By Maria Fernanda Rodrigues Vieira e Silva
The use of Machine Learning (ML) in the area of information security has great potential and has been increasingly developed over the years (IBM, 2022). It can be used for a variety of purposes, such as intrusion detection, fraud detection and vulnerability detection. In the context of vulnerability detection, we can highlight three types of techniques for identifying possible attack surfaces in applications:
- Static techniques: these are based on source code analysis;
- Dynamic techniques: these analyze the software at runtime;
- Hybrid techniques: these combine static and dynamic techniques.
In this article, we’ll explain how Functionally-similar yet Inconsistent Code (FICS) works (AHMADI, 2021), a vulnerability detection mechanism that is based on static techniques to analyze similarity and identify inconsistencies in code, which in turn can represent bugs that cause security flaws. In general, this mechanism uses a customized representation of the source code in the form of a graph in conjunction with the ML algorithm of hierarchical clustering. In the following sections, we’ll explain how FICS (AHMADI, 2021) works and what its advantages and main results are. Then, we’ll highlight the limitations of this system and what could be done to improve it.
Functionally-similar yet Inconsistent Code (FICS)
To analyse and find inconsistencies in source code, FICS receives the source code of a piece of software written in C, transcribes it into the Low Level Virtual Machine (LLVM) compiler’s intermediate representation language (BAKSHI, 2022) and transforms it into graphs called “constructs”, which are then vectorized.
The construct vectors then go through a first clustering process, the aim of which is to group representations that are similar. This first clustering has a “rougher”, more permissive filter, which allows the creation of a smaller number of clusters, each with a larger number of elements.
Next, FICS performs a second clustering whose aim is to identify, within the groups created in the first clustering, the vectors that differ from each other. Thus, a “refined”, less permissive filter is applied, which allows us to identify these differences, highlighting the vectors that are similar but have some inconsistency in their construction.
Finally, these differences found in the construction of the vectors, called bugs by FICS, are presented to an analyst in code format, so he can identify whether they could cause security flaws. Image 1 is a macro representation of the main phases carried out by FICS (AHMADI, 2021 and AHMADI, 2022).
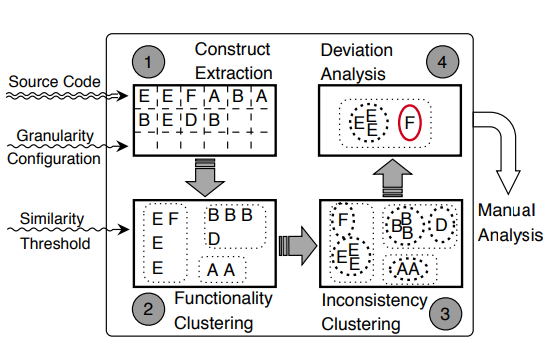
If you’re still wondering “Okay… But I still don’t understand how this whole process works…” that’s all right. We’ll explain it better below!
In Image 2 we can see the steps taken by the FICS, which can be subdivided into four parts, which are detailed below:
- Transforming Code into Vectors;
- First Clusterization;
- Second Clusterization;
- Manual Analysis.
Part 1: Transforming Code into Vectors
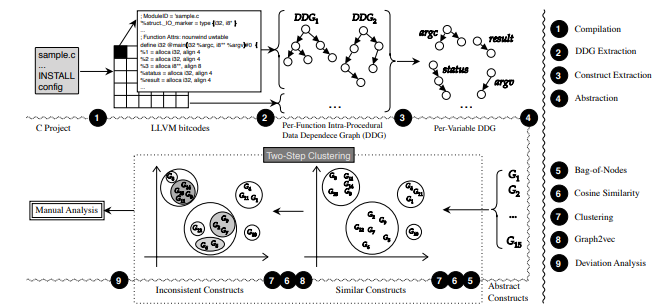
As shown, in its first stage, FICS transforms source code into representations that can be clustered. To do this, it performs four actions, as shown in Image 3: i) compilation, ii) extraction of data dependency graphs (DDGs) and formation of constructs, iii) abstraction of constructs and iv) bag of nodes.
Compilation
The aim of this step is to compile the project in C and represent it in bitcode form (.bc). The system uses the LLVM compiler which has the tools OPT, responsible for optimizing the code in the compilation process and Clang, responsible for translating the C code into bitcode, as we can see in Image 4. (CHRISTOPHER, 2022)
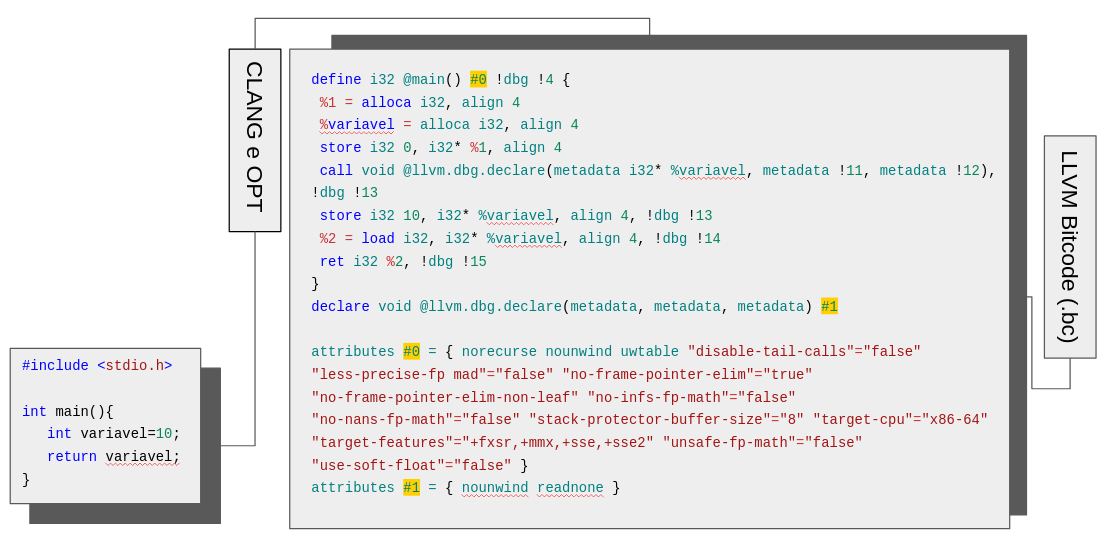
With this representation, we extract the most important parts of the computations taking place in the source code, indicated in blue, such as the alloca instruction, responsible for allocating memory on the stack of the function being executed, the store instruction, responsible for writing instructions to the memory stack of the function being executed, and the load instruction, responsible for reading instructions from memory. More information on these operations can be found in (LLVM Foundation, 2023).
Extraction of the Data Dependence Graph and Formation of Constructs
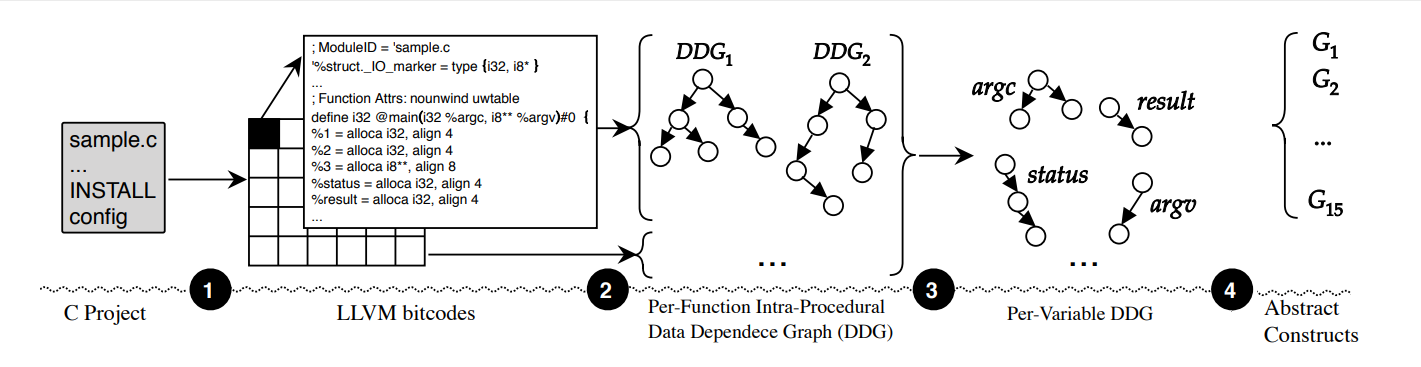
After converting the source code to bitcode, FICS extracts DDGs, which are graphs that represent how the various parts of the code are related, from all the functions present in the code. In this way, we obtain, in graph form, a representation of how the functions in the source code relate to each other. Image 5 illustrates the extraction of DDGs from a C function.
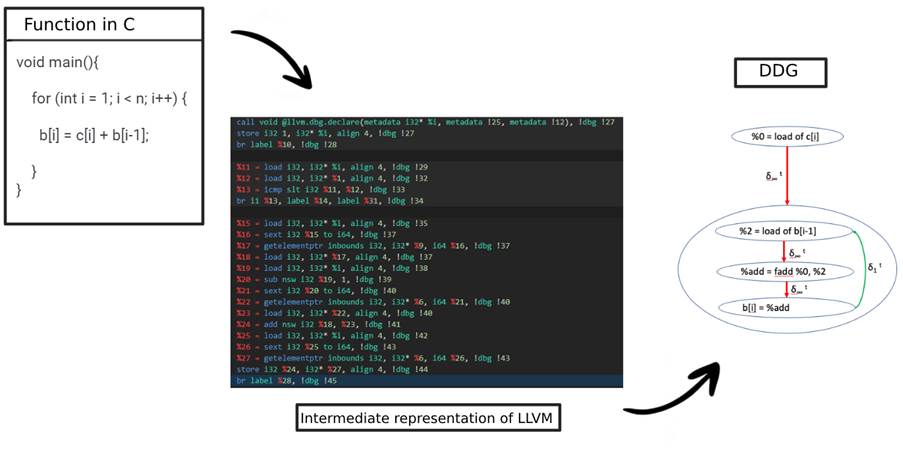
But how does this graph representation work? Let’s take a quick look. We can define graphs in two structures: Nodes, which represent declarations, predicates, operations or operands related to code elements, and Edges, which represent the dependencies between nodes. They are considered one of the best ways of representing code, since it’s possible to graphically explain the nodes’ interdependencies throughout the project.
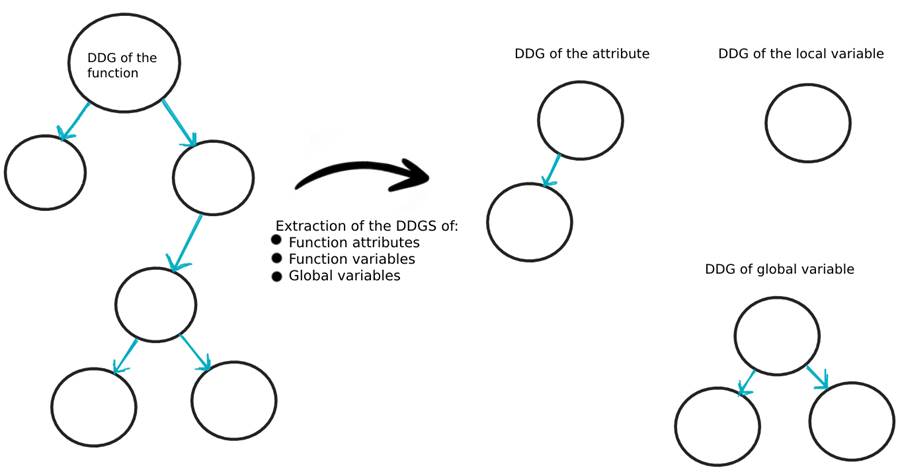
After extracting the DDGs of the functions, FICS performs a second DDG extraction, but now for all the attributes, local variables and global variables of the code, as shown in Image 6.
The FICS authors propose a customized representation of the code, called a Construct, which is built using the results of this second DDG extraction. Each element of the code will have its own representation in the form of a construct, detailing its dependencies over the entire code, as shown in images 7 and 8.
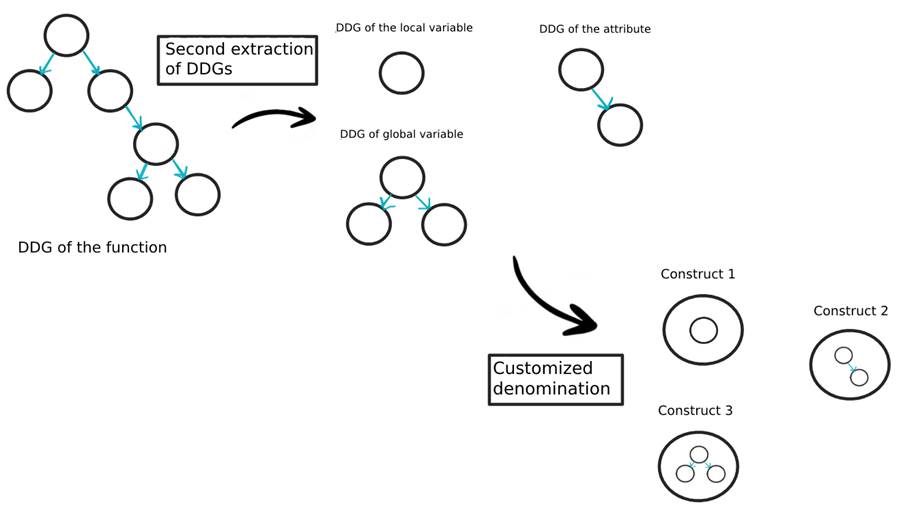
Construct abstraction
After extracting the constructs, some information is discarded, such as the variable names, versions, constants and literals. Only the types of the variables and the most important computations, indicated in the compilation process, remain. As an example, Image 9 shows the construct, in its abstracted form, of the function’s variable data. You can only recognize the operations performed and the data types.
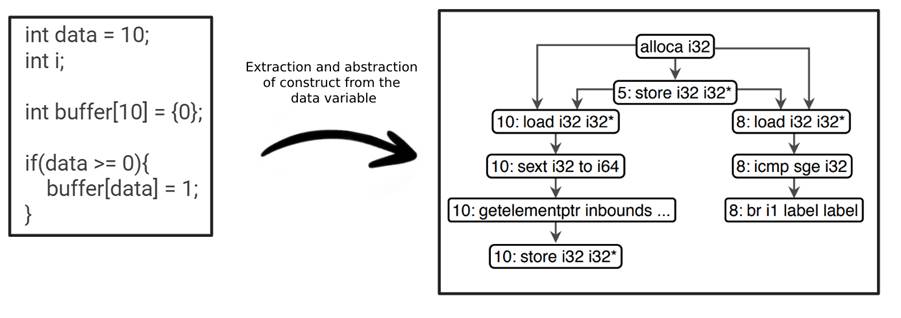
Bag of Nodes
After abstraction, the next step is to build embeddings for the abstracted constructs. Embedding refers to techniques for transposing information from a complex object to a simpler one, in our case, transforming a graph structure, which is more complex, into vectors, which are less complex. FICS uses the embedding bag of nodes which transforms the graphs of the abstracted constructs into vectors. This process takes place in such a way that each operation on the node, such as alloca i32, store i32 i32*, load i32 i32*, icmp sge i32 and br i1 label label, is placed on a specific index within a vector, as shown in image 10.
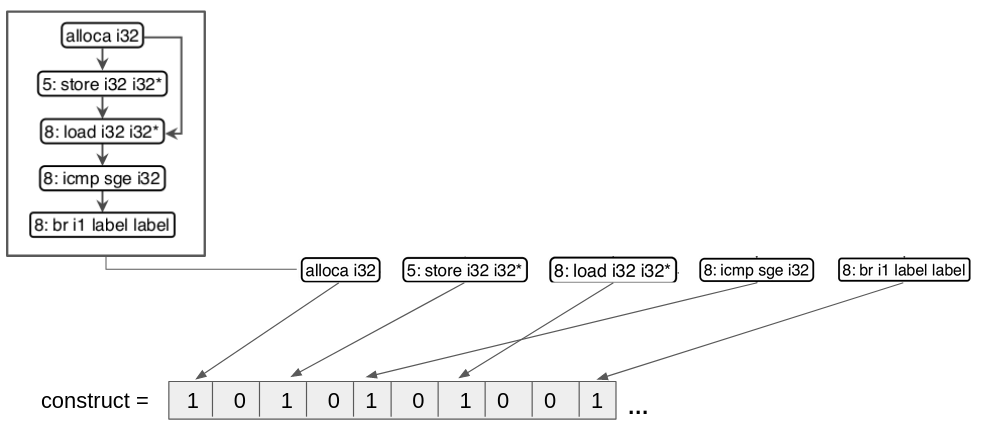
This process takes place for all the constructs, after which all the source code is represented by vectors.
Part 2: First Clustering
Once the code is represented as vectors, FICS performs a first clustering by grouping the vectors into clusters according to a distance metric. The distance metric used is the cosine measure, also known as cosine similarity, which calculates the distance between vectors from the cosine of the angle between them. The closer the result is to 1, the more similar the vectors are and vice versa. Thus, each pair of vectors will have its own cosine similarity value which will be supplied to the connected-components algorithm, which is responsible for forming the clusters, as shown in image 11.
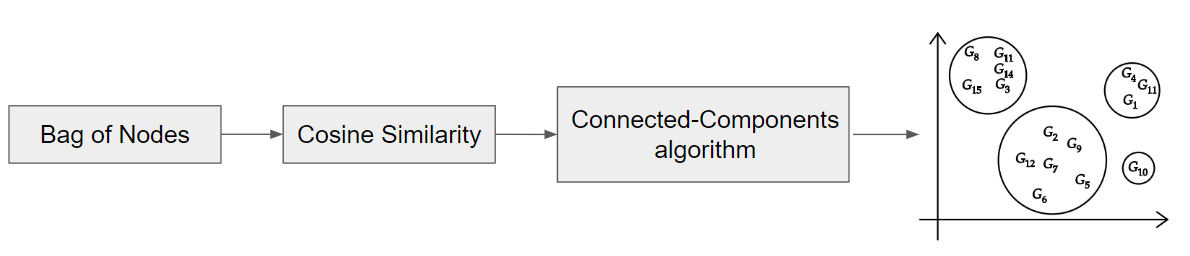
Part 3: Second Clusterization
After creating the first clusters, a second embedding is created using the graph2vec tool, which also transforms graphs into vectors, and cosine similarity is again applied between the pairs of vectors resulting from graph2vec to the second clustering, with a more refined filter, as shown in image 12.

Part 4: Manual Analysis
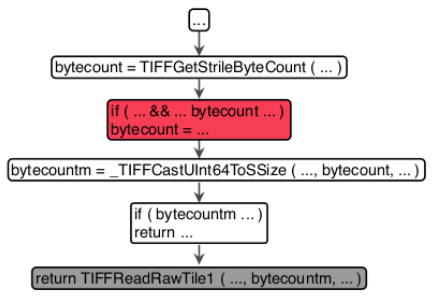
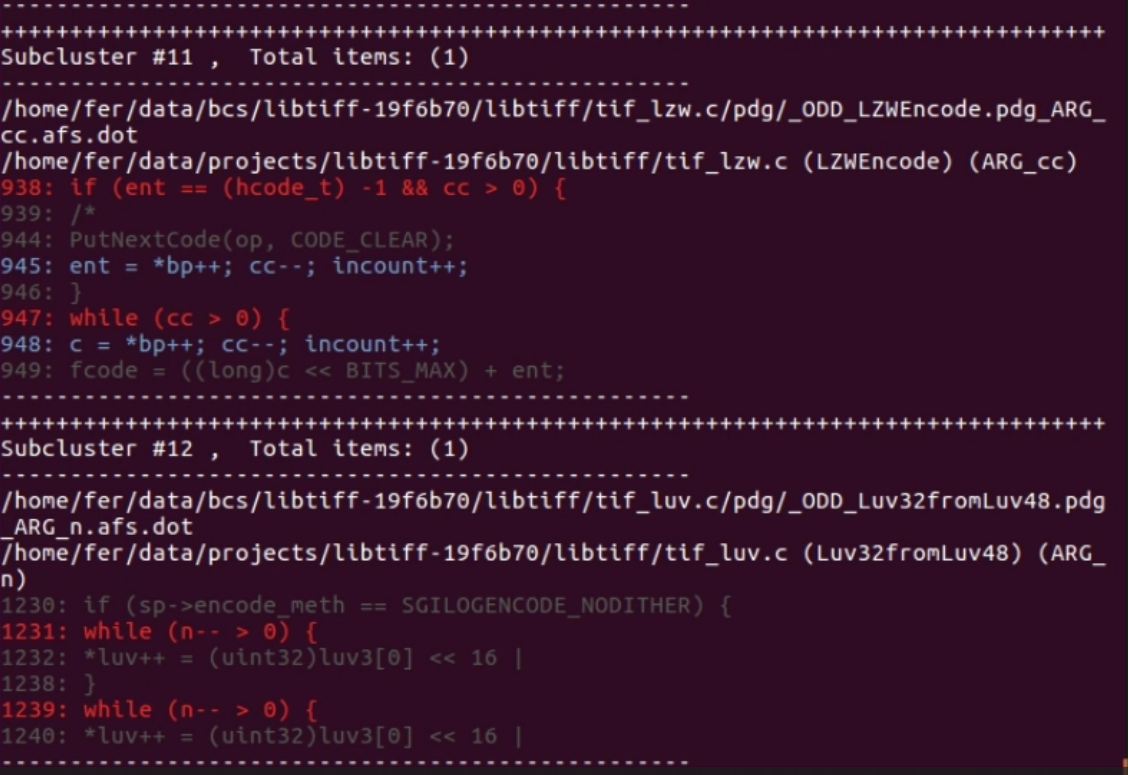
Finally, the parts of the code with inconsistencies will be highlighted as shown in image 13 in order to be analyzed by a security expert, who will verify the real potential for these inconsistencies to generate security problems.
Main Results
Here we highlight the main results of FICS (AHMADI, 2022). It proves its worth by detecting 22 new vulnerabilities in 5 different projects that had already been tested previously:
- LibTiff: 5 bugs out of 93 inconsistencies detected;
- OpenSSH: 1 bug out of 121 inconsistencies detected;
- OpenSSL: 9 bugs out of 310 inconsistencies detected;
- QEMU: 4 bugs out of 1206 inconsistencies detected;
- WolfSSL: 3 bugs out of 91 inconsistencies detected.
Limitations and recommendations
The system has some limitations to consider, such as only working with one programming language (C) and the restriction that the codes analyzed cannot be too small, as it would not be possible to compare several parts of the code with each other, or too large, as the representation of the constructs would be computationally too heavy.
Given these limitations, we have made some recommendations for improvements to FICS. In order to improve performance, there’s a need to evaluate some other form of source code representation, as constructs are very heavy computationally, making it difficult to apply FICS to large projects. In addition, the possibility of transferring learning from one project to another, through transfer learning techniques for example, as well as evaluating other clustering algorithms, could provide better results.
Final considerations:
In this article, we presented FICS (AHMADI, 2021), a system that uses a customized representation of source code (customized constructs) to compare and detect bugs that could generate security vulnerabilities.
Its great advantage is that it doesn’t require any prior data. The entire learning curve comes from the source code to which the mechanism is applied. It doesn’t use a database of tabulated vulnerabilities that it will train and apply to another project. The aim is to find parts of the code that look similar, but which for whatever reason have some inconsistency, and thus could possibly lead to a security flaw.
This whole process opens doors to a vast horizon of possibilities within the world of Machine Learning, but as we have seen, it still needs a lot of improvement before we can apply it to the daily life of a security professional.
References:
AHMADI, M. FARKHANI, R. M. WILLIAMS R., LU, L. Finding bugs using your own code: Detecting functionally-similar yet inconsistent code, in Proc. 30th USENIX Secur. Symp. (USENIX Security), 2021, pp. 2025–2040.
AHMADI, M., FARKHANI R. M., WILLIAMS, R. Finding Bugs Using Your Own Code: Detecting Functionally-similar yet Inconsistent Code. Disponível online em: https://github.com/RiS3-Lab/FICS. 2022. Accessed on September 20, 2022.
AHMADI, M., FARKHANI R. M., WILLIAMS, R. USENIX Security ’21 Youtube video: Finding Bugs Using Your Own Code: Detecting Functionally-similar yet. Available online at: https://www.youtube.com/watch?v=nO7FHQEu2bc. 2021. Accessed on September 20, 2022.
BAKSHI, Tanmay. How LLVM & Clang work. Available at https://www.youtube.com/watch?v=IR_L1xf4PrU. Accessed on September 10, 2022.
CHRISTOPHER, E. DOERFERT, J. 2019 LLVM Developers’ Meeting: Introduction to LLVM. Available at https://www.youtube.com/watch?v=J5xExRGaIIY. Accessed on September 10, 2022.
IBM. What is machine learning? Available at: https://www.ibm.com/topics/machine-learning. Accessed on September 15, 2022.
LIN, G., WEN, S., HAN, Q., ZHANG, J. AND XIANG, Y. Software Vulnerability Detection Using Deep Neural Networks: A Survey. Available online at: https://ieeexplore.ieee.org/document/9108283. Accessed on September 15, 2022.
LLVM Foundation. LLVM Language Reference Manual. Available online at: https://llvm.org/docs/LangRef.html#instruction-reference. Accessed on September 20, 2023.