Por Lucídio Neto
1. Introdução
Diante das facilidades de utilização dos recursos das nuvens, não é muito difícil de se cometer algum ato falho e/ou erro de configuração em algum recurso e, com isso, expor mais informação do que se deveria.
Devemos ter em mente que os malefícios causados por um vazamento de dados tendem ao infinito e os prejuízos são inúmeros. Podem variar desde a exposição de um simples endereço IP, até o potencial encerramento de uma conta devido à posse das credenciais do usuário root. Naturalmente, a gravidade do problema vai depender do tipo de dado que foi vazado.
Há dois aspectos essenciais a serem considerados: em primeiro lugar, a detecção das falhas e, em segundo, as medidas necessárias para corrigi-las. Não entraremos em detalhes sobre como proceder com as correções, pois isso depende naturalmente das particularidades de cada ambiente. Em vez disso, concentraremos nossa atenção na sugestão de montagem de um mecanismo que irá identificar as falhas e torná-las visíveis para os administradores.
Seguiremos por uma abordagem simples e sem custos elevados para executar a busca por vulnerabilidades, bem como para avaliar os recursos da nuvem visando mitigar erros e, consequentemente, reduzir riscos de exposição de informação por práticas de má configuração.
A abordagem é conhecida no mercado como CSPM (Cloud Security Posture Management), ou, em bom português: gerenciamento da postura de segurança de nuvem. As ferramentas de gerenciamento de postura de segurança em nuvem, em geral, automatizam a identificação, enumeração e sugerem a correção de riscos em infraestruturas de nuvem, incluindo Infraestrutura como Serviço (IaaS), Software como Serviço (SaaS) e Plataforma como Serviço (PaaS).
Para a ilustrar a solução, utilizaremos como exemplo os conceitos de nuvem em AWS* como provedor de Cloud. Porém, o mesmo racional pode ser facilmente aplicado em qualquer outro provedor, pois a ferramenta pode ser configurada para operar com as principais soluções de nuvem disponíveis atualmente.
Sendo assim, esta publicação tem como objetivo apresentar uma ideia relativamente simples que profissionais ou interessados nesta temática de cibersegurança possam implementar nas suas clouds de forma a identificar possíveis falhas de configuração.
Descrição do Cenário
É uma boa prática de nuvem utilizar contas separadas para ambientes de desenvolvimento, homologação e produção de um sistema. Entretanto, neste artigo utilizaremos apenas uma única conta para ilustrar a implementação desse tipo de cenário. Ainda assim, cabe ressaltar que esse tipo de solução também funciona e poderá ser adaptada para utilização em múltiplas contas.
O cenário proposto conta com uma instância EC2 (Elastic Compute Cloud) na AWS, configurada na região da Virgínia com as ferramentas do CloudSploit*, o LogStash* e o ElasticSearch* instalados nela. Entretanto, também pode ser usado um servidor tipo VPS (Virtual Private Server), um servidor On-Premises ou, em um caso muito particular, pode ser inclusive a própria máquina do Administrador, caso este queira fazer na sua própria conta da AWS.
A Figura 1 a seguir ilustra a instância que contém o CloudSploit utilizando um usuário da AWS e realizando o scan nos demais serviços da conta.
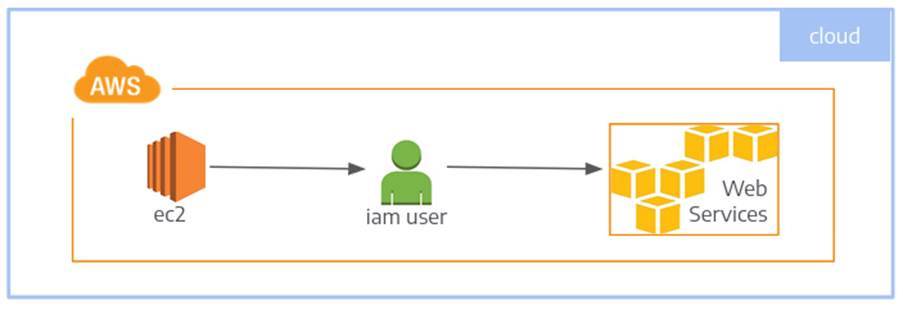
O fluxo do processo será: o CloudSploit realiza as varreduras, disponibiliza o resultado em um diretório para que um script importe o resultado no ElasticSearch utilizando o LogStash.
Para viabilizar a varredura utilizando o CloudSploit, optou-se por criar um usuário na AWS e conceder a esse usuário as permissões contidas na política SecurityAudit gerenciada pela própria AWS.
O uso do usuário foi para explanar a ideia de que esse conceito pode ser reproduzido no notebook pessoal ou em alguma máquina fora da AWS, nesses casos, o uso das credenciais de Accesskey/Secretkey são necessárias.
Cabe aqui uma ressalva quanto ao uso de Accesskey/Secretkey. Este procedimento só é recomendado em caso de máquinas fora da AWS, pois nesses casos não há outra alternativa para viabilizar o acesso. Seguindo as boas práticas de segurança, tratando-se de máquinas na AWS, recomenda-se o uso de Role para reduzir o risco de vazamento de credencial.
A Role que será utilizada deverá conter a policy SecurityAudit e deverá ser anexada a instância EC2. O uso da policy SecurityAudit é recomendad devido a policy conceder acesso a alguns detalhes de configuração que as policies de ReadOnly e ViewOnly não o fazem. Então, para não termos uma visão miope das configurações, optou-se pela SecurityAudit.
A seguir detalharemos cada um dos itens mencionados como forma de colaboração aos leitores interessados em replicá-los e obter as vantagens propostas pela solução apresentada.
2. Ambiente do Servidor
Nesta seção, serão citados os itens instalados na instância EC2, tais como o CloudSploit, o LogStash e o ElasticSearch, assim como os procedimentos adotados para a criação da própria EC2.
Como visto na “Figura 1”, uma única instância EC2 é o suficiente para realizar os procedimentos necessários para a varredura e disponibilização dos resultados obtidos. Nessa instância encontram-se todas as ferramentas necessárias para o fiel cumprimento do presente mandado 😀
2.1. Sistema Operacional
A instância EC2 foi criada na região da Virgínia utilizando-se uma AMI (Amazon Image) do Linux Debian 11. Tal AMI foi escolhida da lista de AMIs mantidas e gerenciadas pela própria equipe da Distribuição Debian que se encontra disponível em:
- https://wiki.debian.org/Cloud/AmazonEC2Image/Bullseye
A instância também foi configurada com o uso de um Elastic IP, para que o IP não fosse alterado em caso de um possível stop/start na instância.
2.2. CloudSploit
O CloudSploit é um projeto de código aberto pensado e desenhado para permitir a detecção de risco de segurança no ambiente da nuvem. Funciona nos ambientes da AWS, Microsoft Azure, Google Cloud Platform (GCP), Oracle Cloud Infrastructure (OCI) e GitHub.
Os scripts do CloudSploit foram projetados para realizar uma varredura e retornar uma série de riscos de segurança potencialmente causados por falha de configuração.
A instalação foi realizada no diretório /opt/cloudspoloit/scripts para tanto foi instalado o NodeJS seguido dos seguintes comandos:
$ git clone [email protected]:cloudsploit/scans.git
$ npm install
Uma vez instalado foi criado o script /opt/cloudsploit/bin/ chamado cloudsploit.sh que executa o CloudSploit e disponibiliza o resultado para ser importado pelo LogStash no ElasticSearch.
#!/bin/bash
dirbase="/opt/cloudsploit"
conffile="${dirbase}/scripts/cloudsploit.json"
datahora="$(date +%F-%H-%M)"
logfile="${dirbase}/log/cloudsploit.log"
if [ ! -d "${dirbase}/data/${datahora}" ]; then
mkdir -p ${dirbase}/data/${datahora}
echo "${dirbase}/data/${datahora} was created" >> ${logfile}
fi
echo "running cloudsploit" >> ${logfile}
cd ${dirbase}/scripts
./index.js --collection ${dirbase}/data/${datahora}/cloudsploit-collection.json \
--config ./config.js --csv ${dirbase}/data/${datahora}/cloudsploit.csv
A execução do script disponibilizará o resultado da varredura no diretório /opt/clouldsploit/data/ em um diretório com o nome sendo a data da varredura. Este resultado será usado pelo LogStash para importar no ElasticSearch.
No código apresentado, mais especificamente no tocante a variável “conffile”, há uma referência a um arquivo chamado cloudsploit.json que deverá existir no diretório /opt/cloudsploit/scripts o qual irá conter o accesskey e o secretkey do usuário que será utilizado para a realização das varreduras.
O arquivo cloudsploit.json citado deverá estar nos moldes do exemplo apresentado abaixo. Naturalmente, os caracteres X e x deverão ser substituídos pelos seus respectivos valores do accesskey e secretkey respectivamente.
{
"accessKeyId": "XXXXXXXXXXXXXXXXXXXX",
"secretAccessKey": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
}
O modelo do arquivo cloudsploit.json, no molde apresentado, consta na documentação da ferramenta. Entretanto, a execução do cloudsploit aceita a declaração de credencial de acesso através de variável de ambiente, o que é ainda mais recomendado para que não seja armazenada a credencial em texto plano.
No caso de máquina na AWS, e que por ventura esteja usando uma role para o acesso, podemos executar os comandos a seguir para carregar as credenciais de accesskey/secretkey. A princípio carrega-se o token de acesso aos metadados e, depois, ,consulta-se as informações da role, seguem os comandos.
TOKEN=`curl -X PUT "http://169.254.169.254/latest/api/token" -H "X-aws-ec2-metadata-token-ttl-seconds: 21600"` curl -H "X-aws-ec2-metadata-token: $TOKEN" -v http://169.254.169.254/latest/meta-data/iam/security-credentials/Role-Used
Com a variável TOKEN carregada conforme apresentado, a execução do comando curl listado resultará na exibição das credenciais temporárias de acesso.
$ curl -H "X-aws-ec2-metadata-token: $TOKEN" -v http://169.254.169.254/latest/meta-data/iam/security-credentials/Role-Used
* Trying 169.254.169.254:80...
* Connected to 169.254.169.254 (169.254.169.254) port 80 (#0)
> GET /latest/meta-data/iam/security-credentials/Role-Used HTTP/1.1
> Host: 169.254.169.254
> User-Agent: curl/7.74.0
> Accept: */*
> X-aws-ec2-metadata-token:
XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX==
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
< X-Aws-Ec2-Metadata-Token-Ttl-Seconds: 21534
< Content-Type: text/plain
< Accept-Ranges: none
< Last-Modified: Thu, 19 Oct 2023 14:06:35 GMT
< Content-Length: 1594
< Date: Thu, 19 Oct 2023 14:10:54 GMT
< Server: EC2ws
< Connection: close
<
{
"Code" : "Success",
"LastUpdated" : "2023-10-19T14:06:54Z",
"Type" : "AWS-HMAC",
"AccessKeyId" : "AAAAAAAAAAAAAAAAAAA",
"SecretAccessKey" : "SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS",
"Token" : "xxxxxxxxxxxxxxxxxxxxxxK6TA0q0wSMQzQ4vL40iHhwREJNNJz60BISCivtR0SAGQTXELxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxRXDtTdHHLAtX+il6sM4peQbE969MLN21+QY9yihGExxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxCXwBMwvj6aTvnBT3FbtaSMtydYzz=",
"Expiration" : "2023-10-19T15:34:18Z"
* Closing connection 0
}l
No caso, declaram-se as variáveis de accessKeyId e secretAccessKey baseadas nos valores apresentados com a execução do comando.
export accessKeyId=”AAAAAAAAAAAAAAAAAAA” export secretAccessKey=”SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS”
2.3. LogStash
O logStash é um excelente pipeline de dados gratuito que pode ser usado para a ingestão de dados de inúmeras fontes, transformá-los e enviá-los para um destino específico. Este foi utilizado para pegar o resultado da varredura do cloudsploit e importar no elasticsearch.
A instalação do logstash foi realizada de forma simples “apt install logstash”. Após a instalação foi criado um arquivo no diretório /etc/logstash/conf.d chamado cloudsploit.conf, contendo as configurações necessárias para a importação da varredura no ElasticSearch.
A seguir, um exemplo de configuração que pode ser utilizado.
input {
stdin {}
}
filter {
mutate {
add_field => { "account" => "MyAccountX" }
}
csv {
columns =>
["category","title","description","resource","region","statusWord","message"]
}
translate {
field => "title"
destination => "severity"
dictionary_path => "/etc/logstash/enrichment/rule-severity.csv"
fallback => "no classification"
}
translate {
field => "title"
destination => "cloudslpoit_check_code"
dictionary_path => "/etc/logstash/enrichment/rule-code.csv"
fallback => "no classification"
}
translate {
field => "title"
destination => "recomendation"
dictionary_path => "/etc/logstash/enrichment/rule-recomendation.csv"
fallback => "no classification"
}
translate {
field => "resource"
destination => "accepted_risk"
dictionary_path => "/etc/logstash/enrichment/rule-acceptedrisk.csv"
fallback => "NOK"
}
mutate {
remove_field => ["host","@version"]
add_field => ["scan_version","YEAR-MM-DD"]
}
}
output {
stdout { codec=>rubydebug }
elasticsearch {
user => "someelasticuser"
password => "xxxxxxxxxxxxxx"
index => cloudsploit
}
}
Contextualizando um pouco cada subitem apresentado no arquivo de configuração, temos basicamente 3 processos: entrada (input), filtro (filter) e saída (output). Cada um possui a sua especificidade e, apesar de não ser o intuito deste artigo discorrer de forma minuciosa sobre a configuração das ferramentas, explanaremos um pouco cada item.
input: nessa seção podemos configurar para que os dados a serem processados sejam lidos a partir de um arquivo ou pegos através da entrada padrão. Então, optou-se pela segunda opção.
filter: no filtro é possível adicionar outros subprocessos, nos casos adicionamos o “mutate”, “csv” e “translate”.
- mutate: adiciona ou remove um campo;
- csv: mapeia os campos do csv oriundos da varredura do cloudsploit;
- filtro: faz substituições para ajudar na correção das informações;
Olhando para o código do mutate e do csv, pode-se inferir com facilidade as suas funcionalidades. Então, explanaremos apenas o filtro de severidade. Este item de severidade serve para classificarmos as informações que estão chegando pela entrada padrão e classificar cada evento como sendo “crítico, alto, médio ou baixo”.
Na tabela a seguir encontram-se alguns exemplos de eventos que podem ser postos no arquivo de enriquecimento das severidades e as suas respectivas classificações.
RDS Publicly Accessible,Critical VPC Endpoint Cross Account Access,High SSM Agent Auto Update Enabled,Medium Default VPC Exists,Low VPC Elastic IP Limit,Informational
Cada linha é composta pela descrição do evento seguido de uma vírgula (,) acompanhado da sua respectiva severidade. Essa descrição do evento vem do arquivo csv que contém o resultado da varredura do cloudsploit, a qual pode mudar a classificação da severidade baseando-se na política de segurança da empresa ou pautado em qualquer outro critério que porventura seja adotado.
output: indica para onde serão entregues os dados processados.
Para a realização da importação do arquivo de varredura do CloudSploit disponibilizado no diretório /opt/cloudsploit/data pode ser criado um script, como sugestão no diretório /opt/cloudsploit/bin, que realize a devida importação dos dados para o ElasticSearch.
O código a seguir é apenas uma ideia para pegar o último arquivo de varredura contido no diretório que contém os arquivos com as varreduras e importar para o ElasticSearch.
#!/bin/bash
cs_dir="/opt/cloudsploit"
cs_data="${cs_dir}/data"
logstashconf="/etc/logstash/conf.d/cloudsploit.conf"
cs_scanresult="$(ls ${cs_data} | tail -1)"
/usr/share/logstash/bin/logstash -f ${logstashconf} < ${cs_scanresult}
Após a execução do último comando apresentado na tabela já se pode acessar o ElasticSearch e visualizar os resultados importados.
2.4. ElasticSearch
O ElasticSearch é um mecanismo de busca e análise de dados distribuído, gratuito e aberto para todos os tipos de dados, incluindo textuais, numéricos, geoespaciais, estruturados e não estruturados. Seguindo a linha das demais ferramentas, a instalação do ElasticSearch também foi simples, precisando executar apenas o “apt install elasticsearch”. Após a instalação foram realizados os devidos ajustes no arquivo de configuração do ElasticSearch (/etc/elasticsearch/elasticsearch.yml), seguem exemplos:
cluster.name: project-cloudsploit path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch xpack.security.enabled: true
O ElasticSearch permite que sejam criados usuários diferentes, com perfis diferentes, porém, como estamos apenas exemplificando, o usuário “admin” foi utilizado para logar no ElasticSearch.
Uma vez logado, clica-se nos 3 tracinhos na parte superior esquerda e depois em Discover, aparecerá um campo para que digitemos a consulta que gostaríamos de realizar.
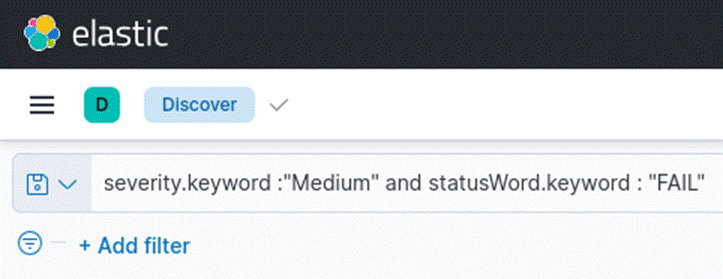
A consulta realizada na Figura 3, serviria para exibir apenas os eventos com severidade do tipo média. Entretanto, poderíamos ajustar a consulta para retornar todos os eventos.
Na Figura 4, a seguir, encontra-se uma ilustração da exportação do resultado de uma consulta no ElasticSearch exibindo apenas um item de cada severidade. Com os resultados exibidos, estes puderam ser exportados para uma planilha xls e caso seja necessário, a planilha poderá ser compartilhada com outras equipes.
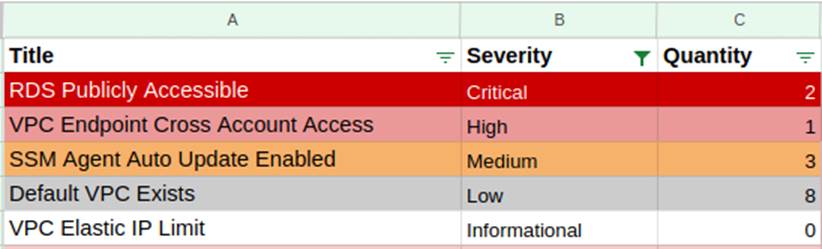
Através da consulta do ElasticSearch, também é possível exportar cada item com mais detalhe para que seja possível saber qual a região e o recurso que precisa ser ajustado. Como exemplo será exibido apenas o item relativo ao RDS ilustrado na figura acima.

(Fonte: Autoria Própria, 2023)
Para o tratamento de cada item apresentado há a possibilidade de se consultar o site da Trend Micro para obter informações acerca das ações necessárias para resolver os problemas exibidos. O site da Trend Micro citado no parágrafo anterior, encontra-se disponível no endereço: https://www.trendmicro.com/cloudoneconformity/knowledge-base/aws/.
Se quisermos consultar as ações a serem tomadas para o evento de “Endpoint Exposed” podemos acessar a URL da Trend Micro nesse formato:
https://www.trendmicro.com/cloudoneconformity/knowledge-base/aws/VPC/endpoint-exposed.html.
3. Considerações finais
Utilizando-nos do conceito bíblico do versículo 26:41 do livro de Mateus, que nos chama a atenção que Vigiemos e Oremos, pois nunca saberemos quando o inimigo irá aparecer, a implementação de um mecanismo de busca e alerta de falha mostra-se deveras importante no auxílio a manutenção da segurança dos nossos recursos em qualquer lugar, sobretudo na cloud.
A prática do uso de um mecanismo, como o citado neste artigo, vem se mostrando bastante eficaz no tocante à proteção dos recursos utilizados na nuvem, não só para redução de custo, eliminando desperdícios por uso de recursos desnecessários quanto para evitar exposição de informação e com isso comprometimento de acesso.
Ficaremos felizes se, porventura, algum item citado aqui, sirva de semente para a elaboração de novas ideias ou elucide de alguma forma questionamentos acerca de como implementar um mecanismo de detecção de equívoco de configuração que auxilie os respectivos responsáveis a identificá-los e corrigi-los para evitar possíveis danos causados por vazamento de informação.
4. Referências
Amazon Web Services. AWS, 1990s. Disponível em: https://www.aws.com. Acesso em: 01 de agosto de 2023.
CloudSploit Aqua Security. CloudSploit, 2020. Disponível em: https://github.com/aquasecurity/cloudsploit. Acesso em: 03 de agosto de 2023.
Elastic Stash. LogStash, 2023. Disponível em: https://www.elastic.co/logstash. Acesso em: 28 de julho de 2023.
Elastic Search. ElasticSearch, 2023. Disponível em: https://www.elastic.co/pt/elastic-stack. Acesso em: 29 de julho de 2023.