For those of you who don’t remember me, my name is Gabrielle and I’ve already made another blogpost here at the SideChannel talking a bit about my internship experience and about a Burp plugin to detect reverse tabnabbing. Since then I had my internship contract renewed and spent 6 months deepening even more in application security for the web, for mobiles, and for advanced penetration testing. Just like the first internship, my tutors instructed me to research and make a publication for the closure of my internship. That’s where this blogpost came from.
By the way, at the end of my second internship cycle, Tempest made me a job offer and I, of course, accepted it right away! That means I’m the first employee on the Tempest Consulting team. 😀
Without further ado, let’s get down to business!
For many internet users, browsers have become a fundamental part of our daily lives. Office utility applications, such as Microsoft Office 365, run in the cloud and are accessible through a browser. We can work anytime, anywhere, on the cell phone, tablet or laptop. In some cases, users do not need to install any additional components to access such applications or corporate data, so less work for us, IT professionals! But is that so?
This evolution of technologies has paved the way for great experiences for end users, but has also given malicious agents new means, endpoints and vulnerabilities to exploit in possible attacks. Based on that, in this blog post, we will be dealing specifically with an analysis in five browsers that are used in mobile devices, being them: Google Chrome, Microsoft Edge, Opera, Samsung Internet Browser and Mint Browser. For a better view of the scope of this search, let’s see the table below:
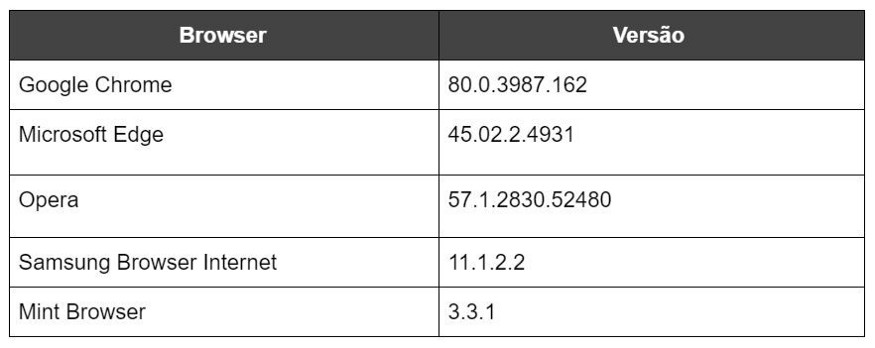
We have brought a graph from January 2019 to March 2020, of the most widely used mobile browsers in the world, to show that an exploitation of some security problem in a browser can have a great impact:
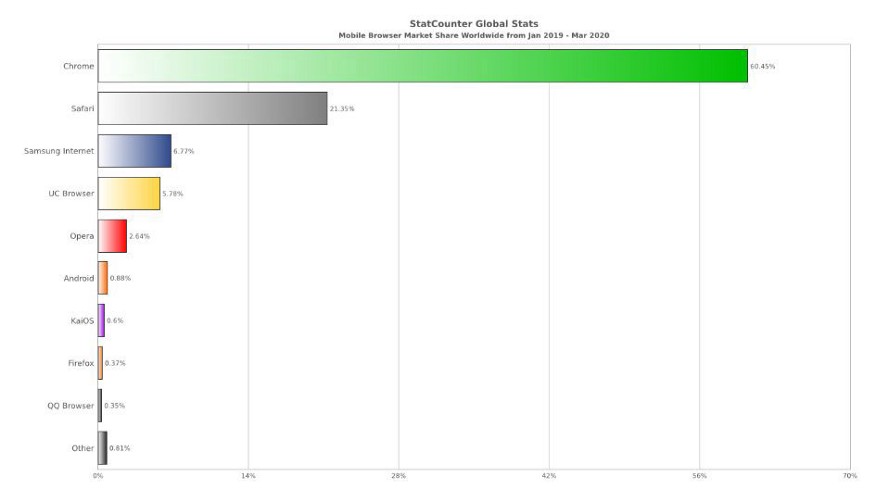
The analysis in this research aims to ascertain the security maturity of the previously mentioned browsers, popular browsers that already come pre-installed on Android devices (cited in Table 1), to assess the fundamental protections and attacks that could easily succeed.
Security Issues
For this search, four types of security problems were selected, being them: the possibility of bypassing the Same Origin Policy, bypassing the Content Security Policy, the Scroll Jail attack and the onslaught of history.back() Open Redirect. The following is a brief description of each of the tests that were performed on the target browsers.
Same Origin Policy Bypass
Same Origin Policy (SOP) is a security mechanism that restricts how a document or script belonging to one source can interact with the content of another source. This helps isolate potential malicious documents and reduce attack vectors.
The first test performed was the attempt to circumvent this protection, using scripts and, based on an X source, accessing resources from a Y source. Below is an example of a script used:
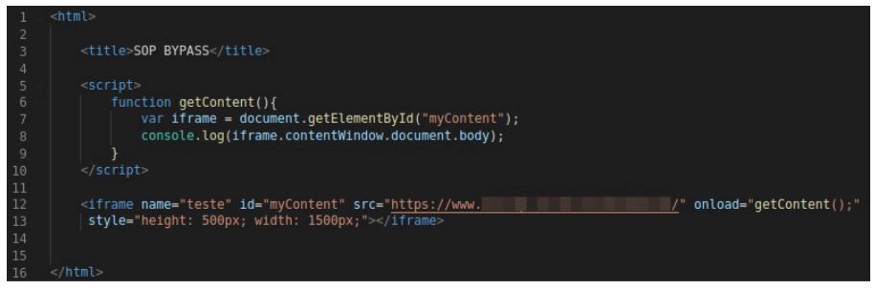
None of the browsers cited in this work ran console.log, so we can assume that they are protected against the method described above.
In addition to the previous example, a test was performed to verify the behavior of browsers when dealing with Cross Origin Resource Sharing (CORS), which is a mechanism in which browsers enable controlled access to resources located outside a given domain by adding fields in the HTTP header which allow servers to define a set of sources that are allowed to read information using the browser. In other words, it extends and adds flexibility to Same Origin Policy. Also, for HTTP requests that can cause side effects on server data (HTTP methods other than GET, or for use of POST with certain MIME types), it is necessary that the browsers “pre-send” a request asking about the methods supported by the server; this is done using the HTTP OPTIONS method and, after “approval”, the server sends the true request with the correct HTTP method; these “pre-send” requests are called Preflight requests.
Understanding how CORS works in theory, let’s see it in practice: The OPTIONS request uses three fields in the HTTP request header, which are the Access-Control-Request-Method, Access-Control-Request-Headers, and the Origin field. If the server allows it, it responds to the preflight request with an Access-Control-Allow-Methods response header field, which lists the methods allowed by the server, in addition to the Access-Control-Allow-Origin, which indicates whether the response resources can be shared with the given source (Origin).
Here follows the example where the domain https://c3415fa3.ngrok.io demands a POST request from another domain, https://usus.serveo.net:
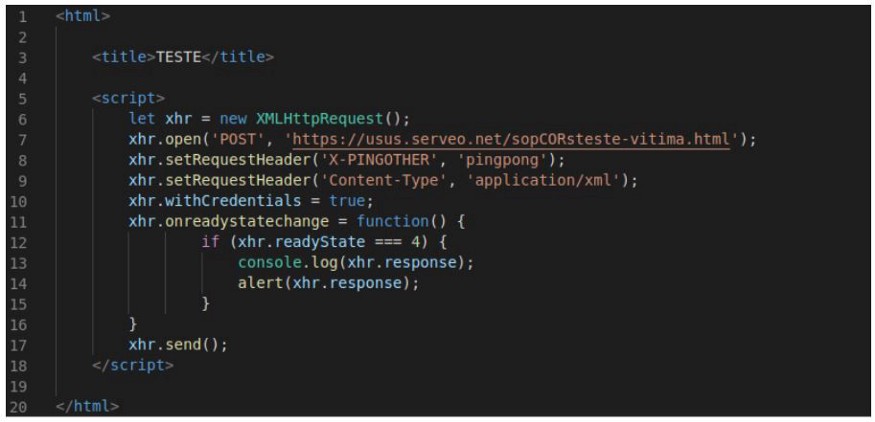
With this POST request, a Preflight request is generated:
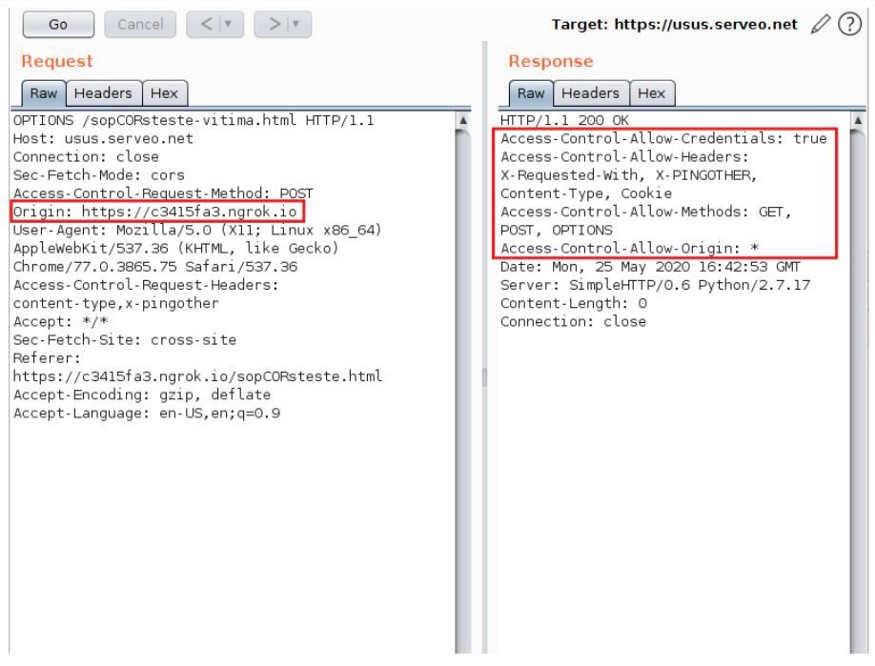

As we can see in the previous image (figure 2.4), the Access-Control-Allow-Origin field was configured on the server with the wildcard “*”, in thesis, allowing for any origin. However, for the cases in which it is necessary to use credentials (represented by the use of cookies, for example), the market browsers should block the access to the resource, since such conduct is quite dangerous, and can potentiate classic attacks such as Cross-Site Request Forgery.
Knowing this, the test was performed precisely to verify that all browsers block access to cross-origin resources in this scenario, and, fortunately, all browsers contained in the survey have this criterion.
As proof of concept, if cross-origin access is allowed, the alert(xhr.response) contained in figure 2.2 must print line 27 of figure 2.4 (containing the text Hello world!).
Considering our wildcard * test, the result can be seen in figure 2.5 below:
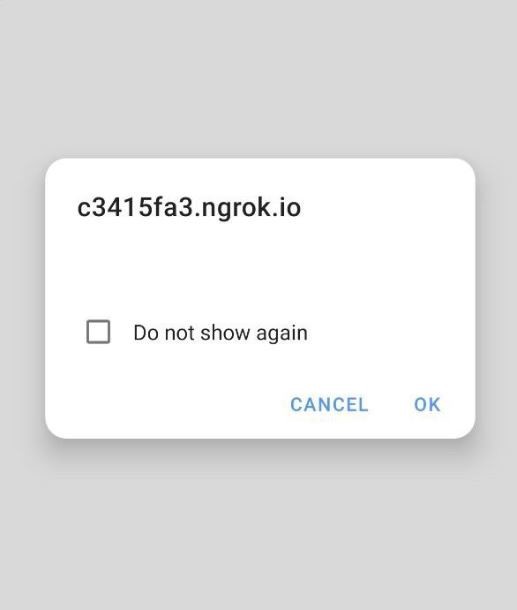
As we can see in the previous image (figure 2.5), the response containing the text Hello world! was not displayed.
Let us now consider the scenario where the Access-Control-Allow-Origin field reflects the same origin of the requestor. Let us see the result in figure 2.6, below:
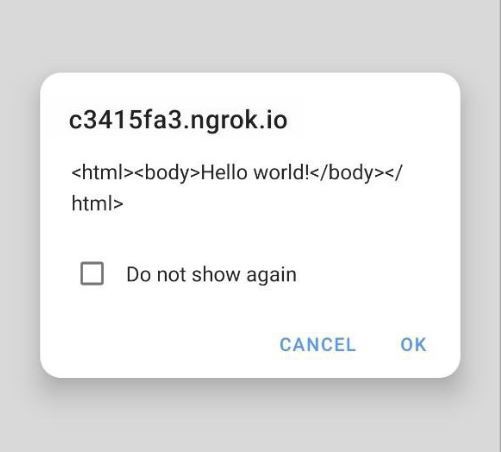
As can be seen in figure 2.6, the response was displayed in our alert because, in this scenario (with the Access-Control-Allow-Origin field reflecting the same origin as the requestor), cross-origin access is allowed by the browser.
Content Security Policy Bypass
Content Security Policy or CSP is a field at the HTTP response header that modern browsers use to improve the security of documents or web pages. The Content-Security-Policy field allows to restrict resources such as JavaScript, CSS, and more. It can, for example, decrease the surface area of Cross Site Scripting and ClickJacking attacks by stating which dynamic resources can be loaded.
In short, the policies instruct the browser to load the contents from what was specified in the header. By accessing the recommended test site, https://content-security-policy.com/browser-test/, it was possible to confirm that all browsers chosen for this search support and contain the CSP policy on the 3 levels recommended by W3C (World Wide Web Consortium).
In contrast, at the Google Chrome mobile browser, through a policy injection, the existing script-src directive was overwritten. By using the script-src-elem directive, it was possible to overwrite existing script-src directives. Through a proof of concept created by Gareth Heyes, PortSwigger’s researcher, an XSS was triggered without any difficulty.
Proof of concept:
HTML Code:

xss.js code:

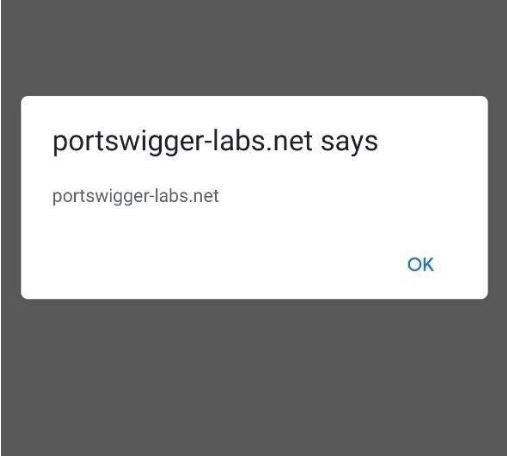
As we can see, in the URL, the script-src-elem directive is inserted and the script tag with the link to the malicious file is included. With this, the alert(document.domain) is executed.
history.back() Open Redirect
The history.back() method loads the previous URL into the browser history list — it’s the same as using the “back” button of browsers (the history.go(-n) method, it is a second way to do this, being n the number of times you want to return to the page). Other methods we need to know about are history.replaceState(state, title[, url]), which allows to modify entries in the browser history, and history.pushState(state, title[, url]), which records a new entry at the session history. With this in mind, let’s proceed to the example.
The parameters state, title and url correspond, respectively, to a JavaScript object associated with the history entry created, page title and the URL that will be modified/registered in the history. An important point is that browsers should block the execution of these methods if the new URL is not from the same domain as the current URL. Let’s proceed to the example:
First, we have a legitimate A page, which has a link to a malicious B page.
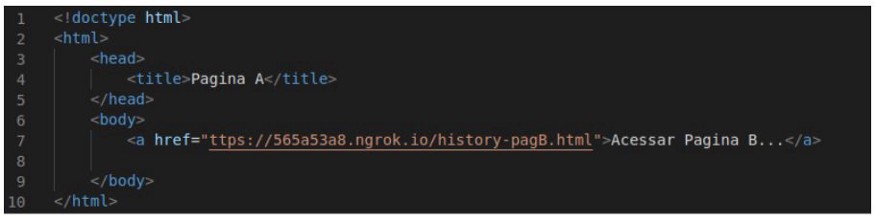
When the victim accesses this page B through page A and clicks the link, the following script is triggered:
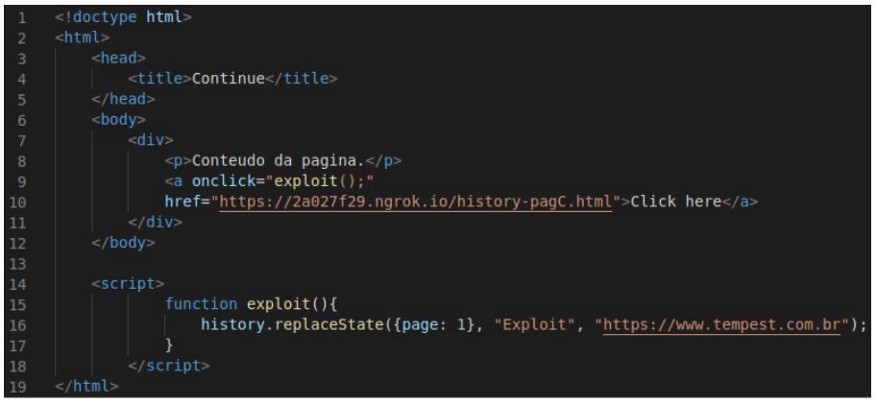
As we can see in Figure 4.2, when we click on “Click here” we are directed to page C:

On page C, when we use the little arrow to return a page, we should be directed to the site that was put by history.replaceState(), in this case https://www.tempest.com.br.
However, as said before, the browsers present in the search blocked this functionality because they require the new URL to be from the same domain as the current URL, as we can see below:
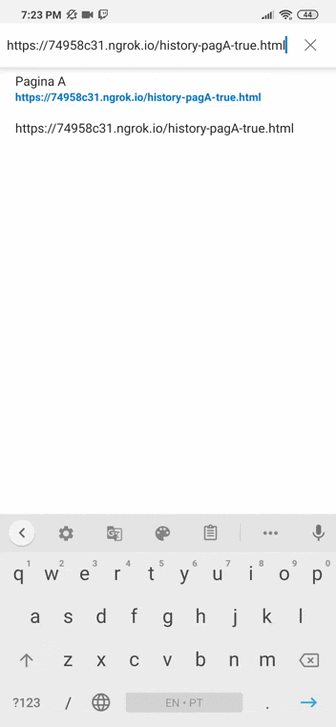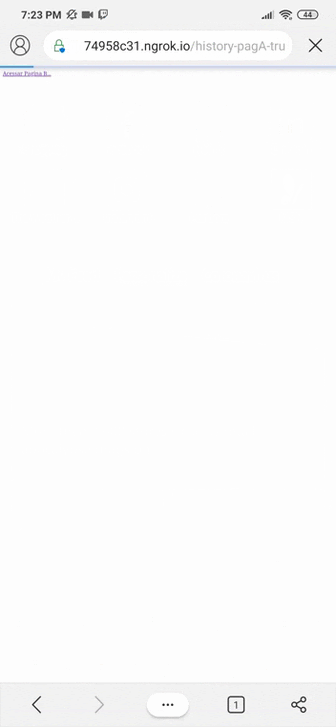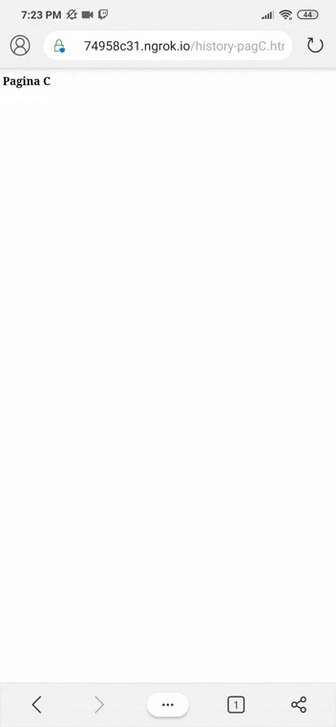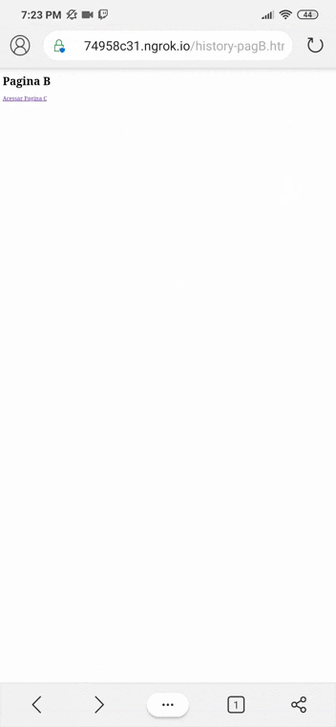

This example was motivated by the article “Phishing with history.back() open redirect” (https://medium.com/@0xHyde/exploiting-history-back-3ec789c124dd), and none of the browsers cited in this search performed the URL exchange.
Scroll Jail
In the vast majority of mobile browsers, when the user scrolls the page, the browser hides the URL bar. Thus, a malicious site created for phishing purposes can use this behavior to present itself as a different site, displaying its own fake URL bar. There you must be thinking “But when I go back to the beginning of the page the URL bar appears again!”, but still, after the browser hides the URL bar, we can move all the content of the page to a “Scroll Jail”, that is, a new element with overflow:scroll. After that, the user will think that he is scrolling the page, but actually he is in the Scroll Jail!
But it doesn’t end there! To prevent the user from scrolling to the beginning of this “chain” and the URL bar from being displayed again, it’s possible to insert a high padding at the beginning of the chain and, if the user tries to scroll to the top, it will be “pulled” back to the base of the Scroll Jail content.
This phishing method was found in the title article “The inception bar: a new phishing method”, by Jim Fisher (https://jameshfisher.com/2019/04/27/the-inception-bar-a-new-phishing-method/) and, from the attempt to reproduce it, we have succeeded in all the browsers present in this research.
Let’s see in practice how this happens:

As we saw in the video, phishing attacks, such as a form requesting sensitive information from the victim, can gain greater credibility through this attack because it hides the URL of the malicious site and shows the true URL through an image.
Conclusion
Through the analysis performed, we can see that mobile device browsers are vulnerable to attack/investment and deserve more attention and more targeted research to assess their maturity and exploitable points. In the time of this research, we were able to make the analysis of the four aspects mentioned above.
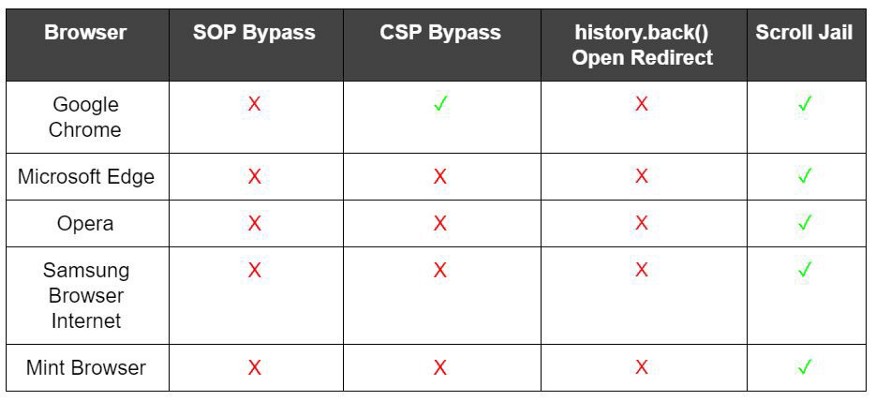
In Table 2, we have the results obtained after the completion of the tests performed:
The main obstacle during the search was to find material about mobile browsers, since the vast majority of materials about browsers is related to desktop versions.
For future research, we would like to look for other forms of SOP bypass, such as analyzing how SOP behaves in front of different URL schemes, as well as other forms of CSP bypass, analyzing how browsers behave in relation to specific applications, as well as new exploitation scenarios for the search of new security problems existing in mobile device browsers.
Finally, it is valid to remember to always check the links before uploading them, checking the URL for spelling errors, avoid clicking directly on a link sent by email, check email source, activate DLP protections, among other methods to avoid becoming a victim of phishing campaigns. In addition, it is strongly recommended to be aware of browser updates and always keep them updated.
I hope you enjoy reading them and I see you next time!