In this post we’ll understand basic concepts of Browser Exploitation, focusing on the Firefox browser’s Javascript engine, SpiderMonkey. There will be an introduction to topics like heaps, garbage collector, primitives and objects, in-memory structures, JIT interpreters and compilers, and most importantly, ways to exploit memory corruption flaws in Javascript engines.
Before we begin, two key pieces of information:
- the concepts presented here are based on SpiderMonkey version 66.0.3, with some references to the source code in mozilla-central, accessed in September 2022. So, it’s possible that small differences can be found in other versions of the engine;
- this post is quite technical and therefore a bit complex, but don’t be discouraged. If you are interested in reverse engineering, web browsers, memory corruption bugs or cybersecurity in general, it will be worth your time.
So let’s get down to business!
Javascript Engines and SpiderMonkey
For starters, it can be said that the main JS engines on the market (SpiderMonkey, V8, JavaScriptCore and Chakra) have a basic structure. It consists of:
- a compiler infrastructure (with one or more Just In Time compilers¹);
- a virtual machine that operates JS values and has a bytecode interpreter;
- a runtime that provides a set of native objects and functions.
The number of compilers and interpreters can be different in each engine. However, in general, you have at least the bytecode interpreter, the first-stage JIT compiler, which removes some of the overhead coming from the interpreter, and some other JIT compiler that performs heavier optimizations – often based on speculation.
In this context, it’s worth mentioning that Javascript functions are optimized based on how “hot” they are. With each call they get, they get hotter and hotter until the engine chooses to optimize the code in order to decrease the execution time of the function (because it is being executed so many times).
In the case of SpiderMonkey, we have the following (JIT) compilers/interpreters: Baseline Interpreter, Baseline JIT, and IonMonkey (the latter is currently called WarpMonkey, but disregard that for this text).
Just In Time Compiler (JIT) is the code execution strategy that involves compilation during program execution (runtime). Commonly, this occurs by converting bytecode to machine code, which is effectively executed.
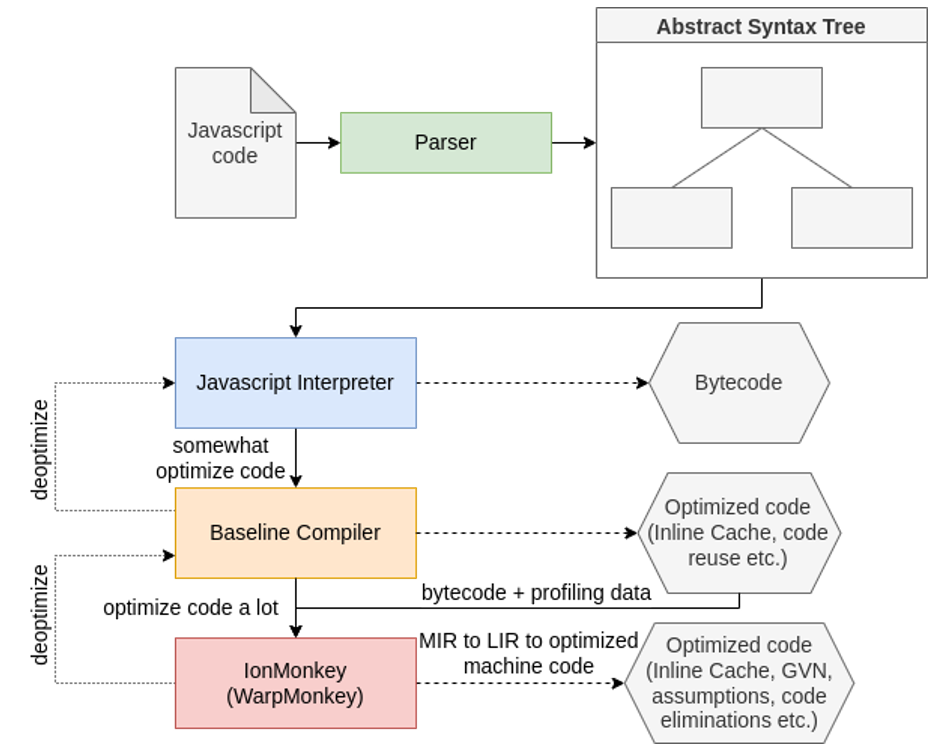
Briefly, you can describe each component above as follows:
- JS Interpreter: interprets the bytecode coming from the parser (Javascript code is transformed into intermediate code and then into bytecode);
- Baseline JIT compiler: just-in-time compiler that does some simple optimizations, for example using inline caching and reusing code;
- IonMonkey: just-in-time compiler that does the heavier optimizations. It turns JS code into compiled code.
A little more about IonMonkey
IonMonkey, as already mentioned, performs the most heavyweight optimizations of SpiderMonkey. These are based on the data and arguments that are processed on each call of the code. The optimization assumes that this code will continue to see data similar to what it saw before and uses these assumptions to create a compiled version (machine code) of the executed (and now optimized) snippet.
In the case of a function that is executed many, many times, it makes sense to spend extra time generating a compiled and optimized version of the code, because on subsequent executions the function will be more efficient/faster.
The steps performed by IonMonkey to perform code optimizations are:
- Middle-level Intermediate Representation (MIR) Generation: transforms bytecode into IR nodes, used in CFGs (Control Flow Graphs);
- Optimisation: ways of optimisation are identified based on MIR nodes. Some strategies are: Alias Analysis, Global Value Numbering, Constant Folding, Unreachable Code Elimination, Dead Code Elimination and Bounds Check Elimination;
- Lowering: transforms MIR code into LIR (architecture dependent);
- Code generation: machine code is generated from the LIR. Machine code linking is done by assigning it to a region of executable memory in addition to a set of assumptions for which the JIT code is valid.
Primitives and object types
If you have gotten this far in your reading, you should know that Javascript is a dynamic, object-oriented language, i.e., the variable types are determined at runtime and a JS program is a collection of objects that communicate with each other.
These objects are collections of zero or more properties, which have attributes to define how each of them should be used (Writable, Readable, etc.). The properties are containers that store objects, primitives, or functions (which are also objects).
Another important feature is that in JavaScript there is no concept of classes. Instead, prototype-based inheritance is used. Objects make (possibly null) references to prototypes whose properties they embody. In this way, it is possible to share properties and methods between objects.
The types that variables can take follow what is determined in the “ECMAScript Language Specification”, these are primitive types (Undefined, Null, Boolean, Number, BigInt, String, and Symbol) or objects (functions, arrays, etc.).
JS::Values
In the previous section, the types that a property or variable takes on were briefly mentioned. However, to understand them in the depth we want, it’s necessary to understand about JS::Values.
SpiderMonkey uses variables called JS::Values (sometimes only described as jsvals) to represent strings, floating point and integers, objects (including arrays and functions), booleans, and special values such as null and undefined.
Each JS::Value is 8 bytes long (fits into registers of 64-bit architectures) and in the case of SpiderMonkey, doubles (real numbers) are represented by 8 bytes (64 bits) while all other JS::Values (pointers, integers, characters, etc.) have around the lower 4 bytes for their value while the remaining upper bytes are used for a tag that indicates their type.
Looking at the source code of SpiderMonkey, you can find the bytes used to build the tags that identify each type of jsval:

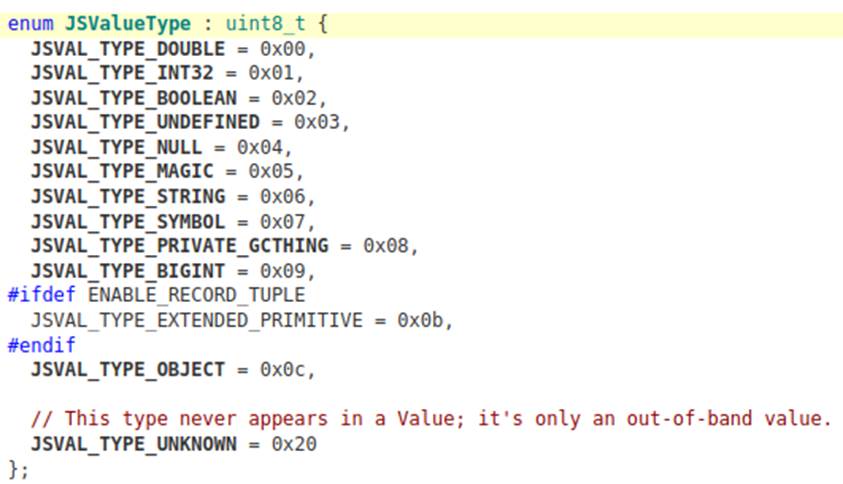
An interesting observation is that the JSVAL_TAG_MAX_DOUBLE tag provides a maximum value for doubles. Doing the operation 0x1fff0 << 47 gives 0xfff80000000000000000 and any value larger than this is not considered a double.
The concept behind this kind of tagged encoding, used by some engines like SpiderMonkey and JavaScriptCore, is called “NaN-Boxing”.
NaN-Boxing
NaN-Boxing is a strategy used to store JS::Values in memory with tags that identify their types. In this way, arrays and variables can be generic, storing several different types (the types are identified by the tags of each item).
In the case of arrays, several types can be stored simultaneously, as long as every element is NaN-boxed. The values will not be boxed only if certain JS structures are used, such as typed arrays (Uint8Array, Float64Array, etc.). In this case, the structure indicates that only values of a certain type are stored and thus they don’t need to be NaN-Boxed in memory.
In Firefox, the upper 17 bits of the values (all total 64 bits) represent the tag (which is the type of the jsval). Therefore, to extract the type of a JS::Value in memory, just right-shift it (e.g. jsval >> 47). The lower 47 bits refer to the jsval value, and similarly can be extracted by applying a mask on them (e.g. jsval & (2^47 – 1)).
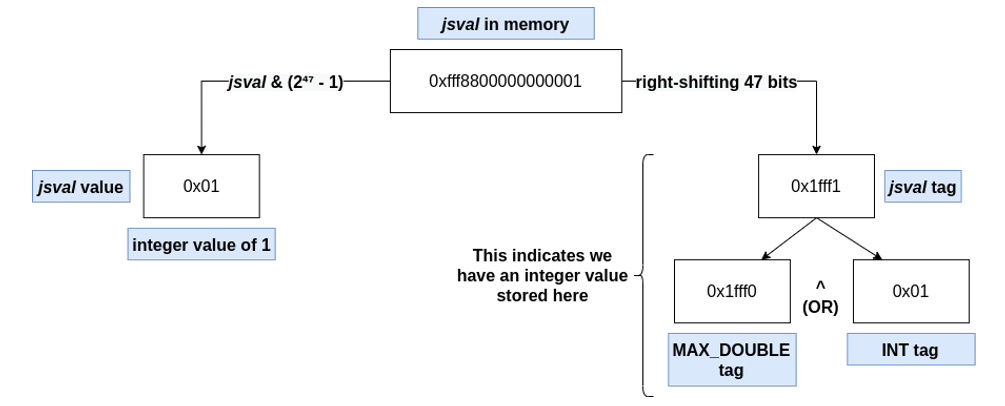
Arrays, objects and memory buffers
To the warriors who continue reading with me, now that we understand the basics about the simpler types present in SpiderMonkey, we will move on to some more complex ones: objects, arrays, and memory buffers.
I recommend grabbing a cup of coffee, putting on some music to help you focus, stretching, and whatever else you find interesting because now we start to get into a complicated but fundamental part of understanding the layout of Javascript elements in memory.
JSObjects and NativeObjects
SpiderMonkey makes use of a structure (class) called JSObject to represent most objects in JavaScript. Most of these JSObjects are also NativeObjects (which is a subtype of JSObject) and this allows the object properties to be stored in a map with key-value pairs (similar to a hash table).
These objects (JSObject), in general, are composed of several “smaller” elements that fulfill different functions within the object. These are:
- group_: ObjectGroup carries information about a group of objects. The clasp_ field describes the group’s class (pointer), which is a JSClass, which has a ClassOps element, which has pointers to functions that control how properties are added, deleted, etc.; [8 bytes]
- shapes_: contains the index (in slots_), name, and more of each property; [8 bytes]
- slots_: pointer to a list referring to the object’s properties (named properties); contains the values of the properties; [8 bytes]
- elements_: pointer to a list of indexed elements of the array. Only some objects have indexed elements (e.g. obj[0]); [8 bytes]
- flags: special conditions of the array; [4 bytes]
- initialized_length: amount of initialized elements (allocated and stored values) in the array; [4 bytes]
- capacity: allocated space for storing the elements; [4 bytes]
- length: size of the array. [4 bytes]
All these components are stored sequentially, and some of them are pointers (*) to other memory regions:

Of all these elements, the two most complex are those that are referenced by group_* and shape_*. The first refers to an ObjectGroup and the second to a Shape.
ObjectGroup
As already mentioned, the ObjectGroup carries information about a group of objects. This information is especially relevant for certain code optimization strategies. Among the most important data present in ObjectGroup are:
- clasp_ *: pointer to an object of type JSClass, which acts as a vtable to enable other APIs to perform property lookup, control certain JSObject behaviors, and more. For example, JSClass has a pointer to an element of type ClassOps, which has pointers to functions that control how properties are added, deleted, and more;
- proto_ *: pointer to a memory region that allows you to identify which object (parent) the current JSObject was derived from;
realm_ *: pointer to information related to dynamic memory allocation regions (heaps).
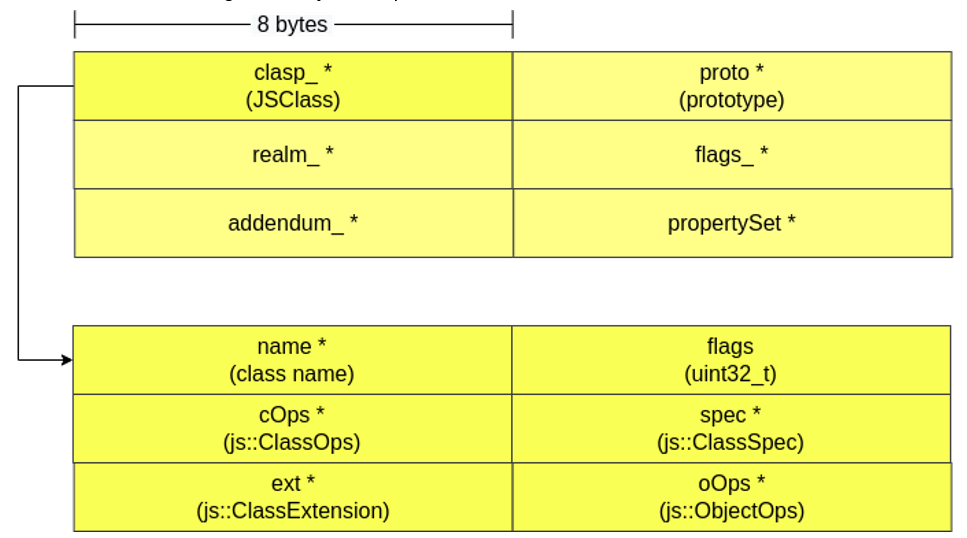
Shape
The Shape describes the properties of each named property/element of the object, such as whether they are enumerable, writable and configurable, and also provides information about names and offsets in the slot array.
In JSObjects, there is a linked list of Shapes, where one Shape points to another via a field called parent. Each Shape is responsible for describing a single property of the object. To better understand all this description, follow the images below.
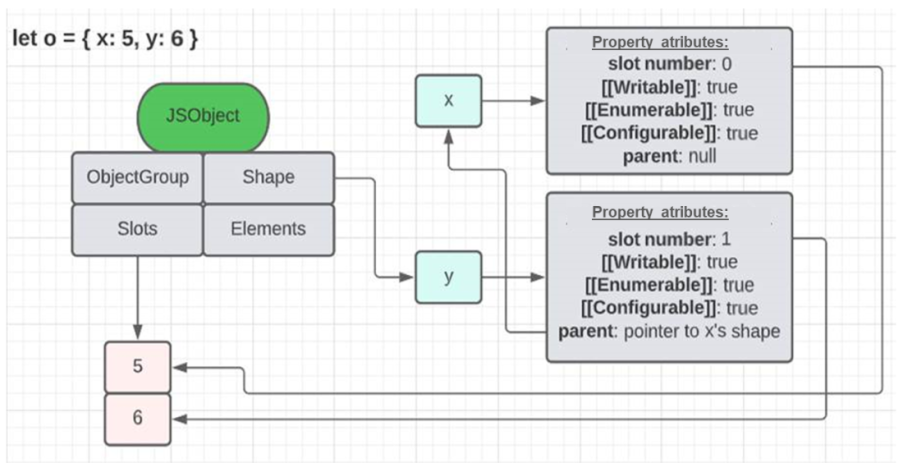
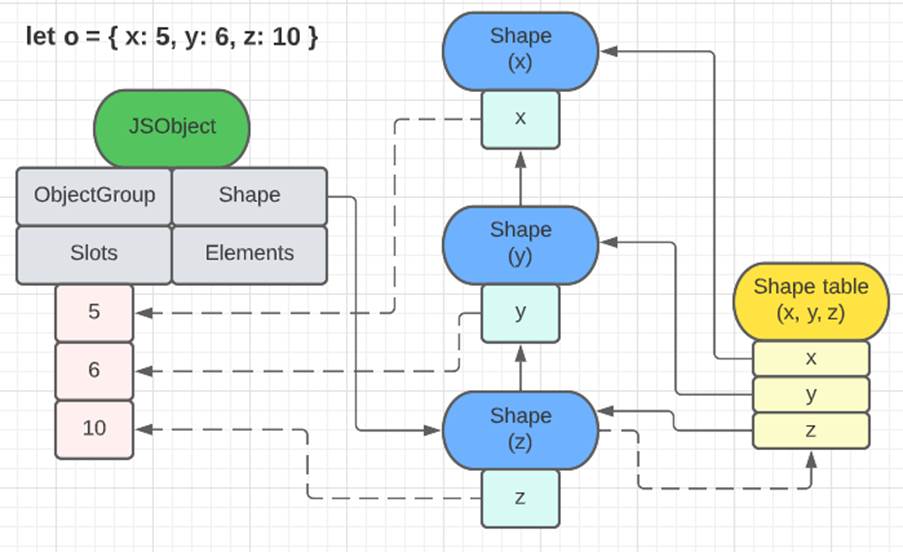
The first image shows how an object with two named properties organizes its elements. The list of shapes brings the information of the properties names (‘x’ and ‘y’) and also points to the memory region where the values of each one of them are (in slots). The second image, besides serving as another example to demonstrate the relationship between shapes, JS objects and slots, also shows the shape table. This structure, in fact, exists and serves to avoid going through the entire list of shapes of an object to find a certain property. Like ObjectGroups, this structure is fundamental for some optimization strategies, such as the use of caches.
TypedArrays
A structure very similar to JSOBject is TypedArray. Objects of this class are arrays that access a data buffer of a specific type (Uint8, Uint32, Float64 etc.). This allows the manipulation of “raw” data in memory – just like arrays in C – so a Uint32Array gives access to “raw” data “uint32_t” and a “Uint8Array” gives access to `uint8_t` data for example. Because of this property, data in TypedArrays are not Nan-Boxed.
The memory structure of a TypedArray is very similar to that of a JSObject, because both are NativeObjects. Besides pointers to group_, shape_, slots_ and elements_, TypedArrays have a pointer to an ArrayBuffer that stores the values inside the array, the size of the array (if the ArrayBuffer is 0x20 bytes long and we have a Uint32Array, then length = 0x20/4 = 8), the offset when accessing the data buffer and a pointer to this data buffer (“raw” format). It is worth noting that TypedArray will use either the pointer to the array buffer or the pointer to the data buffer depending on how it was created (whether or not a previously instantiated buffer was passed when creating the TypedArray).
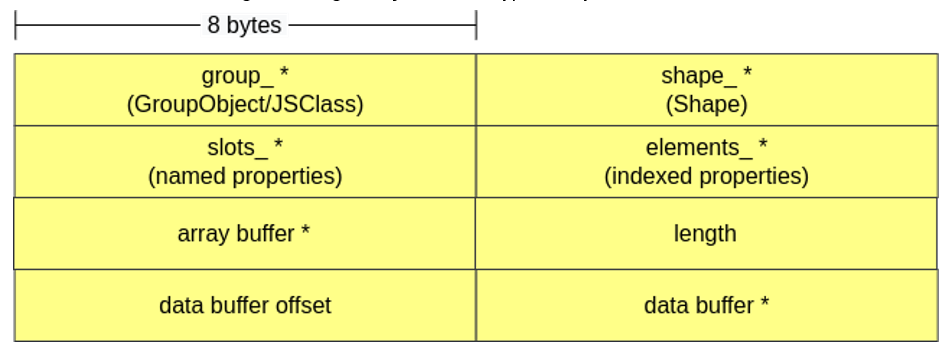
ArrayBuffer and ArrayBufferObject
ArrayBufferObject is an object type used to represent a buffer of raw data. It has a buffer of data called the ArrayBuffer, which can only be manipulated through a DataView or a TypedArray.
Again, objects of this class are also similar to JSObjects and inherit from NativeObject. The ArrayBufferObject has a pointer to the data buffer (Array Buffer), the size of the buffer, a pointer to the first “view” that references the current ArrayBuffer and some flags.
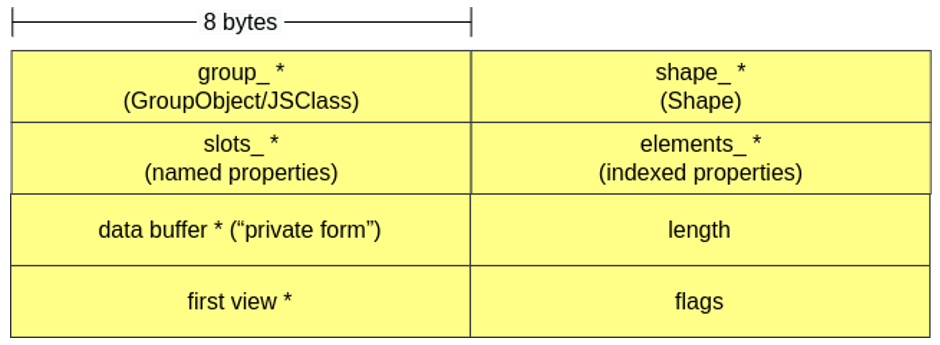
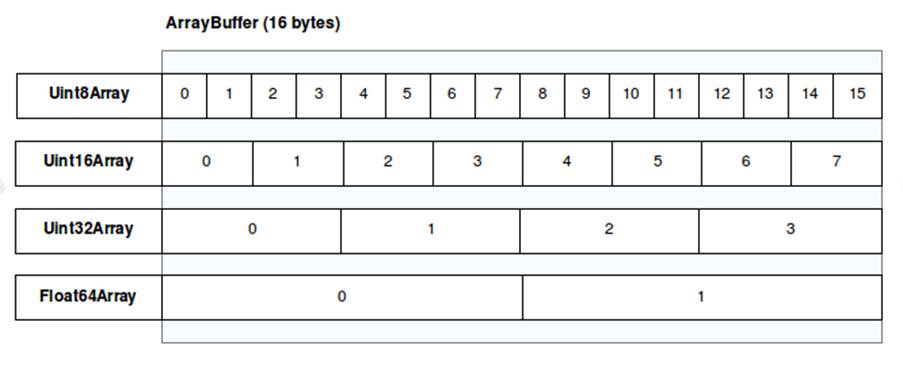
It is possible to have more than one view associated with the same buffer, meaning that the same region of memory can be viewed and manipulated in different ways according to the view that is being used. For example, a Uint32Array(buffer) and a Uint8Array(buffer) that read the same buffer perform different amounts of byte readings at a time (here both interpret the bytes as integers, but this would not necessarily be the case):
const buffer = new ArrayBuffer(8); // c creating an 8 byte buffer const unit8view = new Uint8Array(buffer); // 1 byte per element const unit32view = new Uint32Array(buffer); // 4 bytes per element unit8view[0] = 0xAA; unit8view[1] = 0xBB; unit8view[2] = 0xCC; unit8view[3] = 0xDD; console.log(unit32view[0].toString(16)); // output = ddccbbaa
In the following image, you can get a better understanding of this idea of views and buffers. Each view is represented by a TypedArray, while there is a single shared data buffer, which is 16 bytes long and is divided and interpreted differently in each view.
Final Considerations & Next Steps
With all this information, it’s already possible to understand much better the Javascript structures in memory during code execution in browsers or in any other program that makes use of the most famous JS interpreters, such as Firefox, Google Chrome, Internet Explorer, and Safari. For the more curious people, I highly recommend trying to “play” with SpiderMonkey’s Javascript shell from the code found here to visualize everything that was talked about in this post and really make the connection from theory to practice.
I know there is a lot to digest all at once, so we’ll end this post here. Now is a good time to sit on the balcony of your house, staring at nothing, and reflect on everything that has been presented so far – because it is not over yet!
I hope you found it interesting and useful in understanding the basics of how SpiderMonkey (and Javascript engines in general) work.
In the next post, all the knowledge passed here will be applied to understand and exploit a memory corruption vulnerability from a type inference problem during optimization processes. This flaw was found in SpiderMonkey, reported in 2019 to Mozilla, and registered as CVE-2019-9813 shortly after. See you there!
Some good references
Finally, I would like to leave some of the references that were used both for creating this blog post and for conducting the research on CVE 2019-9813 within Tempest:
Groß, S. (“saelo”). Attacking JavaScript Engines – A case study of JavaScriptCore and CVE-2016-4622. Available at: http://www.phrack.org/issues/70/3.html. Accessed on: 01/12/2022.
“argp”. OR’LYEH? The Shadow over Firefox. Available at: http://www.phrack.org/issues/69/14.html. Accessed on: 01/12/2022.
CHEN, B. Learning browser exploitation via 33C3 CTF feuerfuchs challenge. Disponível em: https://bruce30262.github.io/Learning-browser-exploitation-via-33C3-CTF-feuerfuchs-challenge. Accessed on: 01/12/2022.
DEVILLERS, N. (“NK”); GARNIER, J.R. (“JRomainG”); RIGO, R. (“_trou_”). Introduction to SpiderMonkey exploitation. Available at: https://doar-e.github.io/blog/2018/11/19/introduction-to-spidermonkey-exploitation/. Accessed on: 01/12/2022.
RAO, V. S (“sherl0ck”). SpiderMonkey Workflow Setup. Available at: https://vigneshsrao.github.io/posts/workflow/. Accessed on: 01/12/2022.
RAO, V. S (“sherl0ck”). Write up for CVE-2019-11707. Accessed on: 01/12/2022.
RAO, V. S (“sherl0ck”). Playing around with SpiderMonkey. Available at: https://vigneshsrao.github.io/posts/play-with-spidermonkey/. Accessed on: 01/12/2022.
GERKIS, A.; BARKSDALE, D. Exodus Blog: Firefox Vulnerability Research. Available at: https://blog.exodusintel.com/2020/10/20/firefox-vulnerability-research/. Accessed on: 01/12/2022.
AMERONGEN, M. V. Exploiting CVE-2019-17026 – A Firefox JIT Bug. Available at: https://labs.f-secure.com/blog/exploiting-cve-2019-17026-a-firefox-jit-bug/. Accessed on: 01/12/2022.
“Rh0”. The Return of the JIT (Part 1). Available at: https://rh0dev.github.io/blog/2017/the-return-of-the-jit/. Accessed on: 01/12/2022.
“Rh0”. More on ASM.JS Payloads and Exploitation. Available at: https://rh0dev.github.io/blog/2018/more-on-asm-dot-js-payloads-and-exploitation/. Accessed on: 01/12/2022.
FALCON, F. Exploiting MS16-145: MS Edge TypedArray.sort Use-After-Free (CVE-2016-7288). Available at: https://blog.quarkslab.com/exploiting-ms16-145-ms-edge-typedarraysort-use-after-free-cve-2016-7288.html. Accessed on: 01/12/2022.
Mozilla Foundation. js/src – mozsearch. Available at: https://searchfox.org/mozilla-central/source/js/src. Accessed on: 01/12/2022.
RODRIGUES, D. (“mdanilor”). Understanding binary protections (and how to bypass) with a dumb example. Available at: https://mdanilor.github.io/posts/memory-protections/. Accessed on: 01/12/2022.
Mozilla Foundation. SpiderMonkey – Firefox Source Docs. Available at: https://firefox-source-docs.mozilla.org/js/index.html. Accessed on: 01/12/2022.
Groß, S. (“saelo”). IonMonkey compiled code fails to update inferred property types, leading to type confusions. Available at: https://bugzilla.mozilla.org/show_bug.cgi?id=1538120. Accessed on: 01/12/2022.
GAYNOR, A. ZDI-CAN-8373: Initial code execution: Type confusion in IonMonkey optimizer. Available at: https://bugzilla.mozilla.org/show_bug.cgi?id=1538006. Accessed on: 01/12/2022.
Mozilla Foundation. SpiderMonkey Internals. Available at: https://web.archive.org/web/20210416214709/https://developer.mozilla.org/en-US/docs/Mozilla/Projects/SpiderMonkey/Internals. Accessed on: 01/12/2022.