Nesse post, iremos entender conceitos básicos de Browser Exploitation, focando na engine de Javascript do navegador Firefox, o SpiderMonkey. Será feita uma introdução a temas como heaps, garbage collector, primitivas e objetos, estruturas em memória, interpretadores e compiladores JIT e, o mais importante, caminhos para explorar falhas de corrupção de memória em engines de Javascript.
Antes de começarmos, duas informações importantes:
- os conceitos aqui apresentados usam como base o SpiderMonkey na versão 66.0.3, com algumas referências ao código-fonte em mozilla-central, acessado em setembro de 2022. Logo, é possível que pequenas diferenças sejam encontradas em outras versões da engine;
- esse post é bem técnico e, consequentemente, um pouco complexo, mas não desanime. Se você tem interesse em engenharia reversa, navegadores web, bugs de corrupção de memória ou cibersegurança no geral, o texto vai valer a pena.
Vamos então ao que interessa!
Engines de Javascript e o SpiderMonkey
Para começar, é possível afirmar que as principais JS engines do mercado (SpiderMonkey, V8, JavaScriptCore e Chakra) possuem uma estrutura básica. Ela é composta por:
- uma infraestrutura de compiladores (com um ou mais Just In Time compilers¹);
- uma máquina virtual que opera JS values e que possui um interpretador de bytecode;
- um runtime que fornece um conjunto de objetos e funções nativas.
A quantidade de compiladores e interpretadores pode ser diferente em cada engine. Contudo, em geral, tem-se ao menos o interpretador de bytecode, o compilador JIT de primeiro estágio, que remove parte do overhead vindo do interpretador e algum outro compilador JIT que realiza otimizações mais pesadas – baseadas, muitas vezes, em especulações.
Nesse contexto, vale mencionar que as funções do Javascript são otimizadas com base no quão “quente” elas estão. A cada chamada que recebem, elas se tornam mais e mais quentes até que a engine opta por otimizar o código a fim de diminuir o tempo de execução da função (pois ela está sendo executada muitas vezes).
No caso do SpiderMonkey, temos os seguintes (JIT) compilers/interpreters: Baseline Interpreter, Baseline JIT e IonMonkey (este último atualmente é chamado de WarpMonkey, mas desconsidere isso para esse texto).
Just In Time Compiler (JIT) é a estratégia de execução de código que envolve compilação durante a execução do programa (runtime). Comumente, isso ocorre por meio da conversão de bytecode para código de máquina, o qual é efetivamente executado.
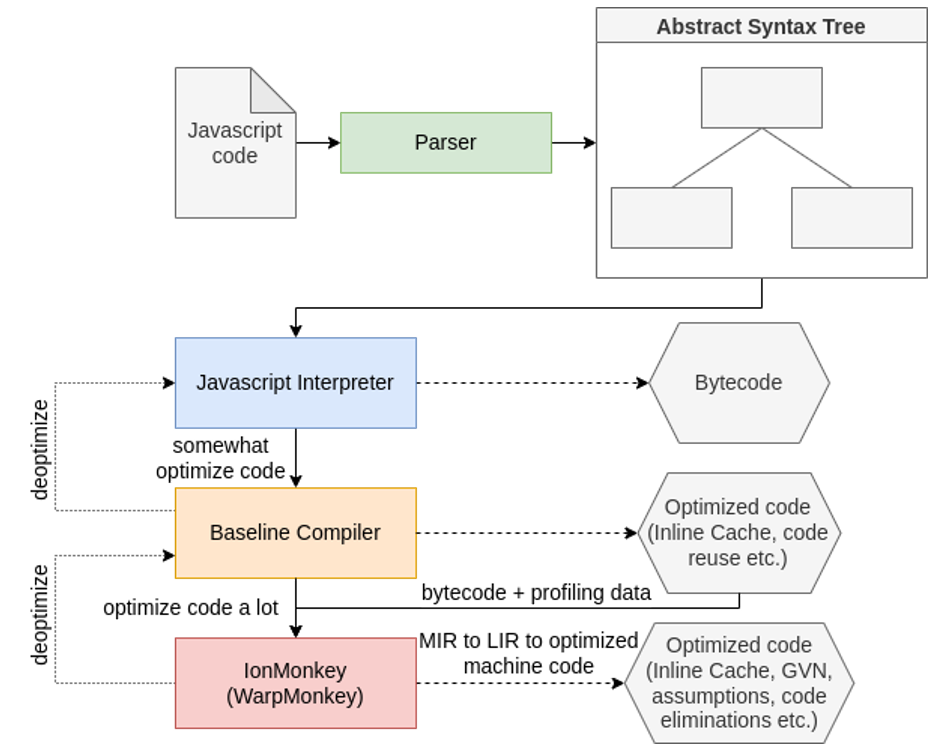
De forma breve, é possível descrever cada componente acima da seguinte forma:
- JS Interpreter: interpreta o bytecode vindo do parser (código em Javascript é transformado em código intermediário e então em bytecode);
- Baseline JIT compiler: compilador just-in-time que faz algumas otimizações simples, por exemplos usando inline cache e reutilizando código;
- IonMonkey: compilador just-in-time que realiza as otimizações mais pesadas. Transforma código JS em código compilado.
Um pouco mais sobre o IonMonkey
O IonMonkey, como já foi falado, realiza as otimizações mais pesadas do SpiderMonkey. Essas otimizações são baseadas nos dados e argumentos que são processados a cada chamada do código. A otimização assume que esse código continuará a ver dados similares ao que viu antes e usa essas suposições para criar uma versão compilada (código de máquina) do trecho executado (e agora otimizado).
No caso de uma função que é executada muitas e muitas vezes, faz sentido gastar um tempo extra gerando uma versão compilada e otimizada do código, pois, nas execuções subsequentes, a função será mais eficiente/rápida.
Os passos realizados pelo IonMonkey para realizar otimizações de código são:
- Middle-level Intermediate Representation (MIR) Generation: transforma bytecode em nós de IR, usados em CFGs (Control Flow Graphs);
- Optimisation: são identificadas formas de otimização com base nos nós MIR. Algumas estratégias são: Alias Analysis, Global Value Numbering, Constant Folding, Unreachable Code Elimination, Dead Code Elimination e Bounds Check Elimination;
- Lowering: transforma-se o código MIR em LIR (depende de arquitetura);
- Code generation: gera-se código de máquina a partir do LIR. O linking do código de máquina é feito ao atribuí-lo a uma região de memória executável em adição a um conjunto de suposições para as quais o código JIT é válido.
Primitivas e tipos de objetos
Se você chegou até aqui na leitura, deve saber que Javascript é uma linguagem dinâmica e orientada a objetos, ou seja, os tipos de variáveis são determinados em tempo de execução e um programa em JS é uma coleção de objetos que se comunicam.
Esses objetos são coleções de zero ou mais propriedades as quais possuem atributos para definir como cada um deles deve ser usado (Writable, Readable etc.). As propriedades são contêineres que armazenam objetos, primitivas ou funções (que também são objetos).
Outra característica importante é que no Javascript não há o conceito de classes. Ao invés disso, utiliza-se herança baseada em protótipos (prototype-based-inheritance). Os objetos fazem referência (possivelmente nulas) a protótipos cujas propriedades eles incorporam. Dessa forma, é possível compartilhar propriedades e métodos entre objetos.
Os tipos que as variáveis podem assumir seguem o que está determinado no “ECMAScript Language Specification”, são eles tipos primitivos (Undefined, Null, Boolean, Number, BigInt, String, e Symbol) ou objetos (funções, arrays etc.).
JS::Values
Na seção anterior, os tipos que uma propriedade ou variável assumem foram brevemente mencionados. Todavia, para entendê-los no nível de profundidade que queremos, é necessário entender sobre JS::Values.
O SpiderMonkey utiliza variáveis chamadas de JS::Values (as vezes descritos somente como jsvals) para representar strings, números inteiros e de ponto flutuante, objetos (incluindo arrays e funções), booleanos e valores especiais como null e undefined.
Cada JS::Value possui 8 bytes (cabem em registradores de arquiteturas 64-bit) e, no caso do SpiderMonkey, os valores de doubles (números reais) são representados por 8 bytes (64 bits) enquanto todos os outros JS::Values (ponteiros, inteiros, caracteres etc.) possuem por volta dos 4 bytes inferiores para seu valor enquanto os bytes superiores restantes são usados para uma tag que indica seu tipo.
Analisando o código-fonte do SpiderMonkey, é possível encontrar os bytes usados para construir as tags que identificam cada tipo de jsval:
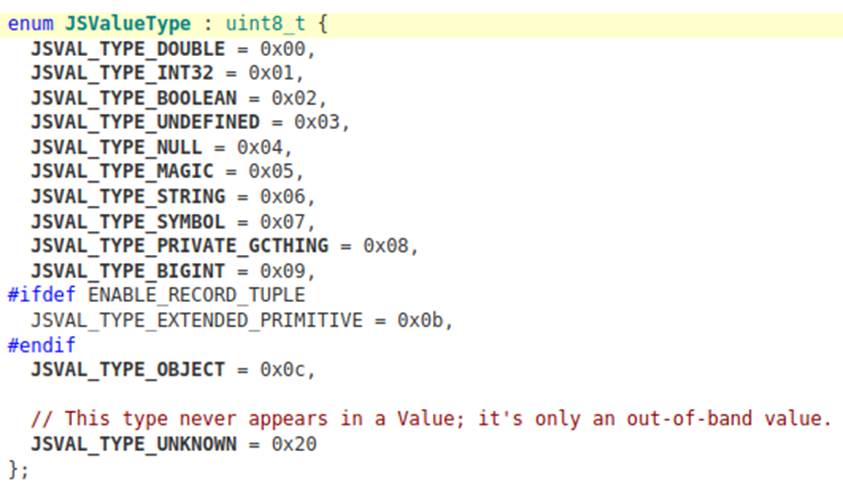

Uma observação interessante é que a tag JSVAL_TAG_MAX_DOUBLE fornece um valor máximo para doubles. Fazendo a operação 0x1fff0 << 47, obtemos 0xfff8000000000000 e qualquer valor maior que isso não é considerado um double.
O conceito por trás desse tipo de codificação com tags, utilizada por algumas engines como o SpiderMonkey e o JavaScriptCore, é chamado de “NaN-Boxing”.
NaN-Boxing
NaN-Boxing é uma estratégia utilizada para armazenar JS::Values em memória com tags que identificam seus tipos. Dessa forma, arrays e variáveis podem ser genéricos, armazenando vários tipos diferentes (os tipos são identificados pelas tags de cada item).
No caso dos arrays, vários tipos podem ser armazenados simultaneamente, basta que todo elemento seja NaN-boxed. Os valores só não sofrem esse boxing caso sejam utilizadas certas estruturas do JS, como typed arrays (Uint8Array, Float64Array etc.). Nesse caso, a estrutura indica que só são armazenados valores de determinado tipo e, assim, eles não precisam ser NaN-Boxed em memória.
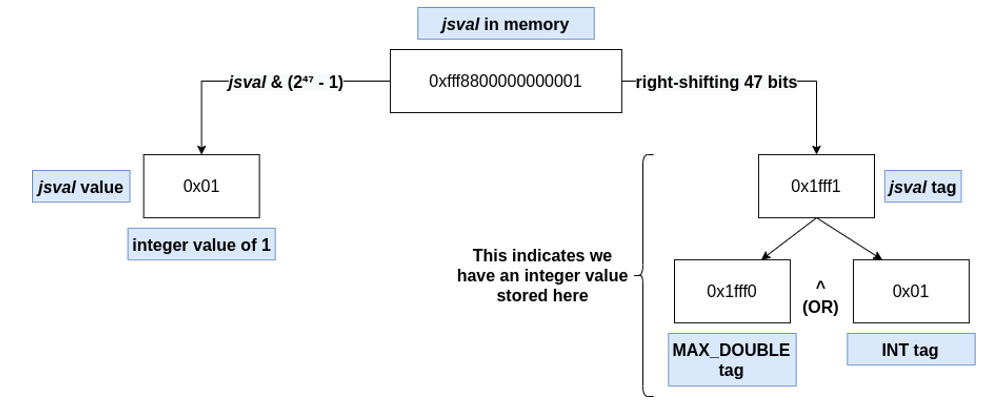
No Firefox, os 17 bits superiores dos valores (todos com total de 64 bits) representam a tag (que é o tipo do jsval). Portanto, para extrair o tipo de um JS::Value em memória, basta fazer um right-shift nele (ex.: jsval >> 47). Os 47 bits inferiores são referentes ao valor do jsval e, de forma similar, podem ser extraídos ao aplicar uma máscara neles (ex.: jsval & (2^47 – 1)).
Arrays, objetos e buffers de memória
Aos guerreiros e guerreiras que continuam comigo nessa leitura, agora que entendemos o básico sobre os tipos mais simples presentes no SpiderMonkey, iremos passar para alguns mais complexos: objetos, arrays e buffers de memória.
Recomendo pegar um cafezinho, colocar uma música para ajudar no foco, alongar-se e o que mais você achar interessante, porque agora começamos a entrar em uma parte complicada, mas fundamental para entender a disposição dos elementos do Javascript em memória.
JSObjects e NativeObjects
O SpiderMonkey faz uso de uma estrutura (classe) chamada JSObject para representar a maioria dos objetos no Javascript. A maioria desses JSObjects também são NativeObjects (que é um subtipo do JSObject) e isso permite que as propriedades do objeto sejam guardadas em uma mapa com pares chave-valor (similar a uma hash table).
Esses objetos (JSObject), em geral, são compostos por vários elementos “menores” e que cumprem funções diferentes dentro do objeto. São eles:
- group_: ObjectGroup traz informações sobre um grupo de objetos. O campo clasp_ descreve a classe do grupo (ponteiro), que é uma JSClass, a qual possui um elemento ClassOps, o qual possui ponteiros para as funções que controlam como propriedades são adicionadas, deletadas etc.; [8 bytes]
- shapes_: contém o índice (em slots_), o nome e mais de cada propriedade; [8 bytes]
- slots_: ponteiro para uma lista referente às propriedades do objeto (named properties); contém os valores das propriedades; [8 bytes]
- elements_: ponteiro para uma lista com os elementos indexados (indexed elements) do array. Somente alguns objetos têm elementos indexados (ex.: obj[0]); [8 bytes]
- flags: condições especiais do array; [4 bytes]
- initialized_length: quantidade de elementos inicializados (valores alocados e armazenados) no array; [4 bytes]
- capacity: espaço alocado para armazenamento dos elementos; [4 bytes]
- length: tamanho do array. [4 bytes]
Todos esses componentes são armazenados sequencialmente, sendo que alguns deles são ponteiros (*) para outras regiões de memória:

De todos esses elementos, os dois mais complexos são aqueles que são referenciados por group_* e shape_*. O primeiro refere-se a um ObjectGroup e o segundo a um Shape.
ObjectGroup
Como já foi mencionado, o ObjectGroup traz informações sobre um grupo de objetos. Essa informação é especialmente relevante para certas estratégias de otimização de código. Dentre os dados mais importantes presentes no ObjectGroup estão:
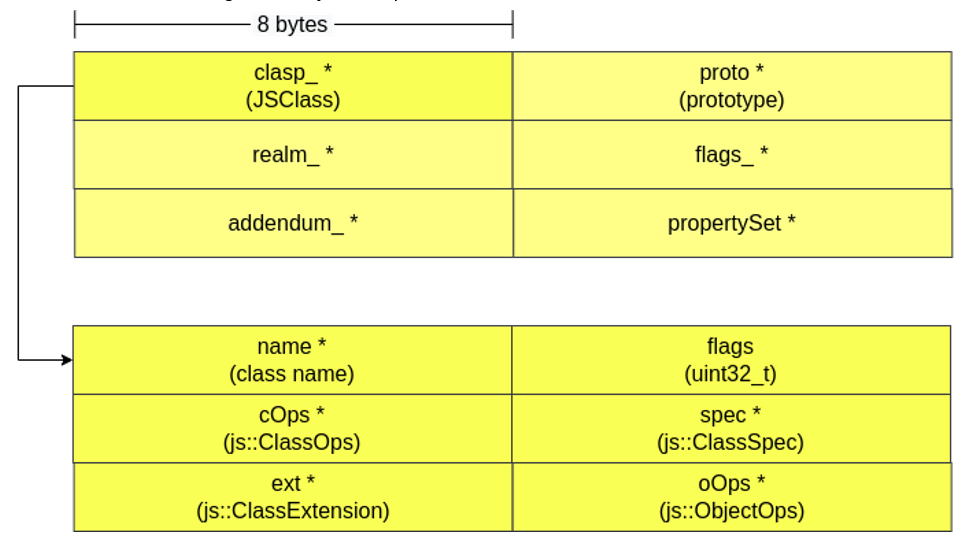
- clasp_ *: ponteiro para um objeto do tipo JSClass, o qual atua como uma vtable para que seja possível outras APIs realizarem lookup de propriedades, controle de certos comportamentos do JSObject e mais. Por exemplo, a JSClass possui um ponteiro para um elemento do tipo ClassOps, o qual possui ponteiros para as funções que controlam como propriedades são adicionadas, deletadas etc.;
- proto_ *: ponteiro para uma região de memória que permite identificar qual o objeto (pai) de onde o JSObject atual foi derivado;
- realm_ *: ponteiro para informações relacionadas às regiões de alocação de memória dinâmica (heaps).
Shape
Já o Shape descreve as propriedades de cada named property/element do objeto, como se eles são enumerable, writable e configurable e, também, traz informações sobre nomes e offsets no vetor de slots.
Nos JSObjects, tem-se uma linked list de Shapes, sendo que um Shape aponta outro via um campo chamado parent. Cada Shape é responsável por descrever uma única propriedade do objeto. Para entender melhor toda essa descrição, acompanhe as imagens a seguir.
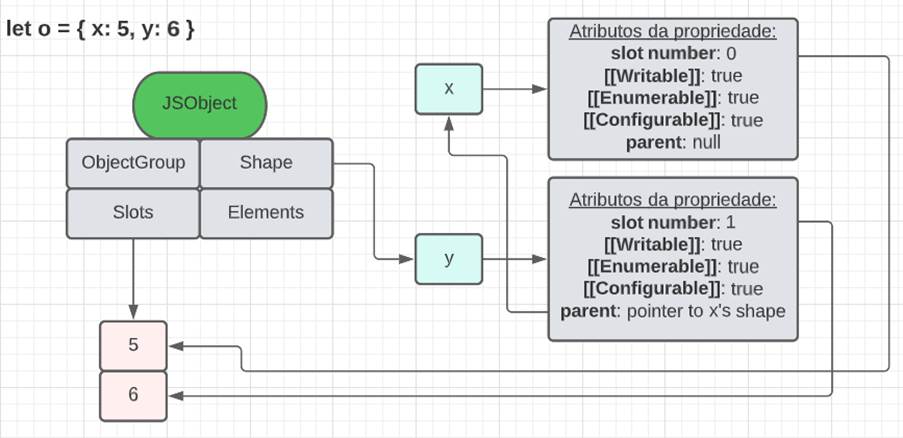
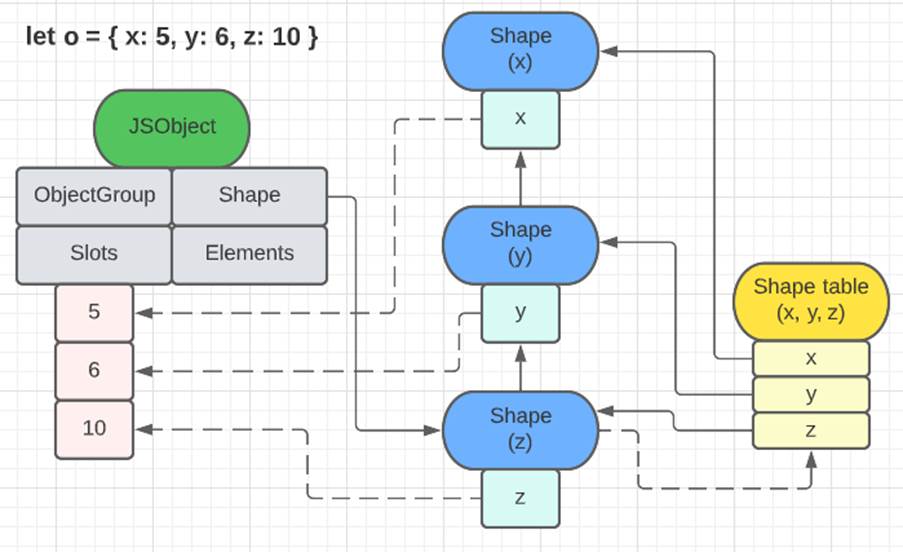
A primeira imagem mostra como um objeto com duas propriedades (named properties) organiza seus elementos. A lista de shapes traz as ĩnformações de nome das propriedades (‘x’ e ‘y’) e também aponta para a região de memória onde estão os valores de cada uma delas (em slots). Já a segunda imagem, além de servir como outro exemplo para demonstrar a relação entre shapes, JS objects e slots, também apresenta a shape table. Essa estrutura, de fato, existe e serve para evitar percorrer a lista completa de shapes de um objeto para encontrar determinada propriedade. Assim como os ObjectGroups, essa estrutura é fundamental para algumas estratégias de otimização, como o uso de caches.
TypedArrays
Uma estrutura bem similar ao JSOBject é o TypedArray. Objetos dessa classe são arrays que acessam um buffer de dados de um tipo específico (Uint8, Uint32, Float64 etc.). Isso permite a manipulação de dados “crus” na memória – assim como ocorre em arrays em C –, então um Uint32Array dá acesso a dados “raw” “uint32_t” e um “Uint8Array” dá acesso a dados `uint8_t` por exemplo. Devido a essa propriedade, os dados em TypedArrays não possuem Nan-Boxing.
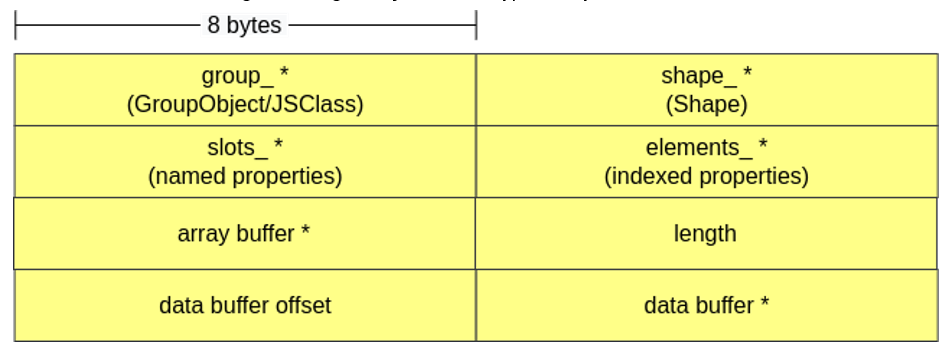
A estrutura em memória de um TypedArray é bem semelhante a de um JSObject, pois ambos são NativeObjects. Além dos ponteiros para group_, shape_, slots_ e elements_, os Typed Arrays possuem um ponteiro para um ArrayBuffer que armazena os valores dentro do array, o tamanho do array (se o ArrayBuffer tem 0x20 bytes e temos um Uint32Array, então length = 0x20/4 = 8), o offset ao acessar o buffer de dados e um ponteiro para esse buffer de dados (formato “raw”). Vale destacar que TypedArray utilizará o ponteiro para o array buffer ou o ponteiro para o data buffer a depender de como ele foi criado (se foi passado ou não um buffer previamente instanciado ao criar o TypedArray).
ArrayBuffer e ArrayBufferObject
ArrayBufferObject é um tipo de objeto usado para representar um buffer de dados “crus” (raw data). Ele possui um buffer de dados chamado de ArrayBuffer, o qual só pode ser manipulado através de um DataView ou um TypedArray.
Novamente, objetos dessa classe também são similares aos JSObjects e herdam de NativeObject. O ArrayBufferObject possui um ponteiro para o buffer de dados (Array Buffer), o tamanho do buffer, um ponteiro para a primeira “view” que referencia o ArrayBuffer atual e algumas flags.
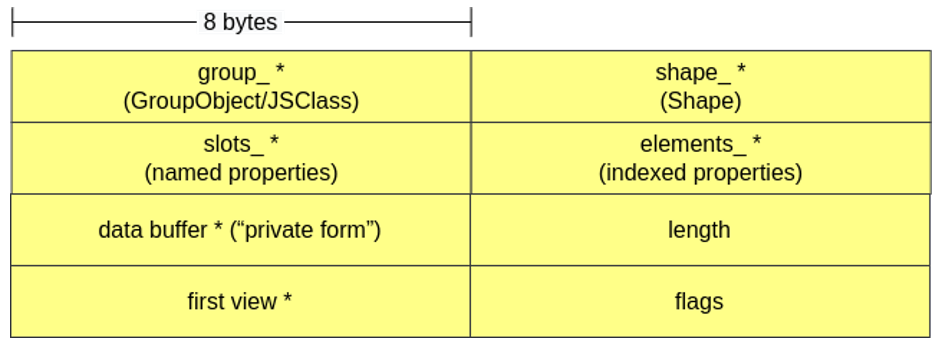
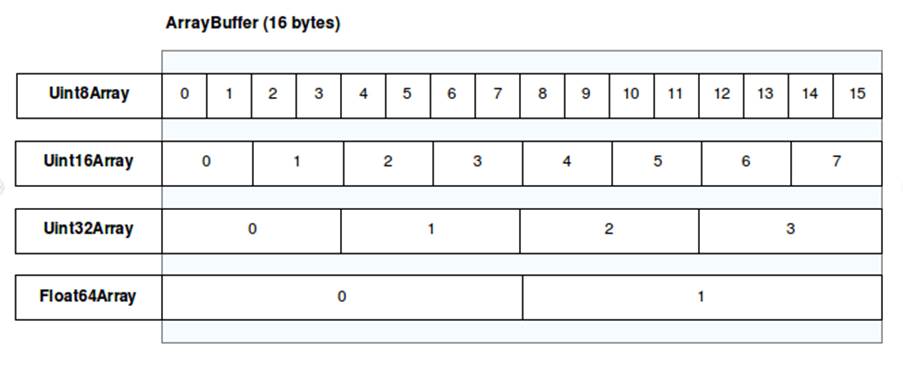
É possível haver mais de uma view associada ao mesmo buffer, ou seja, a mesma região de memória pode ser visualizada e manipulada de formas diferentes de acordo com a view que está sendo utilizada. Por exemplo, um Uint32Array(buffer) e um Uint8Array(buffer) que leem o mesmo “buffer” fazem leituras de quantidades diferentes de bytes por vez (aqui ambos interpretam os bytes como inteiros, mas esse poderia não ser o caso):
const buffer = new ArrayBuffer(8); // criando um buffer de 8 bytes const unit8view = new Uint8Array(buffer); // 1 byte por elemento const unit32view = new Uint32Array(buffer); // 4 bytes por elemento unit8view[0] = 0xAA; unit8view[1] = 0xBB; unit8view[2] = 0xCC; unit8view[3] = 0xDD; console.log(unit32view[0].toString(16)); // output = ddccbbaa
Na imagem a seguir, é possível entender um pouco melhor essa ideia de views e buffers. Cada view é representada por um tipo de TypedArray, enquanto há um único buffer de dados compartilhado, o qual possui 16 bytes e é dividido e interpretado de maneira diferente em cada view.
Considerações finais & Próximos passos
Com todas essas informações, já é possível entender muito melhor as estruturas do Javascript em memória durante a execução de código em navegadores ou em qualquer outro programa que faça uso dos interpretadores de JS mais famosos, como os do Firefox, Google Chrome, Internet Explorer e Safari. Para as pessoas mais curiosas, eu recomendo muito tentar “brincar” com a shell de Javascript do SpiderMonkey, a partir do código encontrado aqui para visualizar tudo que foi falado nesse post e, realmente, fazer a conexão da teoria com a prática.
Sei que há muita coisa para digerir de uma só vez, então iremos finalizar esse post por aqui. É uma boa hora para sentar na varanda de casa, olhar para o nada e refletir sobre tudo que foi apresentado até aqui – porque ainda não acabou!
Espero que a leitura tenha sido interessante e útil para entender o básico sobre o funcionamento do SpiderMonkey (e de engines de Javascript no geral).
Na próxima publicação sobre esse assunto, todo o conhecimento passado aqui será aplicado para que possamos entender e explorar uma vulnerabilidade de corrupção de memória a partir de um problema de inferência de tipos durante processos de otimização. Essa falha foi encontrada no SpiderMonkey, reportada em 2019 para a Mozilla e registrada como CVE-2019-9813 logo em seguida. Nos vemos lá!
Algumas boas referências
Por fim, gostaria de deixar algumas das referências que foram utilizadas tanto para a criação deste blog post quanto para a realização da pesquisa sobre o CVE 2019-9813 dentro da Tempest:
Groß, S. (“saelo”). Attacking JavaScript Engines – A case study of JavaScriptCore and CVE-2016-4622. Disponível em: http://www.phrack.org/issues/70/3.html. Acesso em: 01/12/2022.
“argp”. OR’LYEH? The Shadow over Firefox. Disponível em: http://www.phrack.org/issues/69/14.html. Acesso em: 01/12/2022.
CHEN, B. Learning browser exploitation via 33C3 CTF feuerfuchs challenge. Disponível em: https://bruce30262.github.io/Learning-browser-exploitation-via-33C3-CTF-feuerfuchs-challenge. Acesso em: 01/12/2022.
DEVILLERS, N. (“NK”); GARNIER, J.R. (“JRomainG”); RIGO, R. (“_trou_”). Introduction to SpiderMonkey exploitation. Disponível em: https://doar-e.github.io/blog/2018/11/19/introduction-to-spidermonkey-exploitation/. Acesso em: 01/12/2022.
RAO, V. S (“sherl0ck”). SpiderMonkey Workflow Setup. Disponível em: https://vigneshsrao.github.io/posts/workflow/. Acesso em: 01/12/2022.
RAO, V. S (“sherl0ck”). Write up for CVE-2019-11707. Disponível em: https://vigneshsrao.github.io/posts/workflow/. Acesso em: 01/12/2022.
RAO, V. S (“sherl0ck”). Playing around with SpiderMonkey. Disponível em: https://vigneshsrao.github.io/posts/play-with-spidermonkey/. Acesso em: 01/12/2022.
GERKIS, A.; BARKSDALE, D. Exodus Blog: Firefox Vulnerability Research. Disponível em: https://blog.exodusintel.com/2020/10/20/firefox-vulnerability-research/. Acesso em: 01/12/2022.
AMERONGEN, M. V. Exploiting CVE-2019-17026 – A Firefox JIT Bug. Disponível em: https://labs.f-secure.com/blog/exploiting-cve-2019-17026-a-firefox-jit-bug/. Acesso em: 01/12/2022.
“Rh0”. The Return of the JIT (Part 1). Disponível em: https://rh0dev.github.io/blog/2017/the-return-of-the-jit/. Acesso em: 01/12/2022.
“Rh0”. More on ASM.JS Payloads and Exploitation. Disponível em: https://rh0dev.github.io/blog/2018/more-on-asm-dot-js-payloads-and-exploitation/. Acesso em: 01/12/2022.
FALCON, F. Exploiting MS16-145: MS Edge TypedArray.sort Use-After-Free (CVE-2016-7288). Disponível em: https://blog.quarkslab.com/exploiting-ms16-145-ms-edge-typedarraysort-use-after-free-cve-2016-7288.html. Acesso em: 01/12/2022.
Mozilla Foundation. js/src – mozsearch. Disponível em: https://searchfox.org/mozilla-central/source/js/src. Acesso em: 01/12/2022.
RODRIGUES, D. (“mdanilor”). Understanding binary protections (and how to bypass) with a dumb example. Disponível em: https://mdanilor.github.io/posts/memory-protections/. Acesso em: 01/12/2022.
Mozilla Foundation. SpiderMonkey – Firefox Source Docs. Disponível em: https://firefox-source-docs.mozilla.org/js/index.html. Acesso em: 01/12/2022.
Groß, S. (“saelo”). IonMonkey compiled code fails to update inferred property types, leading to type confusions. Disponível em: https://bugzilla.mozilla.org/show_bug.cgi?id=1538120. Acesso em: 01/12/2022.
GAYNOR, A. ZDI-CAN-8373: Initial code execution: Type confusion in IonMonkey optimizer. Disponível em: https://bugzilla.mozilla.org/show_bug.cgi?id=1538006. Acesso em: 01/12/2022.
Mozilla Foundation. SpiderMonkey Internals. Disponível em: https://web.archive.org/web/20210416214709/https://developer.mozilla.org/en-US/docs/Mozilla/Projects/SpiderMonkey/Internals. Acesso em: 01/12/2022.