Por Enzo Ferrari
A Ascensão do REST
O estilo de arquitetura de software REST (Representational State Transfer) foi criado por Roy Fielding em sua tese de doutorado, onde, resumidamente, ele sugere um protocolo stateless de comunicação do tipo cliente/servidor. Dessa forma, ocorre uma separação de responsabilidades: o cliente não precisando se preocupar com o que ocorre do lado do servidor, bem como o servidor também não precisando se preocupar com o que ocorre do lado do cliente. Em conjunto, foram definidas as operações que poderiam ser feitas através do protocolo, sendo elas: POST, PUT, GET e DELETE; cada uma delas apresentando uma função única e bem específica.
Os paradigmas sugeridos pelo padrão REST foram vistos com bons olhos pela comunidade de desenvolvedores, o que acabou conferindo ao REST o status de protocolo padrão para Web APIs modernas.
Os gargalos do REST
Devido ao boom no mercado de tecnologia após os anos 2000, o protocolo REST já exibia alguns gargalos, que ficaram evidentes principalmente após a integração de dispositivos móveis no ecossistema de desenvolvimento mainstream a partir de 2007.
Imaginemos o seguinte cenário: precisamos servir uma API REST para tipos diferentes de clientes, como outros backends, aplicações web e aplicações mobile. O cliente de backend conta com uma velocidade de transferência de dados abundante, de modo que precisa de mais dados para processamento de analytics e treinamento de modelos de machine learning. Já o cliente web precisa somente dos dados a serem exibidos ao usuário e para telemetria; nesse cenário, a velocidade de transferência é limitada, pois os usuários estão ao redor do mundo, com variadas ISPs (Internet Service Providers). Por fim, o cliente mobile conta com uma velocidade de transferência que pode ser bem menor, pois pode estar numa rede GSM, 3G, HSPA, etc. Aqui, também existe preocupação quanto à velocidade do hardware, visto que essa pode ser bastante limitada quando comparada a um desktop. É sempre importante pensar em usos que prolonguem a duração da bateria do telefone.
Frente a esses cenários, a solução a ser implementada através do REST pode se tornar bastante redundante, com rotas específicas para cada cliente e até inconsistências entre os três tipos de cliente. Além disso, pode ser necessário dividir esse serviço REST entre as plataformas, sendo assim, um mesmo cliente com os três cenários precisará que seus dados sejam atualizados, documentados e testados, conforme demanda, em três locais diferentes, concomitantemente.
Criando uma alternativa
O cenário exposto acima aconteceu com o time do Facebook em 2012, e os motivou a procurar uma solução para esse desafio. Assim, surgiu o GraphQL. Toda a noção de rotas, operações de POST, PUT, GET e DELETE foi deixada de lado, sendo substituída pela noção de queries e mutations. Como os nomes explicitam, as queries são utilizadas para pedir dados, enquanto as mutations têm como objetivo a criação ou alteração de dados no servidor. Apesar de ainda ser stateless, o GraphQL acaba por transferir um pouco da responsabilidade do servidor ao cliente, visto que agora todos os dados devem ser requisitados de forma declarativa pelo cliente.
Assim, chamadas para endpoints REST variados podem ser substituídas por uma única query a um endpoint GraphQL. É possível também filtrar dados desnecessários, prevenindo o over-fetching, que seria um problema principalmente para clientes mobile.
REST vs GraphQL
Supondo a necessidade de acessar o nome de um desenvolvedor, junto ao nome de seus repositórios públicos, foram feitas as seguintes chamadas à API REST do GitHub:
curl -i https://api.github.com/users/ferrarienz0
HTTP/2 200
server: GitHub.com
...
{
"login": "ferrarienz0",
...
"repos_url": "https://api.github.com/users/ferrarienz0/repos",
"type": "User",
"site_admin": false,
"name": "Enzo Ferrari",
"company": “AllowMe - Intelligence By Tempest”,
...
}
Se quisermos visualizar os repositórios do usuário ferrarienz0, devemos fazer uma nova requisição ao endpoint especificado na propriedade “repos_url”.
curl -i https://api.github.com/users/ferrarienz0/repos
HTTP/2 200
server: GitHub.com
[
{
"id": 354568895,
"node_id": "MDEwOlJlcG9zaXRvcnkzNTQ1Njg4OTU=",
"name": "50sec",
"full_name": "ferrarienz0/50sec",
"private": false,
...
}
...
]
Para ter acesso ao nome do desenvolvedor e ao nome de seus repositórios, foram necessárias duas chamadas a dois endpoints distintos. Além disso, foi retornada uma quantidade massiva de dados desnecessários à situação suposta (aqui você pode realizar essas chamadas, principalmente a segunda, e ver por si mesmo).
Para o mesmo caso, podemos utilizar a API GraphQL do GitHub, assim a query seria:
query {
user(login: "ferrarienz0") {
name
repositories(first: 5, privacy: PUBLIC) {
nodes {
nameWithOwner
}
}
}
}
E retornaria:
{
"data": {
"user": {
"name": "Enzo Ferrari",
"repositories": {
"nodes": [
{
"nameWithOwner": "ferrarienz0/VSOverflow"
},
...
]
}
}
}
}
Ou seja, exatamente o que declaramos na query. Não houveram múltiplas chamadas ou over-fetching. Você pode testar essa query no explorer da API GraphQL do GitHub.
Nem tudo são flores
Apesar de resolver os problemas explicitados acima, o GraphQL traz outros desafios, como a complexidade de ser implementado. O desenvolvedor deve lidar com diversas formas de fazer queries à base de dados e construir o schema do GraphQL. O que pode ser exaustivo, levando em consideração a quantidade de recursos a serem expostos pela API. É preciso lidar também com queries potencialmente perigosas, visto que a forma como o schema é criado pode deixá-lo aberto a queries recursivas, que demandam muito processamento e podem ocasionar um DoS (Denial of Service).
Exemplo de query recursiva:
query {
repositories {
name
contributors {
name
repositories {
name
contributors {
repositories {
...
}
}
}
}
}
}
Além disso, existe uma curva de aprendizado maior para um desenvolvedor lidar com GraphQL que com REST, devido ao adicional de complexidade que as novas possibilidades trazem. Por fim, o armazenamento em cache é mais simples no REST, precisando de um esforço maior para atingir resultados semelhantes no GraphQL.
Hasura
O Hasura surge para contornar essa complexidade de desenvolvimento como um serviço open-source, que permite gerar API’s GraphQL a partir de um banco de dados SQL Server ou Postgres, sem que o desenvolvedor precise criar e manter esse servidor.
Dentre as vantagens estão:
- Cache integrado;
- Escolha de tabelas a serem rastreadas por demanda;
- Baixa latência;
- Simplicidade de configuração.
Pré-Requisitos
Configurando os serviços – Postgres
É possível já subir um container postgres com o Hasura configurado através do arquivo docker-compose que pode ser acessado aqui. No entanto, para fins de demonstração, vamos configurar o Hasura e o conectar ao postgres somente quando finalizarmos a configuração do banco de dados. Para subir um banco de dados postgres, utilizaremos o docker.
docker run --name hasura-postgres \ -e POSTGRES_USER=tempest \ -e POSTGRES_PASSWORD=password \ -d postgres
Agora precisamos criar o nosso schema para o banco de dados. Criaremos um schema bem simples, uma tabela de usuários e outra de posts, de modo que cada post deve pertencer a um usuário.
Para acessar a CLI do postgres através do docker:
docker exec -it hasura-postgres psql -U tempest
Criaremos um banco de dados com nome hasura_app:
CREATE DATABASE hasura_app;
Podemos então conectar ao banco de dados criado e criar o nosso schema.
// Conectar ao db hasura_app \c hasura_app; // Criar tabela de usuários CREATE TABLE users ( id serial PRIMARY KEY, username VARCHAR(12) UNIQUE NOT NULL, password VARCHAR(50) NOT NULL, email VARCHAR(100) NOT NULL ); // Criar tabela de posts CREATE TABLE posts ( id serial PRIMARY KEY, user_id INT NOT NULL, content TEXT NOT NULL, FOREIGN KEY (user_id) REFERENCES users (id) );
Por fim, para fins de teste, vamos popular as tabelas do nosso banco de dados.
// Users
INSERT INTO users (username, password, email) VALUES ('tempest', 'password', '[email protected]'),
('allowme', 'password2', '[email protected]');
// Posts
INSERT INTO posts (user_id, content) VALUES
(1, 'A Tempest possui o portfólio mais completo em cibersegurança no Brasil.'),
(2, 'Seu ambiente digital mais simples e seguro.');
Agora o nosso banco de dados está pronto =D. Para desconectar da CLI:
\q
Para conectar nosso container postgres ao container hasura que será criado, precisaremos de uma network:
// Criando a network para conectar postgres e hasura docker network create -d bridge hasura-network // Conectando o container do postgres à rede docker network connect hasura-network hasura-postgres
Configurando os serviços – Hasura
Podemos criar o container hasura já conectado à netwok.
docker run --name hasura \ -p 8080:8080 \ -itd --network=hasura-network \ -e HASURA_GRAPHQL_DATABASE_URL=postgres://tempest:password@hasura-postgres:5432/hasura_app \ -e HASURA_GRAPHQL_ENABLE_CONSOLE=false \ hasura/graphql-engine:v2.0.1
Após esse passo, tudo já está funcionando e nosso Hasura já está conectado ao Postgres =D. Precisaremos configurar o projeto que será responsável pela administração de migrations. Para isso:
// Criar o projeto na pasta “hasura” hasura init hasura --endpoint http://localhost:8080 cd hasura Alguns arquivos e pastas já estarão criados, serão eles: config.yaml metadata migrations seeds Inicializando as migrations: hasura migrate create "init" --from-server
Será necessário copiar a ‘version’ para a aplicar ao banco de dados, assim o Hasura saberá que a versão atual do banco já é a mais atualizada:
hasura migrate apply --version "<version>" --skip-execution --database-name hasura_app
Para finalizar a configuração exportamos os metadados:
hasura metadata export
Agora que já configuramos tudo o que precisávamos, podemos acessar o console do Hasura com o seguinte comando:
// O console será servido em alguma porta a partir do localhost hasura console
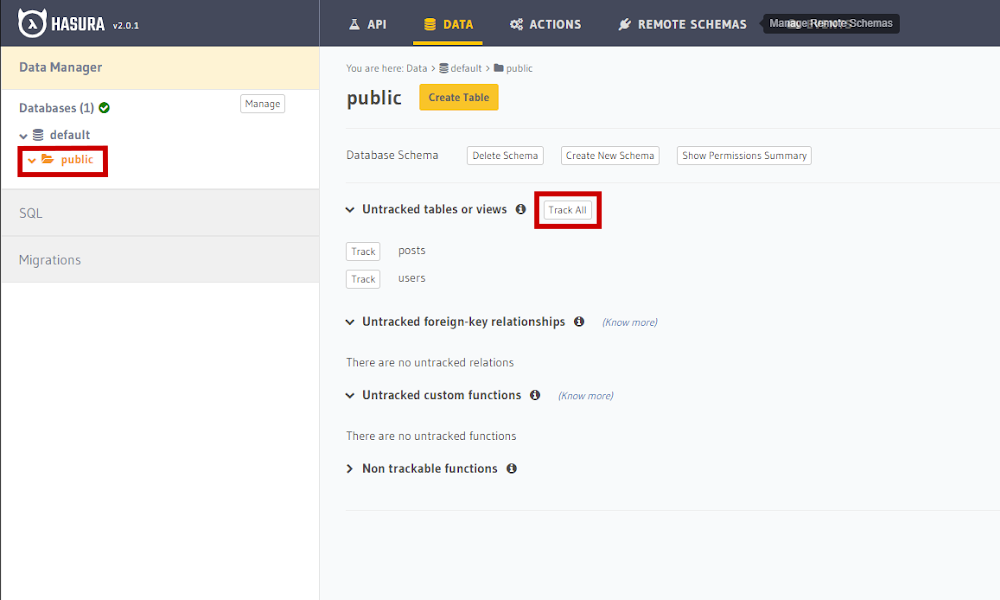
Selecionando a pasta public, é possível ativar o tracking para as tabelas desejadas. Como desejamos fazer o tracking de todas elas, vamos clicar em ‘track_all’, conforme a figura a seguir.
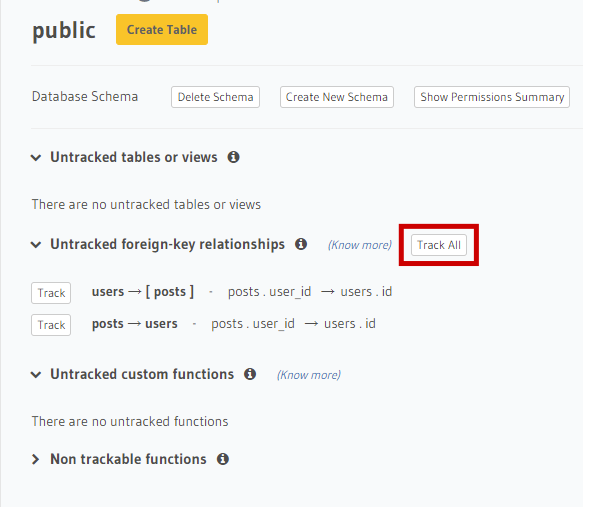
As relações também são conhecidas de forma automática, faremos o tracking de todas, clicando em ‘track_all’, como mostra a imagem abaixo.
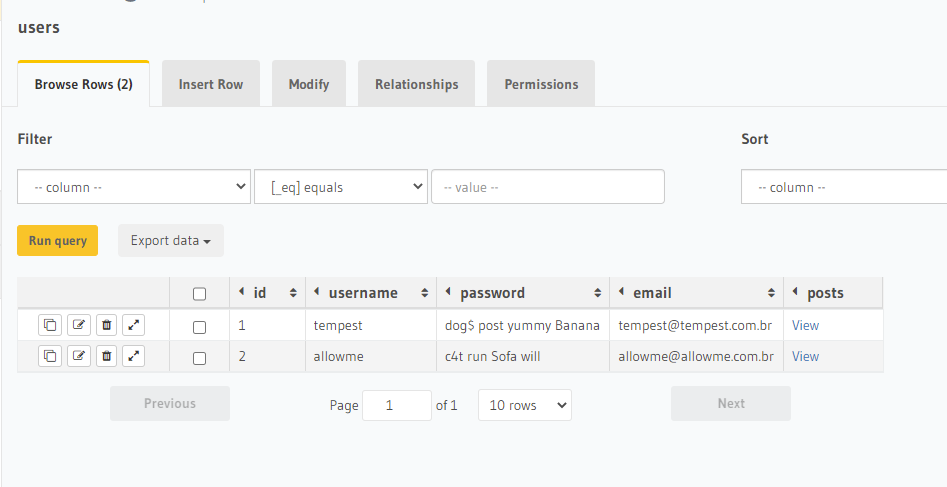
Podemos visualizar os dados a partir da aba ‘data’.
E também podemos modificar nosso schema para adicionar uma nova coluna.
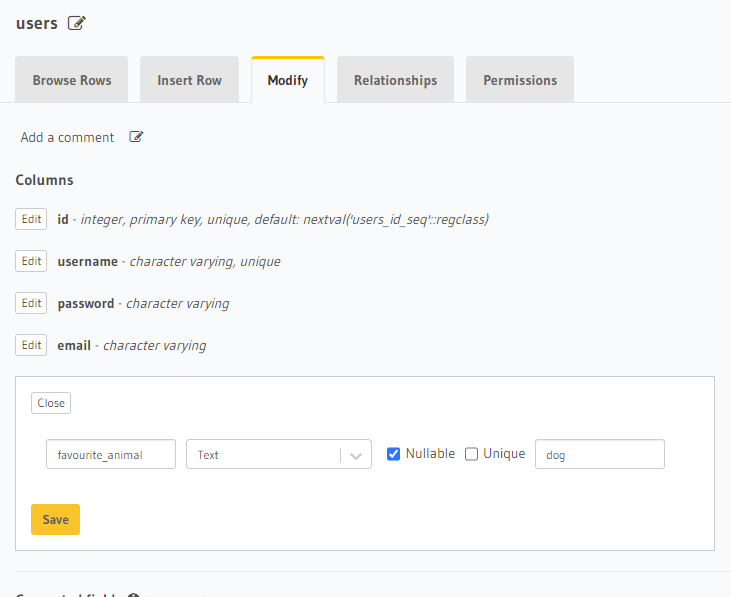
Ao clicar em ‘Save’, uma migration é gerada, automaticamente, dentro da pasta ‘migrations’ do projeto Hasura que inicializamos com a CLI, com os arquivos de up.sql e down.sql.
Agora o mais interessante: na aba de API é possível ver que o Hasura criou automaticamente uma API GraphQL mapeando as tabelas em tracking, possibilitando fazer subscriptions, mutations e queries =D
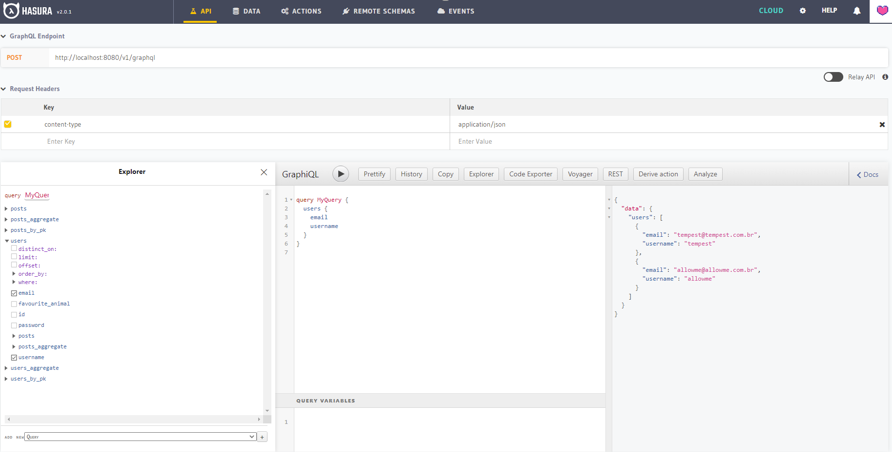
Temos até um explorador, com GraphiQL, que nos permitirá testar e visualizar a documentação gerada automaticamente pelo GraphQL. Aqui estão alguns exemplos de query:
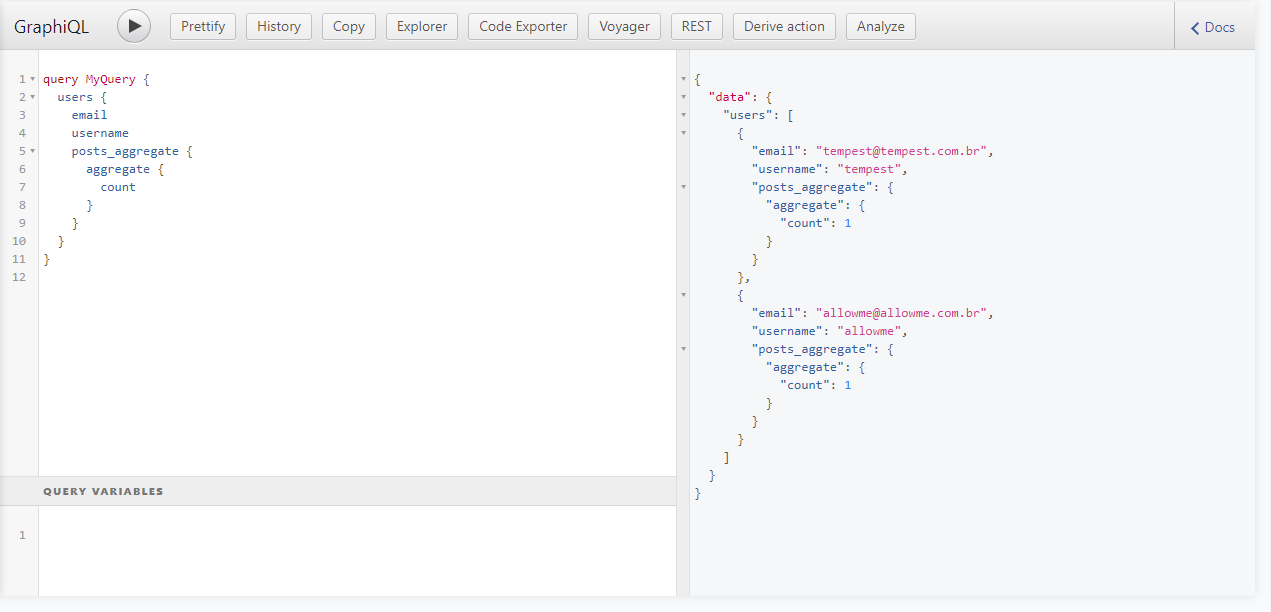
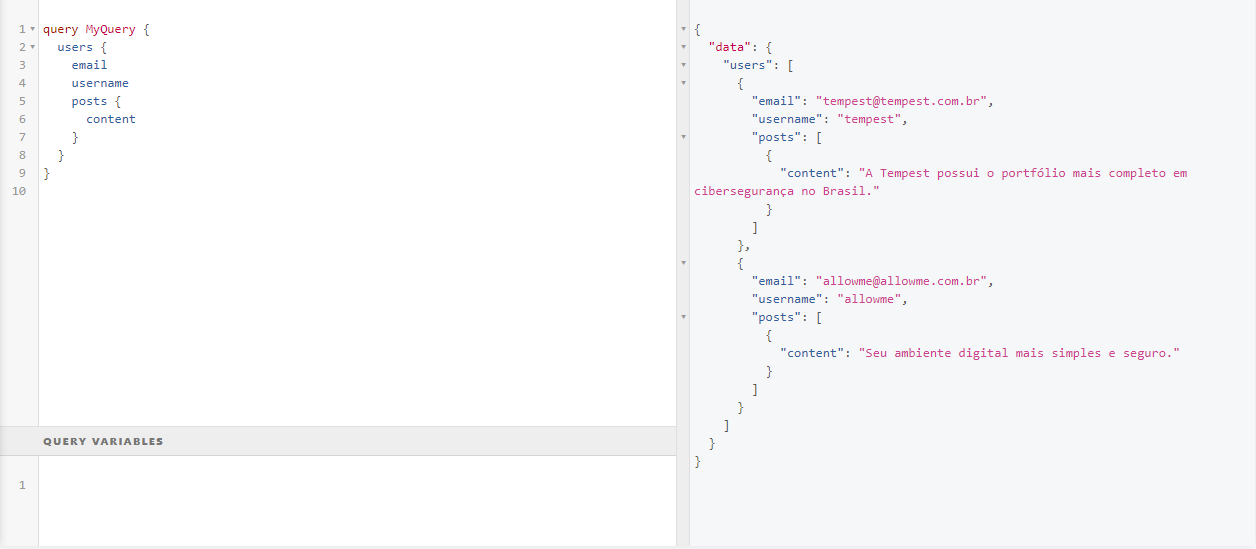
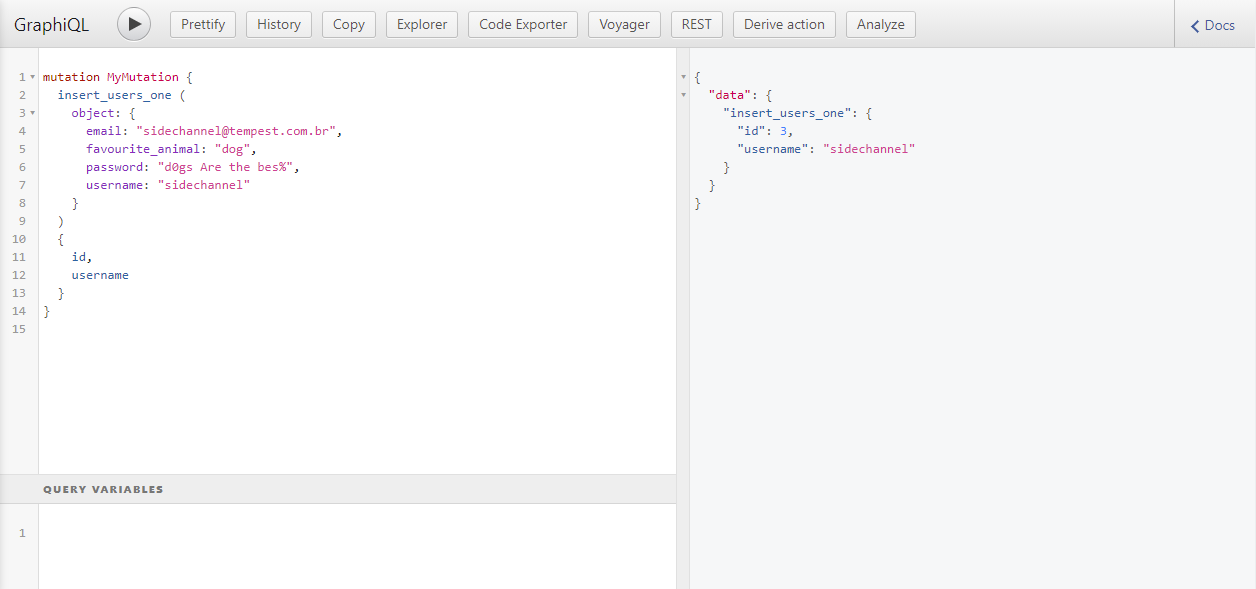
E um exemplo de mutation:
A API gerada também consegue lidar com erros de validação do banco de dados, por exemplo:
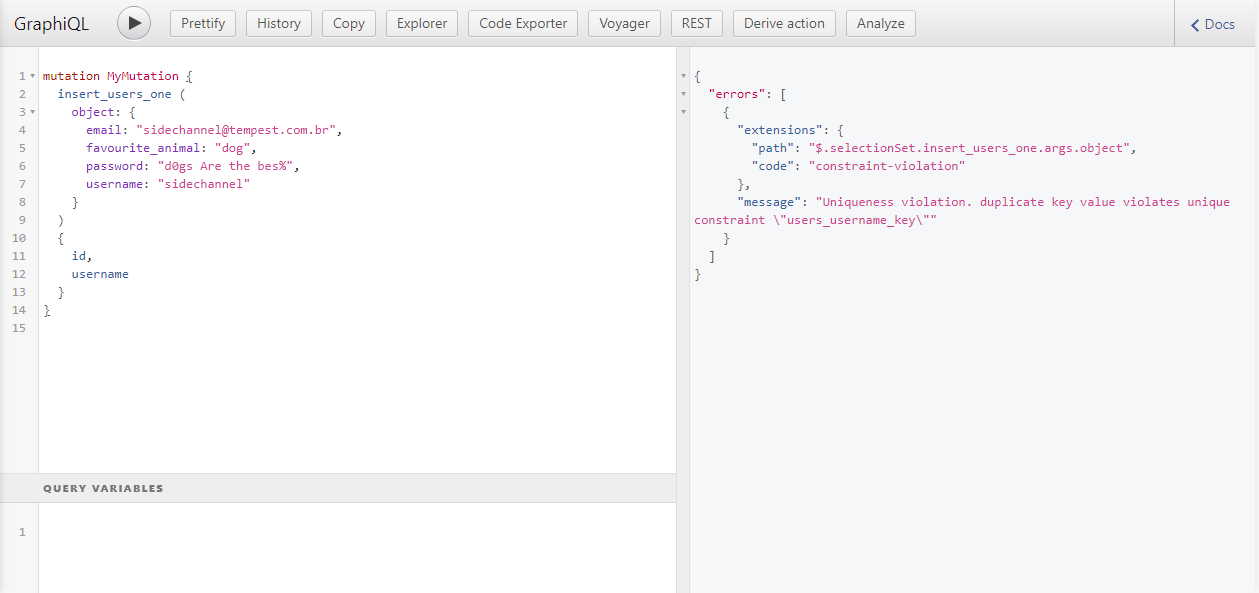
Conclusão
O Hasura é um serviço que elimina bastante o atrito inicial para a utilização de API’s GraphQL. É extremamente útil em casos de provas de conceitos ou MVP’s que devem ser desenvolvidos o mais rápido possível. A falta de customização na API, como filtros e constraints do lado do backend não fazem com que o Hasura, por si só, seja capaz de atuar como o único backend da aplicação, mas sim como algo que intermedia o banco de dados a outros serviços de backend.
Por fim, o Hasura tem várias outras funcionalidades que não foram exploradas neste artigo, todas elas, claro, estão disponíveis para estudo no site oficial: https://hasura.io/