Por Alana Marques de Morais
The unbridled adoption of machine learning models in the most diverse applications, without due care for the risks and vulnerabilities introduced by the use of machine learning, can cause losses and even fatal accidents. Imagine, for example, that the pedestrian detection system of an autonomous car, based on machine learning, is attacked, compromised and led to failure. So, as a result of Tempest’s efforts to disseminate knowledge and contribute to the scientific, academic, industrial and cybersecurity community, we are launching a series of five blog posts to discuss the risks and vulnerabilities introduced by the use of machine learning.
In this first post, we explain what adversarial attacks are, which aim to compromise the operation of machine learning models, as well as their main categories. In the following three blog posts, we will discuss how adversarial attacks can compromise different applications, highlighting in a practical way the need to protect and secure machine learning models. Finally, in the last blog post of this series, we will discuss future trends and possible approaches to make machine learning models resilient to adversarial attacks. Welcome to our journey!
-
Introduction
The term machine learning hits the headlines with increasing frequency and refers to the branch of artificial intelligence that is based on the concept that systems can learn from data to identify patterns and make decisions with minimal human intervention. There are, for example, classification algorithms, which assign samples of data to a category from a set of possible categories. A typical example is the detection of customers with fraudulent profiles. Imagine that a customer wants to obtain a loan from a bank. The bank manager might ask himself, “will this customer pay back the loan?” Or, “what type of interest rate would best fit this customer’s profile (10%, 15%, 20%, etc.)?”. This is a typical classification problem, since you want to sort a customer into one of the possible classes of the problem, for example good payer/bad payer or “10%”/”15%”/”20%” interest. Thus, by automating processes and possessing great assertiveness, machine learning models have been increasingly adopted in several areas.
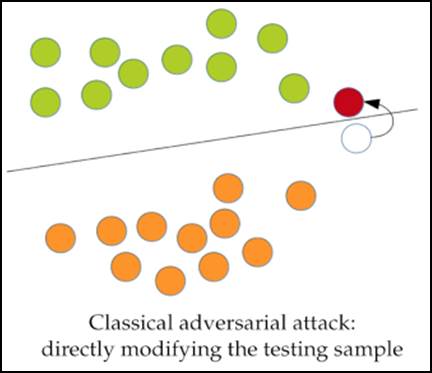
However, not everything is perfect. Although the use of machine learning brings numerous benefits for a variety of applications, recent research shows that machine learning models can be misleading and have their accuracy significantly reduced. In general, classifiers create decision boundaries where the data in each class is located on opposite sides of them. Adversarial attacks, on the other hand, are attacks that produce small perturbations that distort data samples and force them to cross the decision boundaries, causing misclassifications. Image 1 illustrates this process. The green and orange balls represent two classes separated by a decision boundary defined by a classification model, such as a malware detection system. The white ball, in turn, represents a data sample that is adulterated by adding a small adversarial perturbation. This perturbation causes the white ball to cross the boundary of the orange balls (its true class) to the side of the green balls, being misclassified.
Image 2 illustrates an example of adversarial attack in an image classifier [1]. On the left, we have an image of an animal that is correctly classified by a convolutional neural network as being the image of a pig. However, by introducing an adversarial perturbation to the image, small enough so that the image on the right appears to be identical to the image on the left, the neural network assigns the class “airliner” to the image of the pig. Now imagine that this classifier is part of a livestock monitoring project. Such an action would probably result in wrong analyses about the animals and wrong decisions that could cause damage and death to animals.

Unlike cyber attacks, which aim to compromise the confidentiality, integrity, and availability of information, among other aspects, adversarial attacks compromise the operation of machine learning models by misleading them, as illustrated in Images 1 and 2. Thus, from the moment machine learning-based classifiers begin to be used in cybersecurity, to detect malware, for example, adversarial attacks become a major threat to cybersecurity by compromising defensive systems [9, 10].
In the same way, as machine learning models are adopted in many different areas, adversarial attacks can potentially cause a variety of problems in many different contexts [2, 3]. They can, for example, make autonomous cars see red lights as green lights, or reduce the accuracy of obstacle and pedestrian detection systems, causing potentially fatal accidents [13]. So in general, attacks against machine learning models can be used in several ways to:
- Cause damage: by causing intelligent systems to malfunction, such as those present in autonomous vehicles to recognize stop signs, other cars, pedestrians, and obstacles in general.
- Conceal something: by avoiding detection of cyberattacks, unwanted advertisements, and inappropriate or generally unwanted content, for example to prevent the blocking of terrorist advertisements on social networks.
- Degrade the reliability of systems: by reducing the trust an operator has in the machine learning model used, leading to its shutdown. An example of this are attacks that cause an automated security alarm to misclassify regular events as security threats, triggering a flood of false alarms that can lead to system failure.
-
Taxonomy of adversarial attacks
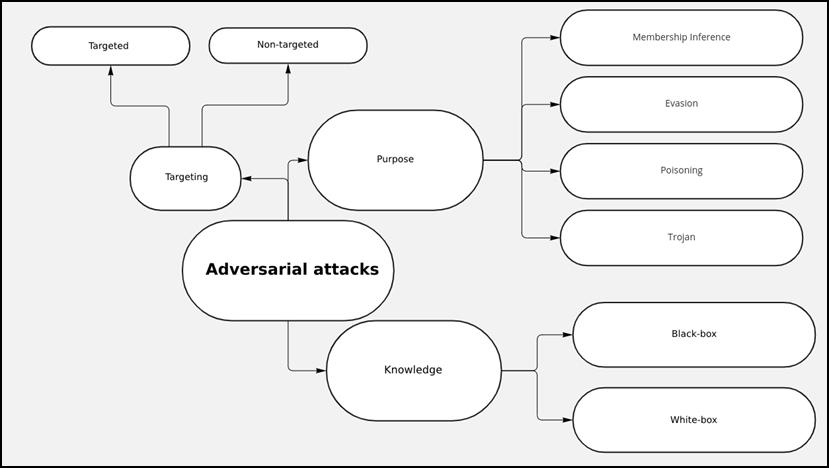
Adversarial attacks exploit vulnerabilities created by using machine learning models and employ different strategies to achieve malicious goals [4, 5]. As such, they can be classified in different ways. We highlight here how they can be classified according to the prior knowledge the attacker has about the machine learning model that is the subject of the attack, whether the attack has a target or not, and the attacker’s purpose. The following subsections detail each of the classifications illustrated in Image 3.
2.1. Knowledge
This category is based on the prior knowledge that the attacker holds about the machine learning model that is the subject of the attack and classifies adversarial attacks into white-box and black-box. Although some authors also consider the grey-box or semi-white-box group in this category, in this blog post we adopt the authors’ line that advocates only two groups in this categorization [5, 8].
a) White-box attacks
White-box adversarial attacks require the attacker to have complete knowledge of the machine learning model that is the target of the attack, such as training data, architecture, learning algorithm, and hyperparameters [6]. The authors of [7], for example, proposed a technique to generate white-box adversarial attacks called AdvGAN, which generates adversarial attack examples using generative adversarial networks (GANs). The model trained by them was able to produce adversarial perturbations efficiently and execute white-box attacks with a success rate of over 90%.
b) Black-box attacks
As for black-box attacks, the attacker has no information about the target model. The attacker can, however, have knowledge of input-output pairs by using the target model, i.e. the attacker can “query” the target model by sending data samples to it and receiving back its classification results. This is a more realistic attack scenario since the attacker generally doesn’t have complete access to the model, as required by white-box attacks, but to the model’s outputs via APIs.
Additionally, the authors in [8] define three more restrictive and realistic black-box threat models: query-limited, partial information, and decision-based. The query-limited scenario considers that the attacker has access to only a limited number of model outputs. The partial information scenario considers that the attacker has access only to the probabilities of some of the classes in the model. Finally, the decision-based scenario considers that the attacker has access only to the decision of the model, meaning the class to which he assigns a given data sample, rather than probability values.
2.2. Targeting
The second classification perspective is associated with whether the attacker has a specific target or not, i.e., whether the attacker wants the model to miss or wants the model to miss in a specific way. Thus, in this categorization, you have untargeted and targeted attacks.
a) Non-targeted attacks
In non-directed attacks, the attacker’s intention is to trick the model into predicting a different output than it should have. To the attacker, it doesn’t matter to which wrong class the model will assign a given sample, as long as the sample is not assigned to the correct one [18, 19]. In the case of an image classifier, for example, the attacker may aim for images of dogs not to be classified as being dogs, but it doesn’t matter to him whether those images are classified as being cats or birds.
b) Targeted attacks
In targeted attacks, it isn’t enough that the model gets it wrong, the attacker has to force the model to get it wrong in a specific way [2]. He may want, for example, to have images of dogs classified as being images of cats.
2.3. Purpose
According to their purpose, adversarial attacks can be classified into: evasion, poisoning, trojan and membership inference.
a) Evasion
Evasion attacks occur when adversarial perturbations are introduced to data samples at inference time, meaning that the machine learning model that is the target of the attack has already been trained and is in full operation. Being one of the most exploited attack types, up to now, several works propose evasion-type attacks [15, 16]. In malware detection systems, for example, evasion attacks can be used to evade detection, i.e., to disguise the malicious content of cyberattacks so that, for example, malwares are not detected.
b) Poisoning
Poisoning attacks aim to contaminate (poison) data that will be used to train the target machine learning model. In general, the attacker can manipulate training data in four different ways:
- Label modification: modifies the labels of a supervised learning dataset in an arbitrary manner.
- Data injection: Adds new data to the training set.
- Data Modification: Modifies training data before it has been used to train the target model.
- Logical corruption: The attacker has the ability to interfere with the machine learning algorithm.
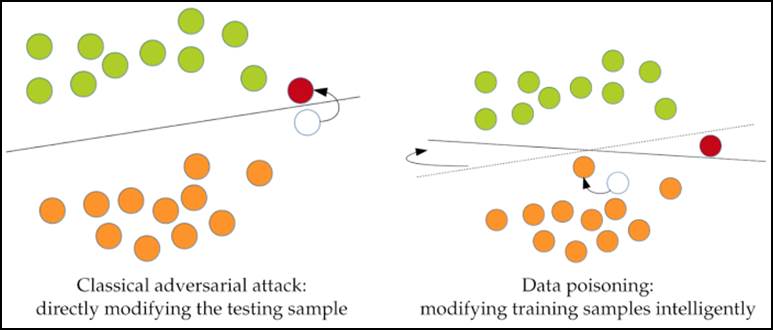
Image 4 illustrates the poisoning attack in detail, and also compares it to an adversarial evasion attack. Basically, the main difference is that poisoning attacks alter the classification boundaries by modifying the training data set, while adversarial evasion attacks alter the input data.
c) Trojan
In adversarial Trojan attacks, the attacker doesn’t have access to the initial dataset, but has access to the model and its parameters and is able to retrain that model. When can this occur? Currently, many companies do not build models from scratch, but retrain existing models, adapting them to their environment and usage scenario. For example, if it’s necessary to build a model for cancer detection, known image recognition models can be used and retrained with a specific dataset for identifying images that represent cancer.
d) Membership Inference
Finally, adversarial membership inference attacks aim to identify what data was used in training the target machine learning model. This information can be very useful for developing more sophisticated poisoning attacks and also for inferring the model’s architecture when it’s unknown.
-
Upcoming blog posts: adversarial attacks on networks
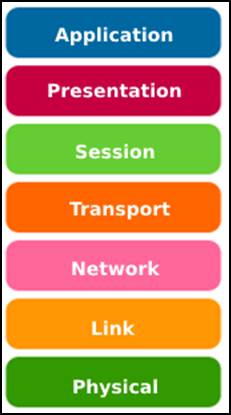
As networking and communications applications have increasingly adopted machine learning, the impact of adversarial attacks in these contexts deserves to be highlighted and has been the subject of several research studies. Thus, in order to make our discussion more didactic, we’ll address in the next blog posts adversarial attacks in different contexts and scenarios according to the layers of the Open Systems Interconnection (OSI) model, which organizes communication in networks through layers [11]. Image 5 presents the seven layers of the OSI model: physical, link, network, transport, session, presentation, and application [12].
So, in the second blog post in this series, we’ll focus on adversarial attacks at the physical layer, where attackers can, for example, compromise the transmission of wireless communication signals from Wi-Fi or cellular networks. In the third blog post, we’ll discuss adversarial attacks at the network layer, where intrusion detection systems can be compromised. And finally, in the fourth blog post in this series, we’ll focus on the application layer, where attackers can tamper with computer programs, cell phone applications, and even circumvent facial biometrics systems.
-
Conclusion
This was the first of five posts in our series on risks and vulnerabilities introduced by machine learning. Here, we introduced what adversarial attacks are, how they can compromise machine learning models by misleading them, and how adversarial attacks can be categorized. As presented, although machine learning models bring great benefits to many applications, it’s necessary to consider the risks they introduce and how impacted they can be by adversarial attacks before adopting them freely and widely in applications where mistakes can mean big losses.
At Tempest, we are working to address these challenging issues to better protect your business! Stay tuned for our next post in this series of 5 posts!
References
[1] Tabassi, E., Burns, K. J., Hadjimichael, M., Molina-Markham, A. D., & Sexton, J. T. (2019). A taxonomy and terminology of adversarial machine learning. NIST IR, 1-29.
[2] Carlini, Nicholas, and David Wagner. “Audio adversarial examples: Targeted attacks on speech-to-text.” 2018 IEEE security and privacy workshops (SPW). IEEE, 2018.
[3] Jia, R., & Liang, P. (2017). Adversarial examples for evaluating reading comprehension systems. arXiv preprint arXiv:1707.07328.
[4] Huang, S., Papernot, N., Goodfellow, I., Duan, Y., & Abbeel, P. (2017). Adversarial attacks on neural network policies. arXiv preprint arXiv:1702.02284.
[5] Liu, J., Nogueira, M., Fernandes, J., & Kantarci, B. (2021). Adversarial Machine Learning: A Multi-Layer Review of the State-of-the-Art and Challenges for Wireless and Mobile Systems. IEEE Communications Surveys & Tutorials.
[6] De Araujo-Filho, P. F., Kaddoum, G., Naili, M., Fapi, E. T., & Zhu, Z. (2022). Multi-objective GAN-based adversarial attack technique for modulation classifiers. IEEE Communications Letters.
[7] Xiao, C., Li, B., Zhu, J. Y., He, W., Liu, M., & Song, D. (2018). Generating adversarial examples with adversarial networks. arXiv preprint arXiv:1801.02610.
[8] Ilyas, A., Engstrom, L., Athalye, A., & Lin, J. (2018, July). Black-box adversarial attacks with limited queries and information. In International Conference on Machine Learning (pp. 2137-2146). PMLR.
[9] Gu, T., Dolan-Gavitt, B., & Garg, S. (2017). Badnets: Identifying vulnerabilities in the machine learning model supply chain. arXiv preprint arXiv:1708.06733.
[10] Sharif, M., Bhagavatula, S., Bauer, L., & Reiter, M. K. (2016, October). Accessorize to a crime: Real and stealthy attacks on state-of-the-art face recognition. In Proceedings of the 2016 acm sigsac conference on computer and communications security (pp. 1528-1540).
[11] Tanenbaum, A. S. Redes de computadores.5ª ed. São Paulo: Pearson Prentice Hall, 2011.
[12] Mendes, D. R. Redes de computadores: Teoria e Prática. São Paulo: Novatec, 2007.
[13] Yamin, M. M., Ullah, M., Ullah, H., & Katt, B. (2021). Weaponized AI for cyber attacks. Journal of Information Security and Applications, 57, 102722.
[14] Comiter, M. Attacking artificial intelligence. Belfer Center Paper, v. 8, 2019.
[15] Apruzzese, G., Andreolini, M., Marchetti, M., Venturi, A., & Colajanni, M. (2020). Deep reinforcement adversarial learning against botnet evasion attacks. IEEE Transactions on Network and Service Management, 17(4), 1975-1987.
[16] Rathore, H., Samavedhi, A., Sahay, S. K., & Sewak, M. (2022, May). Are Malware Detection Models Adversarial Robust Against Evasion Attack?. In IEEE INFOCOM 2022-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS) (pp. 1-2). IEEE.
[17] How to attack Machine Learning (Evasion, Poisoning, Inference, Trojans, Backdoors). Acesso em: 13 de setembro, 2022. [Online]. Disponível: https://towardsdatascience.com/how-to-attack-machine-learning-evasion-poisoning-inference-trojans-backdoors-a7cb5832595c
[18] A. Wu, Y. Han, Q. Zhang, and X. Kuang, “Untargeted adversarial attack via expanding the semantic gap,” in Proc. IEEE Int. Conf. Multimedia Expo (ICME), Jul. 2019, pp. 514–519.
[19] H. Kwon, Y. Kim, H. Yoon, and D. Choi, “Selective untargeted evasion attack: An adversarial example that will not be classified as certain avoided classes,” IEEE Access, vol. 7, pp. 73493–73503, 2019.