Data leak prevention has been a hot topic among technology people, even more so with the arrival of the Data Leak Prevention Act (LGPD). Unfortunately, Data Loss Prevention is something very segregated within the Technology industry and, even more so, in information security, even though there are so many other areas involved in IS, however, after a few years doing projects and producing content on this subject, I could see the levels of these layers and what we can achieve with a good development of the concept and architecture of Data Loss Prevention (DLP).
Obviously, we’re not going to talk about the awareness of people involved in the concept that a DLP solution proposes; in this article, the focal point is to present a more conceptual view of the subject for those who have already taken the first plunge into the information security field. The goal is to demonstrate which steps have made my life easier as a consultant in data leakage prevention, points that I have applied and developed during my trajectory by creating DLP environments and architectures. An important observation is that: – there are no direct rules or even standards and policies to be applied to the development of a DLP environment, but rather a consensus between people involved during the implementation and process development phase. In this phase, the “how” it should be: “how” the intelligence should be applied. Another point that is under development is the processes. It’s important to know which ones should exist in order to keep a DLP environment alive.
In this article, we’ll cover the development of processes, technologies, and people in an information leak prevention environment.
Another important observation is that the acronym DLP stands for “Data Loss Prevention,” i. e., in its definition, everything that is relatively important to the company’s business and that should be monitored to prevent it from being exposed to the public, again, DLP is the art of understanding and monitoring the output of items that are precious to the company, through process mapping.
To start the subject, we need to explain some basic concepts of DLP solutions what the areas of information leak prevention do, such as: what are policies, rules, exceptions, groups, technology, intelligence, precision, and accuracy.
Of course, words tend to give us straightforward concepts for interpretation; however, the point here is to show how the integration of each should be harmonious and well applied for “smarter intelligence”.
It is important to clarify the composition of a policy within a DLP system for a better understanding of the subject. A policy is a combination of detection rules, exceptions, monitored user groups, and response actions that form what we call, here in this article, the intelligence that will be applied to the technology. CALM DOWN! I’ll explain!
Rules are: what do I want to monitor? Then impute a set of “intelligence” to the detection rule, being them in the category of Accuracy and/or Precision
Example: confidential.RAR with social security numbers, IDs, names, genders, personal information in general, with the extension “.RAR”.
Detection rules: the intelligence to be described is to search the file “confidential.RAR” with social security numbers, IDs, names, genders, personal information in general, with the extension “.RAR”, right? So, within this premise, we can dissect the file that we already know is the asset to be protected and use more forms of detection to help assemble the intelligence. For example, the file extension, keywords contained within the file, tags, signatures, and so on. Aggregating, then, this dissection of the file into the intelligence and the detection rule.
Exceptions to the detection rules: Everything that the intelligence will “ignore” during the detection process. For example, compressed and password files.
Group Rule: To whom the intelligence of the detection rule should be applied. Example: all email accounts that have the domain @ACME.com or all users that are in the “accounting” group.
Group rule exceptions: For whom the sending of information within a certain detection group should be given as an exception. Example: [email protected]
Detection response rule: Action that will be taken upon detection. Example: In the output of the sensitive file, RAR, which has no password and was sent from an internal directory to a repository in the cloud by an unauthorized operations employee, was BLOCKED and a NOTIFICATION sent to those responsible for the file.
Note: Observe that in this example, we have two types of response, the blocking and the notification; this is the intelligence of the response rule.
Well, so far, we have learned that a DLP policy is composed of 3 types of rules (detection rule, group rule, and response rule). As such, we understand that only the detection and group rules should contain applicable exceptions.
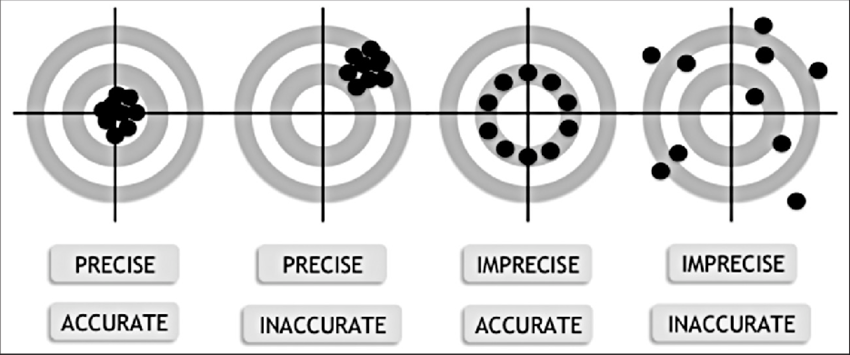
Now we proceed to the point of “accuracy increase“. The precision is increased and built through immutable empirical objects such as, for example, a regular expression of a social security number, a list of “keywords” that will compose a dictionary, “tags” and “flags” with “canary strategy” and “crown jewels”.
As we can see in the images above, the accuracy must be well configured so that it is performing the target hit function, and the target (Accurate) must be built knowing what you want to catch (why). Let’s look at an example:
Target (ACC): PDF with personal data of jobs and salaries, along with social security numbers and corporate registration numbers.
Points (Precise): Regular expressions of social security numbers and corporate registration numbers, dictionaries with names and positions, file extension.PDF.
The intelligence development of a DLP policy must go hand in hand with the comprehension of the company’s business, especially the movement of the data produced, handled, and stored by it. With this information, it’s possible to convert all the environment analysis into intelligence applicable to DLP systems.
Many opt for the Classification of information previously developed within the company so that it has enough input for the beginning of the intelligence construction. Tagging systems are highly appreciated in these cases. However, it only creates the expectation that the information handlers are classifying the data correctly and that, for the area of Prevention of Information Leakage, it cannot be taken as 100% true.
Through some processes such as conducting interviews for information classification, it’s possible to map in a higher way the transition and handling of this information, thus bringing more assertive data and documentation to DLP technologies and processes.
Let’s take a quick walk through an interview process for information classification:
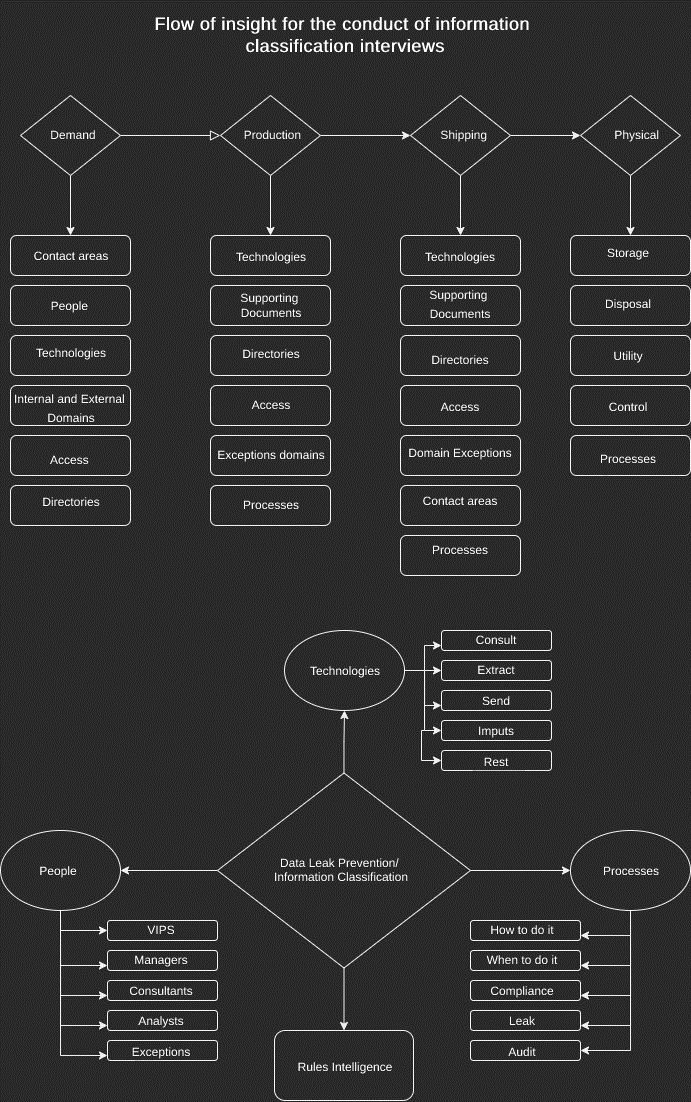
As indicated by the image above, it was developed so that the “thinking” of conducting an interview for information classification is done, recall; companies have diverse processes, diverse areas, and adverse modes of handling, so the existence of similarities in processes is alive but not mandatory. With this in mind, it’s understandable that companies have areas that you have never heard of. In a hypothetical example, if you were to conduct an interview within a large insurance company that has a department where insurance sales of Works of Art are made. As it would be something relatively different, new, having the first contact with an area of insurance of works of art, for a better understanding of this specific area, some questions need to be asked, such as: how and what kind of data is handled? Where does it come from? For a super-rich person with a “Mona-Lisa” inside his house, is this information confidential? Does it belong to the company? Does it belong to the “super-rich”? How is it obtained? Where does it go? Who evaluates the work? How and when is it sent to auction? In short, this kind of evaluation can happen. Areas that you have never heard of may have processes just for them, so it’s always good to learn concepts and be prepared for surveys like this.
The thought of “Demand”, “production”, “shipping,” and “physical” gives you the understanding needed to conduct and openly extract data and processes from the interviewed area, whether it’s a “familiar” type of area or not. Here are definitions:
Demand: Why the area exists;
Production: What and how the area performs;
Sending: Where does the area send what it has produced;
Physical: The area produces something that at the end of the process becomes a physical item;
Within the construction of this thought, it’s expected that at the end of its conduction, something with value to be applied in the area (processes), in the technology (solutions), and to the people (Training/Awareness) is delivered. At the end of the image suggested as a reference, the frame of thought in “Data Leakage Prevention/Information Classification” is shown, being pointed in 4 fronts: people, technologies, processes, and the output of rules intelligence.
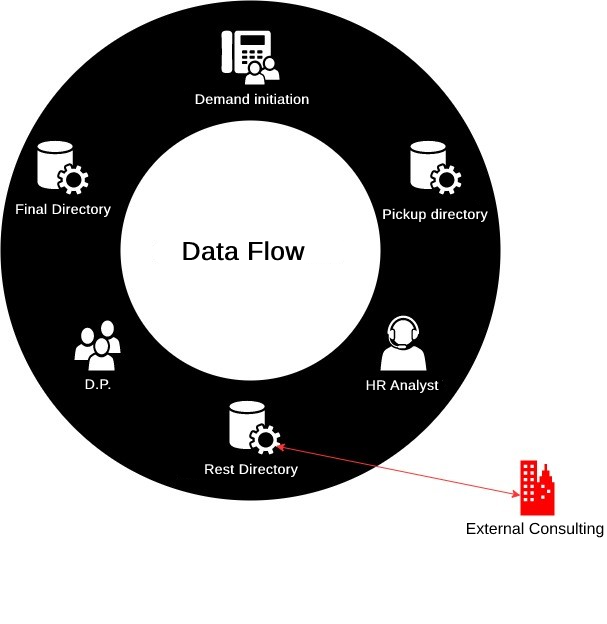
Let’s say we’ll have a data flow between one business area and another; in my example, the areas are the Personnel Department (P.D.) and Human Resources (HR), where the representation of the beginning of the flow is “demand initiation”. This would arrive via telephone, followed by a “collection directory” that is received and opened for analysis and data imputation by the “HR Analyst” who, after doing his job, forwards it to another directory, which we call “Rest Directory”, and that’s where the analysis of the flow “gaps” begins. What are “Flow Gaps”? They are all openings to external domains where authorized information exchange occurs, which we can call “Business WorkFlow”. In case of a flow recognized and authorized by those responsible for the information, this “gap” point is considered an exception to detection; that is, if it’s sent, during the data flow, to “external consulting”, the flow will be duly following its script; therefore, nothing is out of the standard, and there was no data leakage.
Followed by the D.P. analysis that at the end of the flow, leaves the document in “resting” at the point called “Final Directory”.
Rules intelligence can be translated into tools and policies/norms for the company or area of data leak prevention.
It is important that, for the use of DLP, corporate maturity and information traffic mapping is at a reasonable level, i. e., it’s necessary that the company understands the “life” of the information it handles because a company that doesn’t understand how this “life” works won’t understand what needs to be protected, meaning that DLP intelligence won’t be useful, and certainly won’t be intelligent.
Conclusion
DLP intelligence should be studied separately, and a specific DLP tool (Technology) is not necessary. With the study focused on intelligence and not on the technology that uses the intelligence, the tendency is to raise the level of efficiency of the policy and, no doubt, the quality of the consultant who develops it. Of course, studying the platform on which the intelligence will be developed is totally indispensable, but the efficiency of adding good policy intelligence to a technology that will act with it is the idea that gives you the best of both worlds.