As already brought by Gabi and Vinícius, this is another result of research developed during the Tempest internship program. For those who still don’t know, during this program, we went through modules and, at the end, we should carry out a research project on some topic that we consider interesting, and viable, to be learned and presented in one month. I had a lot of difficulty in choosing what the hell I would like to do as my research. A lot of cool stuff to learn, a universe of possibilities; adding to that, a little insecurity. How could I, an intern with only 4 months of experience in the area of information security, learn about something in a month to share with my co-workers, who were already working in the area while I was still watching teletubbies and eating sand?
After a few sleepless nights, by nightmares with this blessed research, a lot of procrastination and exchange of themes, I came to the final decision with the suggestion of my dear director Fofão, who became my research advisor and this is what we will “talk” about today.
Nowadays there are several frameworks and libraries that greatly speed up software development, facilitating coding, making work faster and creating layers of abstraction. But not everything are flowers. Would we be giving up security for [ease|performance|convenience]? Under which conditions should I include third party libraries, and which third party libraries? This is a long and complex discussion that is beyond the scope of this blogpost. Anyone who wants to read a bit about this reflection, has a blogpost from Cheng, our head of software engineering, right here on SideChannel in which he talks a bit about these “magic” libraries and frameworks.
But then what is this blogpost about? This article is about a brief evaluation of a set of libraries that allow the conversion of HTML code to PDF. Our goal here was to investigate what kind of vulnerabilities can be inserted in a software through the use of libraries with the above mentioned functionality, and thus answer the question: “can you hack HTML to PDF converters? Let’s see…
What should we evaluate?
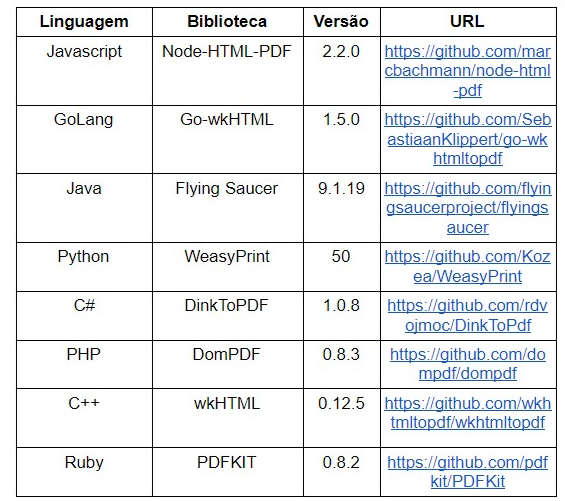
Before going crazy making fuzz and reporting the findings, I had to exercise patience and determine what the scope of my research would be. The first step was to choose which libraries I would test. I ended up choosing 8 libraries according to the following criteria: it must be an open source, be widely used (by the amount of stars in Github and references in StackOverflow) and limit the choice to only one library per programming language. With this, we arrive at the following list of libraries:
Tests Environment
Once I defined the libraries to be evaluated, I needed to create a test environment. As seen, 8 libraries were selected each in a different programming language. Some libraries are very simple and intuitive (some even have a command-line interface, very easy to use) when performing the setup; while others are more boring. In the end, it was more difficult to set up the environment. As the idea was to have the libraries running in the same environment, we used a standard image running a Xubuntu 18.04 linux, except in the case of DinkToPDF, which was run on a Windows 10 given the need to have the .Net framework.
How to evaluate?
Knowing what to evaluate, and having the environment already configured, the next step was to define how to evaluate.
We then made a list of questions (hypotheses) to be answered against each of the listed libraries. The questions were the following:
#1A — Does the library allow Javascript code execution?
Evaluating whether the library allows Javascript to be executed during the conversion of HTML to PDF is possibly the most interesting question of all we perform in this work. This is because Javascript, unlike HTML, is a programming language, which makes it possible to ask 6 other questions: 1B, 1C, 1D, 1E, 3A and 4A.
Hypothesis Validation
To validate the hypothesis that the “library allows Javascript execution” we use a Javascript code that, if executed, changes the value of a div to “The javascript was executed” (string A). If the hypothesis is false, the value of the div will be “The javascript was not executed” (string B). With this, it was enough to check the PDF generated in search of the string A or the string B.
Here is the HTML/Javascript code:
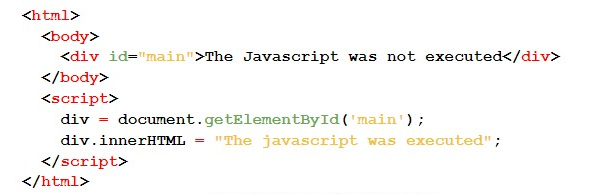
Result #1A
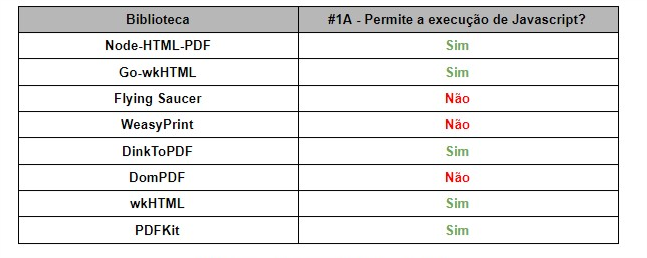
Among the 8 libraries evaluated, 5 allow Javascript execution. Below follows the summary:
#1B — Does it allow by default the execution of Javascript code?
In these cases, allowing Javascript execution can lead to some security problems, especially if the developers are not aware of this behavior. However, if Javascript execution does not occur by default in the library, the risk of the developer making a nonsense decreases, hence the motivation for this question.
Among the 5 libraries that allow Javascript execution, all do it by default. To assume that such behavior is a vulnerability would be to force the bar a little; but, without a doubt, this behavior can be seen as a bad security practice.
#1C — Is it possible to disable Javascript code execution?
As seen in question #1B, all 5 libraries that allow Javascript execution do so by default, but which ones allow the developer to disable Javascript execution? Only wkHTML. The other 4 simply do not have the option to disable Javascript execution.
Is it possible to perform a denial of service (DoS)?
There are several ways to try to do a DoS on the server, but the idea we followed in this work was to try to “hold” the Javascript execution. This situation makes us reflect the following: depending on how the library is used, would stopping that execution make a denial of service possible? Well, it turns out to be difficult to affirm for all situations; thus, it is up to the reader to perform his own tests in applications under audit.
And, besides that, another aspect emerges to be considered in this DoS attempt: how could we interrupt this execution? To do so, we use two approaches here in the attempt to answer the question:
#1D — check if it is possible to use the Javascript sleep() function, and;
#1E — check if an infinite loop can be performed.
The Javascript code used to put the server “to sleep” (sleep function) was as follows:

The Javascript code used to loop the server was as follows:

Therefore, it was possible to verify that:
- The use of the sleep() function did not work in all libraries;
- The infinite loop worked in all libraries that run Javascript code.
I confess that I had some doubts about the results of this hypothesis, so I asked my dear colleagues for help.
Basically, I asked them if they had ever been able to do a DoS in any project using the ideas mentioned above. I was informed by my noble colleagues that rare are the projects in which we test DoS; and that they never managed to do a DoS in this scenario using the sleep function. However, I have received reports that the use of the infinite loop has already worked in some cases, but not in most. It was not possible to find out in which libraries we were able to do DoS in real tests, which is a shame. I also believe that the success of this attack depends on how the application is architected and coded. We leave this problem open, as a research suggestion for those who want to venture into the continuity of this analysis.
#2A — Is it possible to make requests on the server side (SSRF)?
As the library is probably running on a server, is it possible to have this server perform requests during the file conversion process? To corroborate this hypothesis, the conversion of a file containing the following HTML code was performed:

By analyzing the results obtained from the file conversion process, the generated PDF presented the web page in question within the iframe, thus proving that this library is vulnerable to Server Side Request Forgery — SSRF attacks.
#3A — Is there a requisition limit?
But what if there is still the following question: does the library limit the number of requests that can be made? Well, this could mitigate an attack using SSRF and/or DoS vulnerabilities. To verify this, 200 requests were made to a server in my control. If the library were to bar those requests, we would verify that there is a mechanism that limits the number of requests made. Below is the code used:
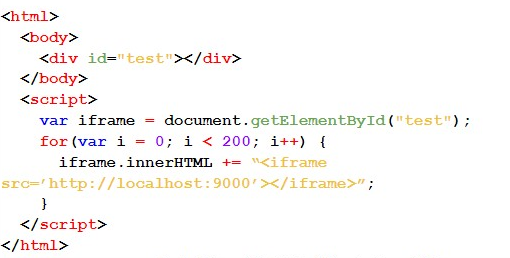
In this case, all 200 requisitions were made without problems, proving that the library does not limit the number of requisitions made.
Is it possible to read arbitrary files?
Since the library is running on a server, could we read files arbitrarily on this server during the conversion process?
In an attempt to answer this question, we use different methods to try to read the notorious passwd file arbitrarily.
#4A — In the first test case, we use the XMLHttpRequest object. Next, we present the code used:
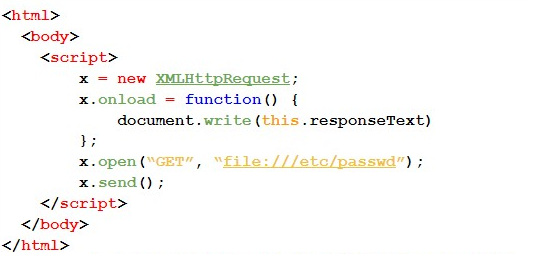
#4B — For this case, we use the iframe tag.

#4C — The following test makes use of the Object tag, as shown by the code below:
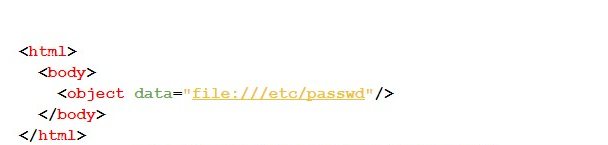
#4D — Finally, the following code displays the test case using the Portal tag:

As a consequence of the tests performed, when trying to access the passwd file located in the folder etc., we proved that it is possible to read files in an arbitrary way, because the PDF generated contained the information from the aforementioned file.
Results
Below is a table showing the tests performed for each library, and their respective results: being true for those libraries that had a positive result in the generated PDF (i.e., that are vulnerable); false for those that had a negative result; and n/a if the test is not applied.

Of the 8 libraries tested, Flying Saucer, WeasyPrint and DomPDF did not allow Javascript code to be executed; and only the wkHTML library allowed Javascript to be disabled.
The NODE-HTML-PDF, go-wkHTML, DinkToPDF, wkHTML and PDFKIT libraries that allowed the use of Javascript, did so by default. Furthermore, they allowed infinite loop, loading of external content and access to files via XMLHttpRequest; thus being vulnerable to Denial of Service (DoS), Server-side request forgery (SSRF) and Arbitrary File Read attacks, respectively.
Although the DomPDF Library has not been vulnerable to the test cases applied in this research, it has some CVE (Common Vulnerabilities and Exposures) known and reported in its own documentation. It is worth noting that, among the libraries tested, this was the only one that provided security recommendations in its documentation (https://github.com/dompdf/dompdf/wiki/Securing-dompdf).
“Great! What a bomb! And I’m using some of these libraries… and now, how do I protect myself?”
Security Recommendations
Since one of the goals of Tempest is to contribute to a safer digital world, we couldn’t help but talk about how to protect ourselves, could we? So, here are some recommendations:
● Perform validation and filtering of data received by the user that will be converted from HTML to PDF;
● Use Sandbox to restrict access and library permissions;
● If it is not necessary, and the library allows, disable Javascript execution;
● Keep the library updated.
Well, this was my research project for the Tempest internship program. I hope it contributed in some way to your knowledge as well as it contributed to mine. I would like to leave my thanks to everyone who helped me in some way in this research, especially Jodinho. Thanks a lot!
If you have any questions or suggestions, please send them to me!
References
https://www.noob.ninja/2017/11/local-file-read-via-xss-in-dynamically.html
https://www.virtuesecurity.com/kb/wkhtmltopdf-file-inclusion-vulnerability-2/
https://securityonline.info/export-injection-new-server-side-vulnerability/