A adoção desenfreada de modelos de machine learning (aprendizagem de máquina) nas mais diversas aplicações, sem os devidos cuidados quanto aos riscos e vulnerabilidades introduzidos pelo uso de machine learning, pode causar prejuízos e até acidentes fatais. Imagine, por exemplo, que o sistema de detecção de pedestres de um carro autônomo, baseado em machine learning, é atacado, comprometido e levado à falha. Assim, como resultado dos esforços da Tempest para disseminar conhecimento e contribuir para a comunidade científica, acadêmica, industrial e de segurança cibernética, estamos lançando uma série de cinco posts no blog para discutir os riscos e vulnerabilidades introduzidos pelo uso de machine learning.
Neste primeiro post, explicamos o que são ataques adversariais, os quais têm como objetivo comprometer o funcionamento de modelos de machine learning, bem como suas principais categorias. Nos três blog posts seguintes, discutiremos como ataques adversariais podem comprometer diferentes aplicações, realçando, de maneira prática, a necessidade de proteger e garantir a segurança de modelos de aprendizagem de máquina. Por fim, no último blog post desta série, discutiremos tendências futuras e possíveis abordagens para tornar modelos de machine learning resistentes a ataques adversariais. Bem-vindo a nossa jornada!
-
Introdução
O termo machine learning chega às manchetes com cada vez mais frequência e se refere ao ramo da inteligência artificial que se baseia no conceito de que sistemas podem aprender, com os dados, a identificar padrões e tomar decisões com o mínimo de intervenção humana. Tem-se, por exemplo, algoritmos de classificação, que atribuem amostras de dados a uma categoria dentre um conjunto de categorias possíveis. Um exemplo típico é a detecção de clientes com perfis fraudulentos. Imagine que um cliente deseja obter um empréstimo de um banco. O gerente do banco poderia se perguntar: “será que este cliente vai pagar o empréstimo?”. Ou ainda, “qual tipo de juros se adequaria melhor ao perfil deste cliente (10%, 15%, 20% etc.)?”. Este é um problema típico de classificação, pois se deseja classificar um cliente em uma das possíveis classes do problema, por exemplo, bom pagador/mau pagador ou “10%”/”15%”/”20%” de juros. Assim, por automatizarem processos e possuírem grande assertividade, modelos de machine learning têm sido cada vez mais adotados nas mais diversas áreas.
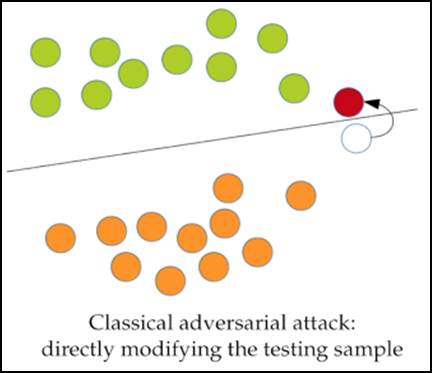
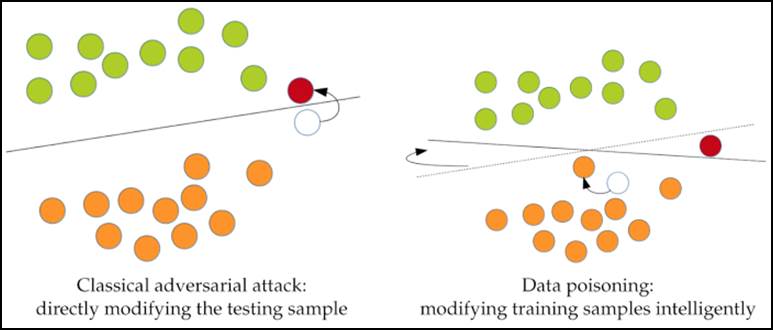
Contudo, nem tudo são flores. Embora o uso de machine learning traga inúmeros benefícios para as mais diversas aplicações, pesquisas recentes mostram que modelos de machine learning podem ser induzidos ao erro e ter suas acurácias significativamente reduzidas. De maneira geral, classificadores criam fronteiras de decisão tal que os dados de cada classe se localizem em lados opostos delas. Ataques adversariais, por sua vez, são ataques que produzem pequenas perturbações que adulteram amostras de dados e as forçam a cruzarem as fronteiras de decisão, causando classificações erradas. A Figura 1 ilustra esse processo. As bolas verdes e laranjas representam duas classes separadas por uma fronteira de decisão definida por um modelo de classificação, como um sistema de detecção de malware, por exemplo. A bola branca, por sua vez, representa uma amostra de dados que é adulterada com a adição de uma pequena perturbação adversarial. Esta perturbação faz com que a bola branca cruze a fronteira das bolas laranjas (sua verdadeira classe) para o lado das bolas verdes, sendo classificada incorretamente.
A Figura 2 ilustra um exemplo de ataque adversarial em um classificador de imagens [1]. À esquerda, temos a imagem de um animal que é corretamente classificada por uma rede neural convolucional como sendo a imagem de um porco (“pig”). Contudo, ao introduzir uma perturbação adversarial à imagem, pequena o suficiente para que a imagem da direita pareça ser idêntica à da esquerda, a rede neural passa a atribuir a classe avião (“airliner”) à imagem do porco. Imagine agora que esse classificador é parte de um projeto de monitoramento de rebanhos. Provavelmente, uma ação como essa resultaria em análises erradas sobre os animais e decisões equivocadas que poderiam causar prejuízos e a morte de animais.

Diferentemente de ataques cibernéticos, que têm por objetivo comprometer a confidencialidade, integridade, e disponibilidade da informação, dentre outros aspectos, os ataques adversariais comprometem o funcionamento de modelos de machine learning, induzindo-os ao erro, como ilustrado nas Figuras 1 e 2. Assim, a partir do momento em que classificadores baseados em machine learning passam a ser usados em cibersegurança, para detectar malwares, por exemplo, ataques adversariais passam a ser uma grande ameaça à cibersegurança por comprometerem sistemas defensivos [9, 10].
Da mesma forma, à medida que modelos machine learning são adotados nas mais diversas áreas, ataques adversariais podem, potencialmente, causar diversos problemas em diversos contextos [2, 3]. Eles podem, por exemplo, fazer com que carros autônomos vejam a luz vermelha de semáforos como luz verde, ou reduzir a acurácia de sistemas de detecção de obstáculos e pedestres, causando acidentes potencialmente fatais [13]. Dessa forma, em geral, ataques contra modelos de machine learning podem ser usados de várias maneiras para:
- Causar danos: ao provocar o mau funcionamento de sistemas inteligentes, tais como os presentes em veículos autônomos para reconhecer sinais de parada, outros carros, pedestres, e obstáculos em geral.
- Ocultar algo: ao evitar a detecção de ciberataques, propagandas indesejadas e conteúdos impróprios ou indesejados de maneira geral, para, por exemplo, impedir o bloqueio de propagandas terroristas em redes sociais.
- Degradar a confiabilidade de sistemas: ao reduzir a confiança que um operador tem no modelo de machine learning utilizado, levando ao seu desligamento. Um exemplo disso são ataques que fazem com que um alarme de segurança automatizado classifique, erroneamente, eventos regulares como ameaças à segurança, desencadeando uma enxurrada de alarmes falsos que podem levar o sistema a ficar fora do ar.
-
Taxonomia de ataques adversariais
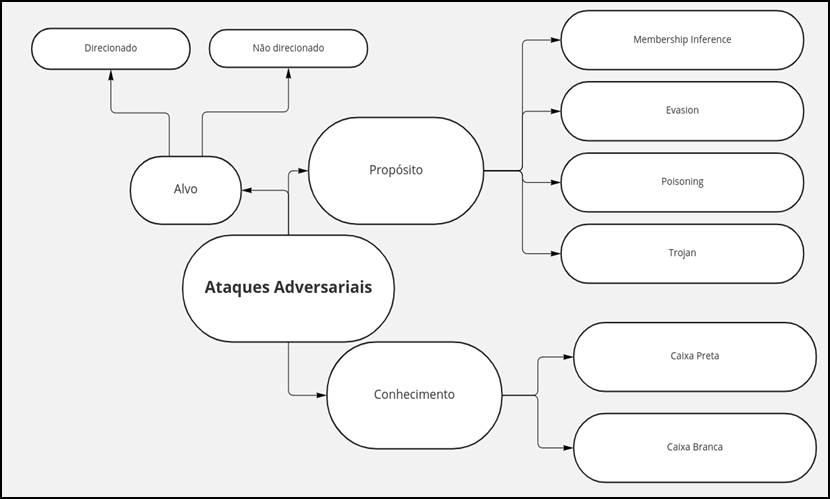
Ataques adversariais exploram vulnerabilidades criadas pelo uso de modelos de machine learning e utilizam diferentes estratégias para alcançar objetivos maliciosos [4, 5]. Assim, podem ser classificados de diferentes maneiras. Destacamos, aqui, como eles podem ser classificados de acordo com o conhecimento prévio que o atacante tem sobre o modelo de machine learning que é alvo do ataque, se o ataque possui um alvo direcionado ou não e o propósito do atacante. As subseções a seguir detalham cada uma das classificações ilustradas na Figura 3.
2.1. Conhecimento
Essa categoria se baseia no conhecimento prévio que o atacante detém sobre o modelo de machine learning que é alvo do ataque e classifica ataques adversariais em white-box (caixa branca) e black-box (caixa-preta). Apesar de alguns autores também considerarem o grupo grey-box ou semi-white box nessa categoria, neste blog post adotamos a linha dos autores que defende apenas dois grupos nessa categorização [5, 8].
a) Ataques white-box
Os ataques adversariais white-box requerem que o atacante tenha conhecimento completo do modelo de machine learning que é alvo do ataque, como, por exemplo, dados de treinamento, arquitetura, algoritmo de aprendizagem e hiperparâmetros [6]. Os autores de [7], por exemplo, propuseram uma técnica para gerar ataques adversariais white-box chamada AdvGAN, a qual gera exemplos de ataques adversariais usando redes generativas adversariais (GANs). O modelo treinado por eles conseguiu produzir perturbações adversariais com eficiência e executar ataques white-box com taxa de sucesso de ataque acima de 90%.
b) Ataques black-box
Já nos ataques do tipo black-box, o atacante não possui informações sobre o modelo alvo. O atacante pode, no entanto, ter conhecimento de pares de entradas-saídas por meio do uso do modelo alvo, ou seja, o atacante pode fazer “consultas” ao modelo alvo enviando-lhe amostras de dados e recebendo de volta os seus resultados de classificação. Trata-se de um cenário de ataque mais realista visto que, em geral, não se tem acesso completo ao modelo, como requerido pelos ataques white-box, mas às saídas do modelo através de APIs.
Adicionalmente, os autores em [8] definem três modelos de ameaça caixa preta mais restritivos e realistas: limitado por consulta, informação parcial e baseado em decisão. O cenário de consulta limitada considera que o atacante tem acesso apenas a um número limitado de saídas do modelo. O cenário de informações parciais considera que o atacante tem acesso apenas às probabilidades de algumas das classes do modelo. Por fim, o cenário baseado em decisão considera que o atacante tem acesso apenas à decisão do modelo, ou seja, à classe à qual ele atribui uma determinada amostra de dados, ao invés de valores de probabilidade.
2.2. Alvo
A segunda perspectiva de classificação está associada ao fato de o atacante possuir ou não um alvo específico, ou seja, se o atacante quer que o modelo erre ou se ele quer que o modelo erre de uma forma específica. Assim, nessa categorização, tem-se ataques não direcionados e direcionados.
a) Ataques não direcionados
Em ataques não direcionados, a intenção do atacante é enganar o modelo para que ele preveja uma saída diferente daquela que deveria prever. Para o atacante, não importa a qual classe errada o modelo vai atribuir determinada amostra, desde que a amostra não seja atribuída à classe correta [18, 19]. No caso de um classificador de imagens, por exemplo, o atacante pode ter como objetivo que as imagens de cachorros não sejam classificadas como sendo de cachorros, mas para ele não importa se essas imagens são classificadas como sendo de gatos ou de pássaros.
b) Ataques direcionados
Em ataques direcionados, por sua vez, não basta que o modelo erre, o atacante tem que forçar o modelo a errar de uma maneira específica [2]. Ele pode querer, por exemplo, que as imagens de cachorros sejam classificadas como sendo imagens de gatos.
2.3. Propósito
De acordo com o seu propósito, ataques adversariais podem ser classificados em: evasion (evasão), poisoning (envenenamento), trojan e membership inference (inferência de associação).
a) Evasion (evasão)
Ataques de evasão ocorrem quando perturbações adversariais são introduzidas a amostras de dados em tempo de inferência, ou seja, quando o modelo de machine learning alvo do ataque já foi treinado e está em plena operação. Sendo um dos tipos de ataques mais explorados, até então, vários trabalhos propõem ataques do tipo evasion [15, 16]. Em sistemas de detecção de malwares, por exemplo, ataques de evasion podem ser usados para evadir a detecção, ou seja, para disfarçar o conteúdo malicioso de ciberataques tal que malwares, por exemplo, não sejam detectados.
b) Poisoning (envenenamento)
Ataques de poisoning têm como objetivo contaminar (envenenar) dados que serão utilizados no treinamento do modelo de machine learning alvo. De modo geral, o atacante pode manipular dados de treinamento de quatro formas diferentes:
- Modificação de rótulos: modifica os rótulos de um conjunto de dados de aprendizagem supervisionada de maneira arbitrária.
- Injeção de dados: adiciona novos dados ao conjunto de treinamento.
- Modificação de dados: modifica dados de treinamento antes de eles serem usados para treinar o modelo alvo.
- Corrupção lógica: o atacante tem a capacidade de interferir no algoritmo de machine learning.
A Figura 4 ilustra o ataque de poisoning em detalhes, bem como o compara com um ataque adversarial de evasão. Basicamente, a principal diferença é que os ataques de poisoning alteram as fronteiras de classificação por meio da modificação no conjunto de dados de treinamento, enquanto que os ataques adversariais de evasão alteram os dados de entrada.
c) Trojan
Em ataques adversariais Trojan, o atacante não tem acesso ao conjunto de dados inicial, mas tem acesso ao modelo e aos seus parâmetros e pode treinar novamente esse modelo. Quando isso pode acontecer? Atualmente, muitas empresas não constroem modelos do zero, mas treinam, novamente, modelos existentes, adaptando-os ao seu ambiente e cenário de uso. Por exemplo, se for necessário criar um modelo para detecção de câncer, modelos conhecidos de reconhecimento de imagens podem ser usados e treinados novamente com um conjunto de dados específico para a identificação de imagens que representam câncer.
d) Membership Inference (inferência de associação)
Por fim, ataques adversariais de membership inference têm como objetivo identificar quais dados foram usados no treinamento do modelo de machine learning alvo. Esta informação pode ser muito útil para o desenvolvimento de ataques poisoning mais sofisticados e também para inferir qual a arquitetura do modelo quando ela não é conhecida.
-
Próximos blog posts: ataques adversariais em redes
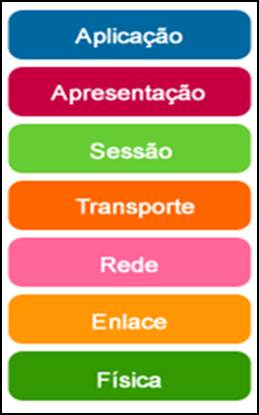
Ao passo que aplicações de redes e comunicações têm adotado cada vez mais machine learning, o impacto de ataques adversariais nesses contextos merece destaque e tem sido objeto de estudo de várias pesquisas. Assim, a fim de tornar a nossa discussão mais didática, abordaremos nos próximos blog posts ataques adversariais em diferentes contextos e cenários de acordo com as camadas do modelo OSI (Open Systems Interconnection), que organiza a comunicação em redes através de camadas [11]. A Figura 5 apresenta as sete camadas do modelo OSI: física, enlace, rede, transporte, sessão, apresentação e aplicação [12].
Assim, no segundo blog post dessa série, focaremos em ataques adversariais na camada física, em que os atacantes podem, por exemplo, comprometer a transmissão de sinais de comunicação sem fio de Wi-Fi ou redes celulares. No terceiro blog post, discutiremos ataques adversariais na camada de rede, em que sistemas de detecção de intrusão podem ser comprometidos. Por fim, no quarto blog post desta série, nos concentraremos na camada de aplicação, em que atacantes podem adulterar programas de computadores, aplicativos de celulares, e até burlar sistemas de biometria facial.
-
Conclusão
Esse foi o primeiro de cinco posts da nossa série sobre riscos e vulnerabilidades introduzidos por aprendizagem de máquina. Nele, apresentamos o que são ataques adversariais, como eles podem comprometer o funcionamento de modelos de machine learning, induzindo-os ao erro, e como ataques adversariais podem ser categorizados. Como apresentado, apesar de modelos de machine learning trazerem grandes benefícios para várias aplicações, é preciso considerar os riscos que eles introduzem e o quão impactados eles podem ser por ataques adversariais antes de adotá-los livremente e amplamente em aplicações em que erros podem significar grandes perdas.
Na Tempest, estamos trabalhando para resolver esses desafiadores problemas a fim de melhor proteger seu negócio! Fique atento ao nosso próximo post desta série de 5 publicações!
Referências
[1] Tabassi, E., Burns, K. J., Hadjimichael, M., Molina-Markham, A. D., & Sexton, J. T. (2019). A taxonomy and terminology of adversarial machine learning. NIST IR, 1-29.
[2] Carlini, Nicholas, and David Wagner. “Audio adversarial examples: Targeted attacks on speech-to-text.” 2018 IEEE security and privacy workshops (SPW). IEEE, 2018.
[3] Jia, R., & Liang, P. (2017). Adversarial examples for evaluating reading comprehension systems. arXiv preprint arXiv:1707.07328.
[4] Huang, S., Papernot, N., Goodfellow, I., Duan, Y., & Abbeel, P. (2017). Adversarial attacks on neural network policies. arXiv preprint arXiv:1702.02284.
[5] Liu, J., Nogueira, M., Fernandes, J., & Kantarci, B. (2021). Adversarial Machine Learning: A Multi-Layer Review of the State-of-the-Art and Challenges for Wireless and Mobile Systems. IEEE Communications Surveys & Tutorials.
[6] De Araujo-Filho, P. F., Kaddoum, G., Naili, M., Fapi, E. T., & Zhu, Z. (2022). Multi-objective GAN-based adversarial attack technique for modulation classifiers. IEEE Communications Letters.
[7] Xiao, C., Li, B., Zhu, J. Y., He, W., Liu, M., & Song, D. (2018). Generating adversarial examples with adversarial networks. arXiv preprint arXiv:1801.02610.
[8] Ilyas, A., Engstrom, L., Athalye, A., & Lin, J. (2018, July). Black-box adversarial attacks with limited queries and information. In International Conference on Machine Learning (pp. 2137-2146). PMLR.
[9] Gu, T., Dolan-Gavitt, B., & Garg, S. (2017). Badnets: Identifying vulnerabilities in the machine learning model supply chain. arXiv preprint arXiv:1708.06733.
[10] Sharif, M., Bhagavatula, S., Bauer, L., & Reiter, M. K. (2016, October). Accessorize to a crime: Real and stealthy attacks on state-of-the-art face recognition. In Proceedings of the 2016 acm sigsac conference on computer and communications security (pp. 1528-1540).
[11] Tanenbaum, A. S. Redes de computadores.5ª ed. São Paulo: Pearson Prentice Hall, 2011.
[12] Mendes, D. R. Redes de computadores: Teoria e Prática. São Paulo: Novatec, 2007.
[13] Yamin, M. M., Ullah, M., Ullah, H., & Katt, B. (2021). Weaponized AI for cyber attacks. Journal of Information Security and Applications, 57, 102722.
[14] Comiter, M. Attacking artificial intelligence. Belfer Center Paper, v. 8, 2019.
[15] Apruzzese, G., Andreolini, M., Marchetti, M., Venturi, A., & Colajanni, M. (2020). Deep reinforcement adversarial learning against botnet evasion attacks. IEEE Transactions on Network and Service Management, 17(4), 1975-1987.
[16] Rathore, H., Samavedhi, A., Sahay, S. K., & Sewak, M. (2022, May). Are Malware Detection Models Adversarial Robust Against Evasion Attack?. In IEEE INFOCOM 2022-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS) (pp. 1-2). IEEE.
[17] How to attack Machine Learning (Evasion, Poisoning, Inference, Trojans, Backdoors). Acesso em: 13 de setembro, 2022. [Online]. Disponível: https://towardsdatascience.com/how-to-attack-machine-learning-evasion-poisoning-inference-trojans-backdoors-a7cb5832595c
[18] A. Wu, Y. Han, Q. Zhang, and X. Kuang, “Untargeted adversarial attack via expanding the semantic gap,” in Proc. IEEE Int. Conf. Multimedia Expo (ICME), Jul. 2019, pp. 514–519.
[19] H. Kwon, Y. Kim, H. Yoon, and D. Choi, “Selective untargeted evasion attack: An adversarial example that will not be classified as certain avoided classes,” IEEE Access, vol. 7, pp. 73493–73503, 2019.