “não houveram dados neste período = isso é verdadeiro”.
A utilização da função nodata() atrelada ao agent.ping identifica uma provável indisponibilidade do host, porém pode ser somente um problema no serviço do Agent ou até mesmo uma indisponibilidade de rede. Desta forma, identificar a causa raiz da indisponibilidade oferece assertividade em acionar a equipe adequada para resolver o problema em um SOC.
Os recursos de ping (ICMP) e verificação de disponibilidade da porta de um serviço são comumente utilizados em medições de rede. Desta forma, podemos correlacionar as lógicas para determinar com assertividade qual a maior probabilidade de uma causa raiz, conforme visto na Tabela 1:
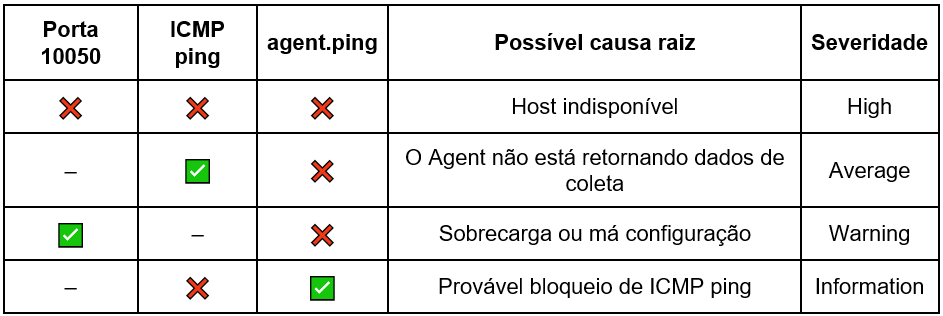
Vale salientar que se a porta de serviço está ativa (10050) e o agent.ping não, temos uma anomalia, uma anormalidade, um comportamento inesperado. O que pode ser gerado por cenários diversos, tais como: sobrecarga do serviço, do sistema operacional, congelamento / crash do Agent, ou até mesmo má configuração nas regras de firewall ou do próprio Agent. De maneira simplificada, vamos assumir a situação de “Sobrecarga ou má configuração”.
Após determinar a origem do problema, torna-se possível direcionar de maneira mais confiável os alertas para os times corretos, conforme a Tabela 2.
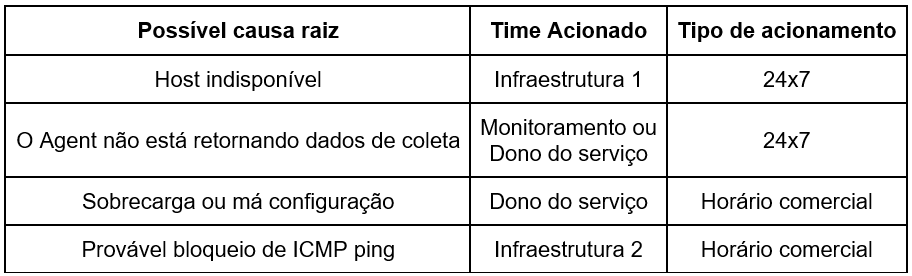
Quando o time correto é acionado, ganha-se na agilidade operacional como um todo e, desta forma, se faz necessário correlacionar os eventos para aferir a possível causa raiz de maneira apropriada.
Cenário 2: Correlação
Neste cenário será demonstrado o funcionamento da correlação de triggers a partir do recurso de trigger dependente com associação entre métricas. As novas triggers serão um pouco mais complexas quando comparadas com o Cenário 1 (anti-flapping).
Serão abordadas associações entre ICMP ping com agent.ping e verificação da porta de serviço com agent.ping. Essas associações a partir da lógica booleana AND com a utilização de dependência das triggers são suficientes para aferir as possíveis causas raízes supracitadas.
- Trigger composta por ICMP Ping e agent.ping
max(/CentOS/icmpping,5m)=0 and nodata(/CentOS/agent.ping,5m)=1
Bloco 3: Trigger que cruza ICMP ping com agent.ping.
Esta trigger verifica se o host não está respondendo a ICMP Ping e se o Agent não está retornando dados de coletas, ambos por mais de cinco minutos. Caso as duas condições sejam satisfeitas, o alerta para a causa raiz de host indisponível será disparado.
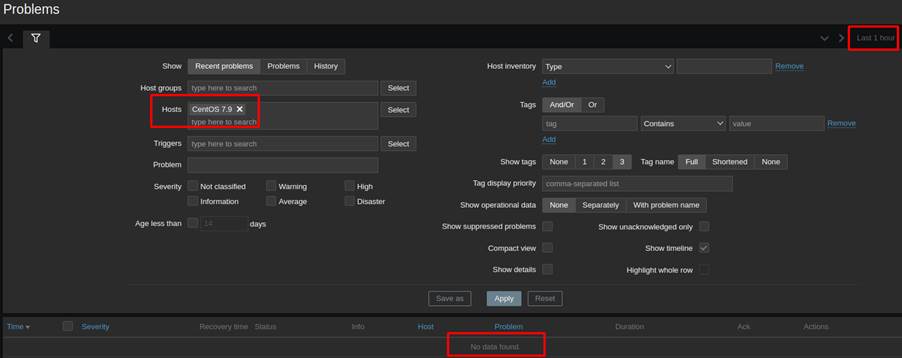
Para simular o cenário de host indisponível, a conexão com a internet do host foi desabilitada gerando uma indisponibilidade de rede, conforme visto na Figura 9.
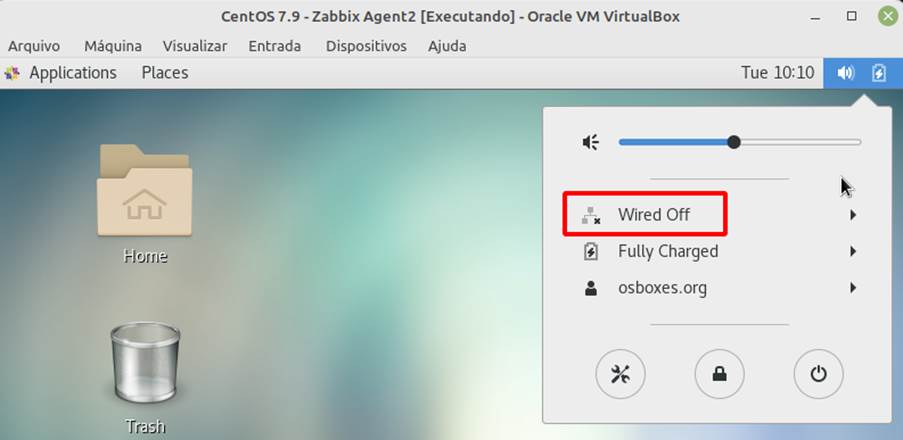
Logo, a trigger foi disparada no Zabbix, indicando a indisponibilidade do host conforme mostra a Figura 8.

2. Trigger de agent.ping configurada como dependente da anterior.
Uma nova trigger então é configurada para detectar quando somente o Agent não esteja retornando dados de coleta por mais de dez minutos. Perceba que esta condição é parte da trigger anterior (Bloco 3).
nodata(/CentOS/agent.ping,10m)=1
Bloco 4: Trigger para detectar a não coleta de dados do Agent
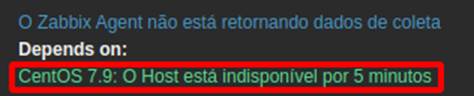
Desta forma, para que a causa raiz possa ser devidamente aferida, se faz necessário implementar o recurso de dependência de triggers. A configuração é simples e deve ser consultada na documentação oficial [1]. A Figura 9 mostra a dependência da trigger “O Agent não está retornando dados de coleta” com “O Host está indisponível”. É importante ressaltar que quando uma trigger depende da outra, se faz necessário dimensionar apropriadamente o tempo de cada uma para que a correlação seja efetiva.
Para além de aferir a causa raiz, a dependência de triggers também evita alertas duplicados. Funciona da seguinte forma: se a trigger de “Host indisponível” estiver sendo disparada, a trigger dependente não irá disparar. Com isso, estamos dizendo para o Zabbix que se o host está indisponível, naturalmente o serviço do Zabbix Agent também estará, logo não serão necessários dois alertas para tratamento do SOC.
Para replicar este cenário, o serviço do Agent foi desabilitado conforme Figura 10.
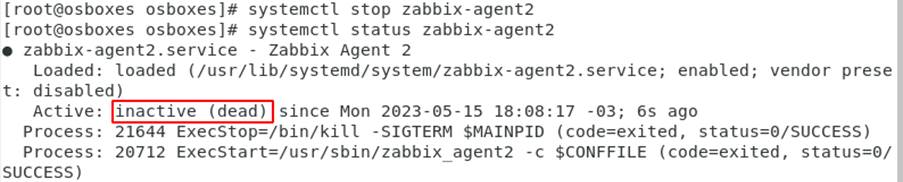
Após dez minutos o alerta foi gerado, com a possível causa raiz identificada apropriadamente, conforme Figura 11.

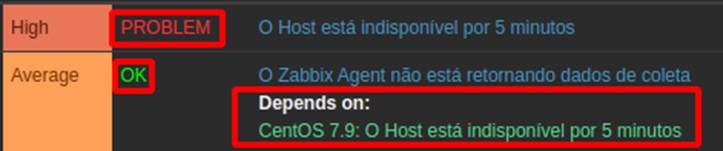
Além disso, a dependência também está funcionando corretamente, conforme evidencia na Figura 12, que mostra a trigger de host indisponível no estado de problema e a que identifica a ausência de dados de coleta permanece como “ok”.
O próximo cenário de correlação identifica quando a porta do serviço (10050) estiver ativa e o Agent não estiver comunicando, configurando assim um possível cenário de sobrecarga ou má configuração.
3. Trigger “O Zabbix Agent está indisponível devido à uma sobrecarga no sistema ou má configuração”
O Bloco 5 mostra a trigger para identificar um possível problema de travamento ou má configuração no Agent ao monitorar se tanto a porta de serviço (10050/TCP) e o retorno de dados de coleta do Agent não estiverem ativos.
max(/CentOS/net.tcp.service[tcp,,10050],5m)=1 and nodata(/CentOS/agent.ping,5m)=1
Bloco 5: Trigger para detectar problemas de sobrecarga ou má configuração do agent
O item net.tcp.service[tcp,,10050] coleta o status da porta do serviço por checagem simples (simple check, estilo telnet, netcat, etc.) ao invés de utilizar o recurso de verificação de porta do próprio Agent. Isso garante a coleta da informação por outro canal pois, obviamente, caso o Agent não esteja funcionando adequadamente a informação da porta de serviço não será retornada.
Para que o Agent possa mandar as informações para o Zabbix Server, é necessário adicionar o IP deste no arquivo de configuração do serviço. Desse modo, para simular um cenário de ativação desta trigger, um IP incorreto foi adicionado no arquivo de configuração do Zabbix Agent e, dessa forma, a trigger foi disparada conforme Figura 13.

E de forma análoga ao caso anterior, a trigger “O Zabbix Agent não está retornando dados de coletas” precisa ser dependente desta para evitar alertas duplicados.

Deste modo, temos a correlação entre três itens diferentes para identificar três possíveis causas raízes distintas e as lógicas apresentadas contêm todas as técnicas explicadas do decorrer deste artigo:
- Anti-flapping para evitar inundação de alertas, quando há diversas oscilações, para diminuir os falsos positivos e melhorar a confiabilidade da monitoração;
- Correlação com expressões que identificam a possível causa raiz dos alertas para acionar os times responsáveis por resolver os problemas;
- Dependência de triggers para evitar alertas duplicados e acionamentos desnecessários.
Conclusão
Este artigo apresentou a importância da mitigação de falsos positivos e inundação de alertas para que um SOC possa funcionar com confiabilidade em sua monitoração e seus acionamentos. Desse modo, foram demonstrados cenários adversos e comuns da operação através de um laboratório com exploração das técnicas de anti-flapping e correlação com dependências.
A redução de falsos positivos e acionamentos indevidos evita prejuízos financeiros para as partes envolvidas. Para além dos custos trabalhistas, uma monitoração deficitária pode provocar quebras de SLA (do inglês: Service Level Agreement), uma maior exposição a ataques cibernéticos e, até mesmo, um cenário no qual um incidente aconteça e não possa ser detectado ou respondido.
Os ganhos com assertividade e acionamento dos times apropriados contribui para a melhoria de indicadores de desempenho como MTTA (do inglês, Mean Time To Acknowledge) e MTTR (do inglês, Mean Time To Respond) que são, respectivamente, tempo médio para a confirmação e resposta de um incidente, resultando assim em uma melhoria substancial na segurança do sistema de monitoramento e do SOC como um todo.
Referências
LONTONS, Arturs. Handy Tips #19: Preventing alert storms with trigger dependencies. Disponível em: <https://blog.zabbix.com/handy-tips-19-preventing-alert-storms-with-trigger-dependencies/18696/>. Acesso em: 05 jan 2023.
MAURI, Nicola. Fighting notification floods and misleading alerts in distributed Zabbix deployments. Disponível em: <https://blog.zabbix.com/fighting-notification-floods-and-misleading-alerts-in-distributed-zabbix-deployments/11600/#:~:text=False>. Acesso em: 14 jan 2023.
POSTEL, Jon. RFC 792 – Internet Control Message Protocol. 1981. Disponível em <https://datatracker.ietf.org/doc/html/rfc792> D
Secure Users & Access. Disponível em: <https://www.checkpoint.com/cyber-hub/threat-prevention/>. Acesso em: 19 maio 2023.
SUNDARAMURTHY, Sathya Chandran et al. A tale of three security operation centers. In: Proceedings of the 2014 ACM workshop on security information workers. 2014. p. 43-50.
VLADISHEV, Alexei. No more flapping. Define triggers the smart way. Disponível em: <https://blog.zabbix.com/no-more-flapping-define-triggers-the-smart-way/1488/>. Acesso em: 11 fev 2023.
WUTZL, Eduardo. [Noc] Chuva de Alertas, qual Remédio? Disponível em: <https://pt.linkedin.com/pulse/noc-chuva-de-alertas-qual-rem%C3%A9dio-eduardo-wutzl>. Acesso em: 13 jan 2023.
Zabbix Manual. Disponível em: <https://www.zabbix.com/documentation/6.0/en/manual>. Acesso em: 26 mar 2023.