O que é Fuzzing
Em uma noite chuvosa de 1988, Barton Miller, professor da universidade de Wisconsin, estava acessando um sistema Unix através de uma conexão discada, mas por conta dos ruídos na conexão gerados pela tempestade, ele encontrava dificuldade em executar corretamente os comandos no terminal. O que chamou a atenção do professor foi que o ruído da comunicação resultou em crashes em alguns dos programas do sistema operacional.
Ele então sugeriu a ideia de entradas aleatórias para descobrir bugs em programas, teste que ele deu o nome de fuzz, termo que significa “vago” ou “impreciso”.
A partir do sucesso do projeto realizado por um dos grupos de alunos, começaram a lançar papers sobre essa nova técnica para testes de software.
Fuzzing pode ser definido como uma técnica de teste de software que executa um programa com diversas entradas aleatórias com o objetivo de causar comportamentos inesperados, como crashes, exceções ou leaks de memória. Em geral, os fuzzers geram as novas entradas a partir da modificação de outras válidas, buscando obter entradas que consigam passar por validações mais simples do programa, mas que causam algum problema em outra parte do código.
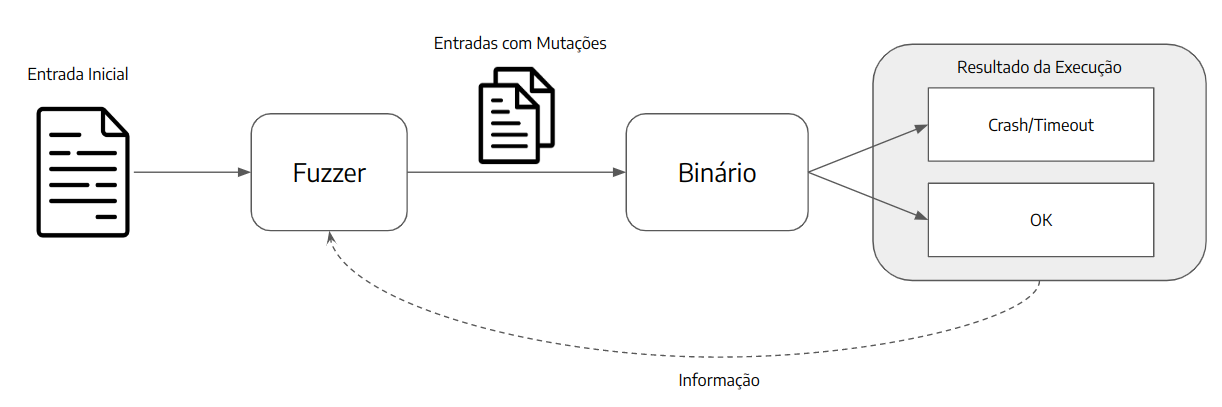
Um teste fuzzing difere de testes unitários pelo fato de que estes utilizam entradas já criadas para o teste, as quais podem ser válidas ou inválidas, observando se a parte testada do código apresenta o comportamento esperado. Já testes de fuzzing costumam gerar uma grande quantidade de entradas aleatórias, de forma automática, trazendo uma maior automação para o processo, além de facilitar a identificação de corner/edge cases, pois as entradas não precisam ser criadas manualmente por alguém.
O que isso tem a ver com segurança?
Muitos bugs encontrados a partir de testes de fuzzing não indicam somente que o programa obterá um resultado incorreto. Muitas vezes esses bugs podem ser indícios de vulnerabilidades graves. Por exemplo, uma entrada que cause um programa a entrar em loop infinito pode ser utilizada em ataques de DoS (CVE-2019-13288) ou, muitas vezes, os crashes obtidos em testes podem indicar problemas de gerenciamento de memória, como buffer overflow (CVE-2019-14438), que quando exploráveis podem levar ao comprometimento do alvo.
Uma busca rápida na internet mostra inúmeros CVE descobertos com auxílio de fuzzers. Inclusive, algumas vulnerabilidades que permaneceram “escondidas” por muitos anos, como a vulnerabilidade do sudoedit (CVE-2021-3156), poderiam ter sido encontradas utilizando fuzzers modernos como o AFL++. [6]
“Necessidade” de Feedback
Algumas ferramentas mais avançadas de fuzzing não modificam as entradas de maneira totalmente aleatória, mas realizam mutações na entrada levando em conta informações (feedback) obtidas na execução de entradas antigas. Ou seja, o fuzzer (ferramenta que executa o teste) busca gerar entradas de maneira inteligente para testar a maior parte possível do código.
Existem diversas métricas que podem ser utilizadas pela ferramenta para avaliar quão “interessante” uma entrada é. Algumas possíveis métricas são:
- número de linhas de código executadas;
- número de instruções de código de máquina (assembly) executadas;
- número de funções executadas;
- número de operações com memória executadas (malloc, calloc, free, memcpy, …).
A ideia é que o fuzzer utilize uma dessas métricas como feedback sobre a execução de uma entrada específica e, comparando o resultado de diversas entradas, possa identificar as que causam diferença no comportamento do alvo e as utilize como base para novas mutações. E novas entradas que não causem alteração na métrica podem ser descartadas.
Podemos ilustrar a ideia de feedback tomando como exemplo um fuzzing realizado no pseudocódigo abaixo:
vetor = ler_entrada(); //lê 4 inteiros como entrada if(vetor[0] == 0x24) if(vetor[1] == 0x3F) if(vetor[2] == 0x6A) if(vetor[3] == 0x88) codigo_vulneravel();
O código lê como entrada quatro inteiros (32 bits cada), realiza algumas comparações aninhadas e, caso a entrada passe por todos os testes, é chamada a função “codigo_vulneravel”, que ilustra uma possível vulnerabilidade.
Um fuzzer pode gerar entradas de maneira aleatória, na esperança de que em algum momento ele gere uma entrada que encontre o código vulnerável. No exemplo acima, a probabilidade de cada entrada do fuzzer encontrar o código vulnerável é muito baixa, cerca de 1 em ~4 bilhões, pois a chance de se acertar aleatoriamente cada um dos bytes é de 1 em 256, e como são quatro bytes, a chance de se acertar os quatro ao mesmo tempo é de 1 em 2564.
A ferramenta se torna mais eficiente se passar a considerar quais linhas foram executadas para cada entrada. Por exemplo, para uma entrada de (0x00, 0x00, 0x00, 0x00), o programa acima executará somente o primeiro if e já terminará a execução, enquanto que para uma entrada de (0x24, 0x00, 0x00, 0x00) o programa passará a executar também o segundo if. Analisando esse comportamento, ou seja, o code coverage alcançado por cada entrada, é possível explorar mais rapidamente outras áreas do código.
Nesse exemplo, o fuzzer pode perceber que ao alterar a primeira entrada para “0x24” uma nova parte do código é executada, podendo, ele pode então, manter fixa a primeira entrada como “0x24” e passar a alterar a segunda entrada, até que um comportamento diferente aconteça, e assim por diante.
Com isso, o nosso fuzzer não precisaria testar todas as ~4 bilhões de combinações para encontrar a vulnerabilidade, mas somente 1024 combinações, pois ele acabaria considerando cada entrada separadamente.
Como funciona o AFL++?
Existem diversos fuzzers, mas este artigo se concentrará no AFL++ (American Fuzzy Lop plus), explicando tanto o seu funcionamento de forma teórica, como também demonstrando, através de um exemplo, como ele pode ser utilizado para buscar vulnerabilidades em programas open-source.
O AFL++ é um fuzzer mutativo baseado em feedback, isso significa que ele modifica as entradas geradas não de maneira totalmente aleatória, mas buscando encontrar novos pedaços do programa ainda inexplorados.
Branch Coverage
A métrica utilizada pelo AFL++ como feedback da execução de uma entrada é o branch coverage [4]. A imagem abaixo ilustra de maneira simplificada um programa, no qual onde cada bloco é uma sequência linear de instruções e sempre que algum jump ocorre, ou seja, o programa passa a executar outro bloco de código, o qual é representado por uma seta conectando os dois blocos. As setas podem ser azuis, no caso de o programa sempre executar o mesmo bloco de código, ou vermelha e verde, quando o fluxo do programa pode variar, como em uma instrução de comparação que executa diferentes partes do código a depender do resultado obtido.
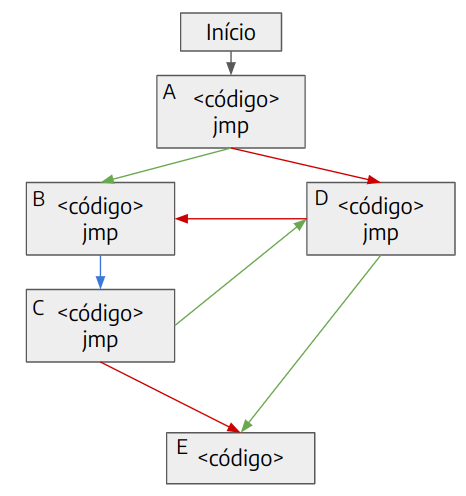
Duas possíveis sequências de execução deste programa são:
1 – A, D, B, C, E
2 – A, B, C, D, E
Em ambos os casos, o mesmo número de blocos de código é executado, ou seja, as duas sequências passam pelas mesmas instruções, chamam o mesmo número de funções, realizam as mesmas operações com memória, etc. Portanto, todas as métricas comentadas na seção anterior obteriam o mesmo resultado para as duas execuções, visto que a única diferença é a ordem em que os blocos de código são executados.
Porém, uma mudança na ordem de execução pode causar problemas se o desenvolvedor não antecipou essa possibilidade e, para conseguir distinguir casos assim, o AFL++ não considera quais blocos de código foram executados, mas, sim, uma ideia de “tupla”.
Uma tupla nada mais é do que uma ligação entre dois blocos de código. As tuplas das duas sequências de execução acima são:
1 – A-D, D-B, B-C, C-E
2 – A-B, B-C, C-D, D-E
Com isso, o fuzzer consegue diferenciar as duas sequências de execução, pois ele está interessado em qual “caminho” ou “ramificação” o programa tomou. Por isso o nome “branch coverage”.
Além disso, o AFL++ conta o número de vezes que cada tupla foi executada, e armazena essa contagem em “buckets” [1, 2, 3, 4-7, 8-15, 16-31, 32-127, 128+]. A vantagem de não considerar o número exato de execuções, mas, sim, os buckets, é que essa ação evita o path explosion, pois para uma tupla que sempre foi executada apenas uma vez e, agora, passa a ser executada duas vezes apresenta-nos uma diferença significativa. Porém, para uma tupla que era executada 98 vezes e passa a ser executada 99 vezes, dificilmente apresentará uma mudança significativa no fluxo do programa, e essa diferença pode ser ignorada.
Resumindo, o AFL++ considera que uma entrada é “interessante” se ela encontra alguma tupla nunca antes executada pelo fuzzer, ou se a contagem de alguma tupla já conhecida foi alterada o suficiente para mudar de bucket.
Instrumentação
É através da instrumentação do binário alvo que o AFL++ obtém o branch coverage. Existem diferentes técnicas que podem ser usadas a depender de alguns fatores, como a plataforma do binário (Linux ou Windows), se temos acesso ao código-fonte etc. Neste artigo, o foco será somente para o caso onde temos o código e podemos compilar o alvo com um dos compiladores do AFL++.
A instrumentação que é inserida no programa alvo é responsável por obter o branch coverage e manter a contagem de quantas vezes cada tupla foi executada. O código inserido em cada ramificação pode ser aproximado pelo trecho abaixo. [5]
cur_location = <COMPILE_TIME_RANDOM>; shared_mem[cur_location ^ prev_location]++; prev_location = cur_location >> 1;
Fonte: https://lcamtuf.coredump.cx/afl/technical_details.txt
O identificador de cada local é gerado de maneira aleatória utilizando o tempo de compilação. O vetor shared_mem é uma região de memória passada para o binário alvo, cada byte dessa região pode ser considerado como a representação de uma tupla específica.
De maneira simplificada, a instrumentação identifica cada branch com um ID aleatório e, sempre que a execução atinge um desses pontos, ele incrementa um valor no bytemap no endereço resultante da operação XOR do ID do ponto atual do código com o do anterior, endereço que representa aquela tupla.
A última linha realiza um bit shift no ID da localização atual, esse truque permite que a instrumentação consiga diferenciar as tuplas A-A de B-B, visto que a operação XOR entre dois valores iguais sempre resulta em zero. [5]
Harness, Patches no Código e Persistent Mode
Quando se tem acesso ao código-fonte, utilizar os compiladores do AFL++ já resolve o problema da instrumentação, porém, às vezes, o alvo do fuzzing não consegue ser testado diretamente. É o caso, por exemplo, do fuzzing de uma biblioteca que não recebe entradas, mas que deve ser importada e utilizada por outros programas, ou quando se deseja testar somente uma parte específica de um grande programa. Em ambos os casos, precisa-se criar um binário para ser o alvo do fuzzing, esse binário é chamado de harness.
O harness, então, nada mais é do que um programa que irá receber as entradas do AFL++ e realizar as preparações e tratamentos necessários para que o alvo do fuzzing seja testado corretamente.
Além disso, o AFL++ conta com um modo de execução chamado de persistent mode. Nesse modo, que exige alterações no código-fonte, o fuzzer não precisa reiniciar a execução toda do programa para testar cada caso de teste novo, mas utiliza um snapshot para aproveitar a inicialização do alvo já executada em entradas anteriores. Por exemplo, podemos ter como alvo um programa que realiza o parsing de uma imagem. Assim que é executado, ele gasta um tempo com inicialização, depois ele lê o arquivo de entrada e realiza o parsing e, por fim, ele realiza uma “limpeza” antes de encerrar o programa, o que também leva tempo. O que se pode fazer então é realizar um loop nesse período intermediário de execução – que envolve a leitura do arquivo de entrada e sua análise – para poder testar várias entradas distintas realizando somente uma única inicialização.
Outras mudanças no código também podem agilizar o processo de fuzzing no alvo escolhido. Pode ser interessante estudar o funcionamento do programa para identificar casos onde um patch no código pode ajudar.
Corpus Inicial e Mutações
Para começar o processo de fuzzing, o AFL++ precisa de um conjunto de entradas válidas para o binário alvo ou para o harness. Esse primeiro conjunto de entradas é chamado de corpus inicial e, idealmente, ele deve conter entradas pequenas, mas que explorem o máximo possível de funcionalidades do alvo. O fuzzer cria novas entradas ao realizar mutações no corpus. O AFL++ possui três estágios de mutação, “Deterministic”, “Havoc” e “Splice”. Vejamos esses estágios.
O primeiro estágio é nomeado Deterministic por ser determinístico, nele o fuzzer realiza uma sequência específica de mutações, que envolve, por exemplo, a inversão de todos os bits da entrada, e a inserção de “valores interessantes”, que são valores que estão relacionados a alguns problemas comuns de serem encontrados, como overflows.
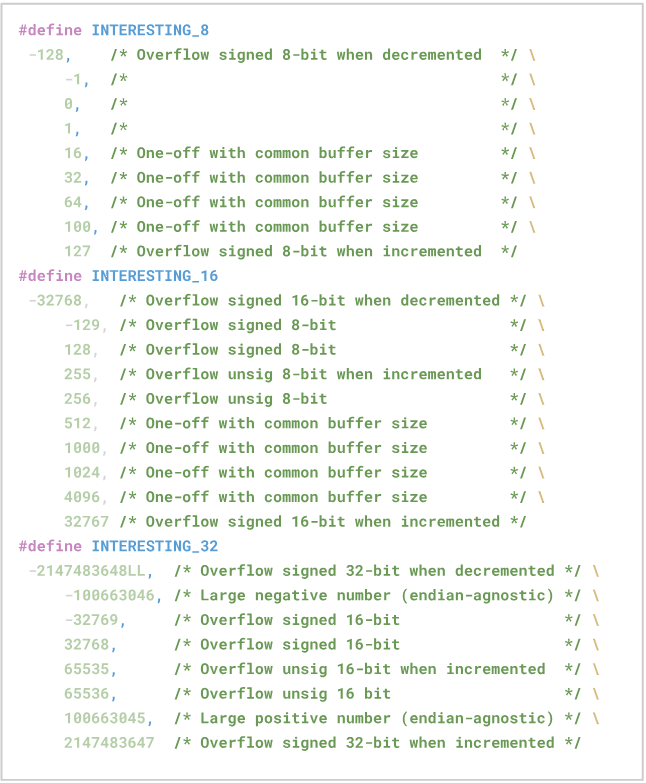
O segundo estágio se chama “Havoc”, palavra que significa “destruição generalizada” ou “devastação”. Nesse estágio o fuzzer insere, modifica ou remove sequências de bytes totalmente aleatórias em partes da entrada.
No terceiro estágio, chamado “Splice”, o fuzzer combina duas entradas distintas em uma nova entrada.
Visão Geral
A imagem abaixo ilustra a visão geral e simplificada do funcionamento do AFL++.
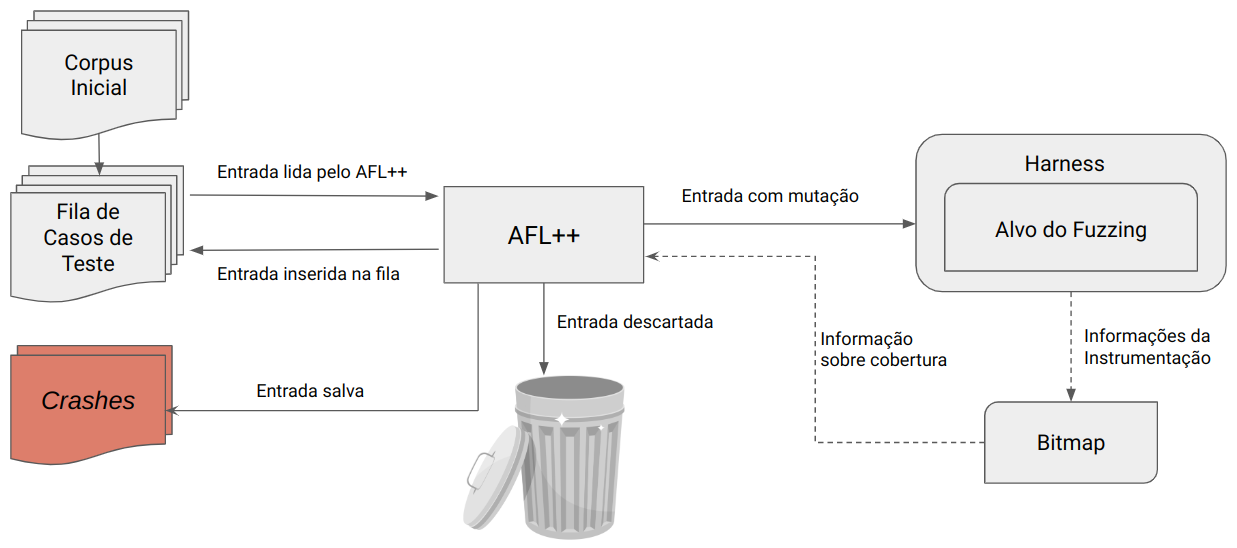
Passo a passo simplificado do algoritmo:
- inicialmente, o AFL++ carrega os casos de teste do corpus inicial para a fila de casos de teste;
- ele então carrega a próxima entrada da fila de casos de teste;
- realiza mutações na entrada e executa o alvo com a entrada mutada;
- observa o feedback da execução;
- se a entrada com mutação não encontrou nenhum caminho novo no programa, ela é descartada. Se encontrou um caminho novo, ela é inserida na fila de casos de testes. E caso ela tenha causado um crash no programa, ela é salva para análise futura;
- volta para o passo 2.
O AFL++, periodicamente, analisa a fila de casos de teste para remover entradas obsoletas que podem ser substituídas por novas que contém uma cobertura maior, além de realizar outros passos com o objetivo de otimizar o processo de fuzzing [8].
Superando Obstáculos
Alguns programas, mesmo com o auxílio de feedback, possuem partes especialmente difíceis de serem alcançadas com entradas aleatórias. Dentre esses obstáculos, estão comparações com inteiros muito grandes (32 ou 64 bits), checagem de strings, checksums, validação de magic bytes, entre outros. Por exemplo, o trecho de código abaixo compara a entrada do usuário com um inteiro de 32 bits. Para que o fuzzer execute o código inseguro dentro do if, ele precisa acertar os 32 bits de uma vez, pois se o fuzzer gera entradas incorretas próximas do valor correto como “0xabad1deb” ou entradas ruins como “0x00000000”, o branch coverage (feedback) é sempre o mesmo.
if (entrada == 0xabad1dea)
/* código inseguro */
else
/* código seguro */
Por conta de obstáculos como esses, diversas técnicas foram desenvolvidas para auxiliar o processo de fuzzing.
Dicionário
A primeira técnica é o uso de dicionários. Um dicionário no contexto de fuzzing é um conjunto de tokens que possuem algum significado especial para o programa que está sendo testado. O fuzzer então utiliza esses tokens durante a mutação das entradas, aumentando a chance de gerar uma entrada que mude o comportamento da aplicação.
A imagem abaixo ilustra alguns símbolos de um dicionário de JSON.

Além disso, pode-se criar uma lista com todas as strings do programa – rodando o utilitário strings no Linux, por exemplo – e utilizar essa lista como dicionário, aumentando a chance de que o fuzzer consiga passar por comparações com valores hard-coded.
Laf-Intel
Uma outra técnica é conhecida como “Laf-Intel”. O foco dessa técnica é quebrar comparações difíceis para o fuzzer passar em outras menores. Abaixo, estão dois trechos de código que na prática realizam a mesma coisa, ou seja, executam o código inseguro quando o valor do input for igual a “0xabad1dea”. Porém, o primeiro código faz isso em uma única comparação, enquanto o segundo realiza quatro comparações aninhadas. [13]
if (input == 0xabad1dea)
/* código inseguro */
else
/* código seguro */
if (input >> 24 == 0xab)
if ((input & 0xff0000) >> 16 == 0xad)
if ((input & 0xff00) >> 8 == 0x1d)
if ((input & 0xff) == 0xea){
/* código inseguro */
goto end;
}
/* código seguro */
end:
A vantagem do segundo código é que se a entrada gerada pelo fuzzer tiver o primeiro byte correto (0xab), o código passa a executar a segunda comparação e, caso o segundo byte (0xad) também esteja correto, ele executará a terceira comparação, e assim por diante, gerando um branch coverage diferente para cada byte que o fuzzer “acertou”. Dessa forma, o fuzzer volta a utilizar os benefícios do feedback.
Code Patching
Alguns códigos realizam checksums e outros tipos de checagem ou validações complexas na entrada, de forma que o AFL++ teriam muitas dificuldades em gerar uma entrada que fosse válida. Nesses casos, uma possível saída será, simplesmente, remover essas checagens do código-fonte e compilar o binário alvo sem essas checagens. Basta lembrar de testar os eventuais crashes encontrados em um binário compilado com as checagens (talvez sejam necessárias algumas modificações manuais na entrada) para observar se a vulnerabilidade realmente existe, ou se ela surgiu por conta das alterações no código.
RedQueen (Input-to-State Correspondence)
RedQueen é a implementação de uma técnica que se aproveita do fato de que, muitas vezes, as comparações e checksums são realizadas com pedaços da entrada. Ou seja, os valores que estão na memória ou nos registradores, em dado momento da execução, são retirados da entrada sem transformações ou passando apenas por alguma transformação simples. Os autores do paper chamam essa correlação de “Input-to-State Correspondence”, ou “Correlação Entrada-Estado” em tradução livre. [9]
Para ilustrar de maneira simplificada a ideia por trás dessa técnica, vamos considerar um programa que realiza checagem dos Magic Bytes do arquivo de entrada. Esse programa em específico lê os primeiros bytes da entrada e os compara com “ABCD”.
Vamos supor que o fuzzer, inicialmente, envie uma entrada contendo os bytes “0xAABBCCDDEEFF” e monitore o estado do programa ao encontrar operações de comparação:

No exemplo acima, o programa compara o conteúdo do registrador “eax” com “0x44434241”, porém, o valor contido no registrador nessa execução é “0xAABBCCDD”. O fuzzer cria uma regra de substituição e troca “0xAABBCCDD” por “0x44434241” na entrada, na esperança de que esse valor do registrador tenha sido lido diretamente da entrada.

Caso a substituição tenha sucesso, uma futura execução passará pela checagem com sucesso, conforme demonstração a seguir:

Sanitizadores
Programas escritos em C/C++ sofrem, com alguma frequência, problemas com gerenciamento de memória que podem gerar riscos de segurança. Porém, muitas vezes, estes erros não causam um crash e, com isso, o AFL++ não consegue detectar quando um desses problemas está presente.
Para resolver essa limitação, podem ser utilizadas ferramentas conhecidas como “sanitizadores”, como o ASan (AddressSanitizer).
O ASan detecta alguns erros de memória, como buffer overflows, use after free, memory leaks etc, em tempo de execução, mesmo quando estes erros não causam um crash no programa. É uma ferramenta muito útil para desenvolvedores identificarem problemas no gerenciamento de memória, mas ela também pode ser útil para fuzzing, pois, consegue ‘forçar’ um crash sempre que encontrar algum problema, e com isso o AFL++ passa a detectá-los.
O ASan funciona substituindo as funções de alocação e liberação de memória (malloc e free) por funções próprias que mantém o controle de quais regiões de memória foram alocadas pelo programa e quais foram liberadas. Ele, a seguir, adiciona checagens antes de todo acesso ou escrita de memória, algo como o ilustrado pelo pseudocódigo abaixo: [7]
// checagem do ASan
if (IsPoisoned(address)) {
ReportError(address, kAccessSize, kIsWrite);
}
// escrita ou leitura
*address = var;
var = *address;
O controle das regiões alocadas e liberadas da memória se dá pela chamada “shadow memory”. Cada 8 bytes de memória são mapeados em 1 byte na shadow memory.
Ao executar o malloc da biblioteca do ASan, a região da shadow memory correspondente a região alocada tem seus valores limpos, ou de acordo com a nomenclatura usada pelo ASan, a região é unpoisoned. Além disso, ele marca as regiões ao redor da região alocada como sendo poisoned, que são denominadas red-zones.
Já ao executar o free, toda a região da shadow memory correspondente a região liberada é marcada como poisoned. E a região é adicionada a uma quarentena, para que ela permaneça sem ser alocada por um tempo.
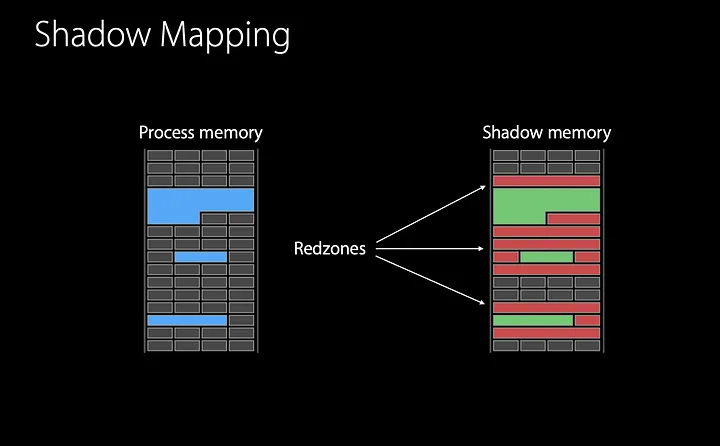
Assim, sempre que o programa for acessar uma região da memória, o ASan irá observar a região correspondente na shadow memory, se ela estiver poisoned, o ASan reportará um erro, caso contrário, seguirá a execução normalmente. A ação garante que o programa só realize operações dentro da região de memória que está alocada.
Existem outros sanitizadores além do ASan, e vale pesquisar para saber qual sanitizador pode ajudar a encontrar problemas no alvo que estiver sendo testado.
Na Prática
Para mostrar um exemplo prático do uso do uso do AFL++ vamos tentar encontrar problemas de segurança no MPV, um player de vídeo open source. Como o MPV é um programa complexo, o foco nesta prática será nos módulos que envolvem o processamento de arquivos mkv.
Instrumentação e Modificações no Código
Por termos acesso ao código-fonte, foi utilizada a instrumentação do AFL++ para obter o feedback sobre cada execução. Mais especificamente, foi utilizado o afl-clang-lto que possui algumas otimizações para evitar colisões na geração dos IDs aleatórios que representam cada bloco de código.
Para realizar a compilação e instrumentação do alvo com o afl-clang-lto foram realizadas algumas mudanças nos arquivos de compilação fornecidos no github do projeto. A imagem abaixo ilustra as alterações em um trecho do script, com a mudança do compilador utilizado e a adição de algumas flags para configuração de recursos do AFL++, como a instrumentação parcial e o ASan.

Ao executar o fuzzer pela primeira vez no binário compilado, a quantidade de execuções por segundo se encontrava muito baixa.
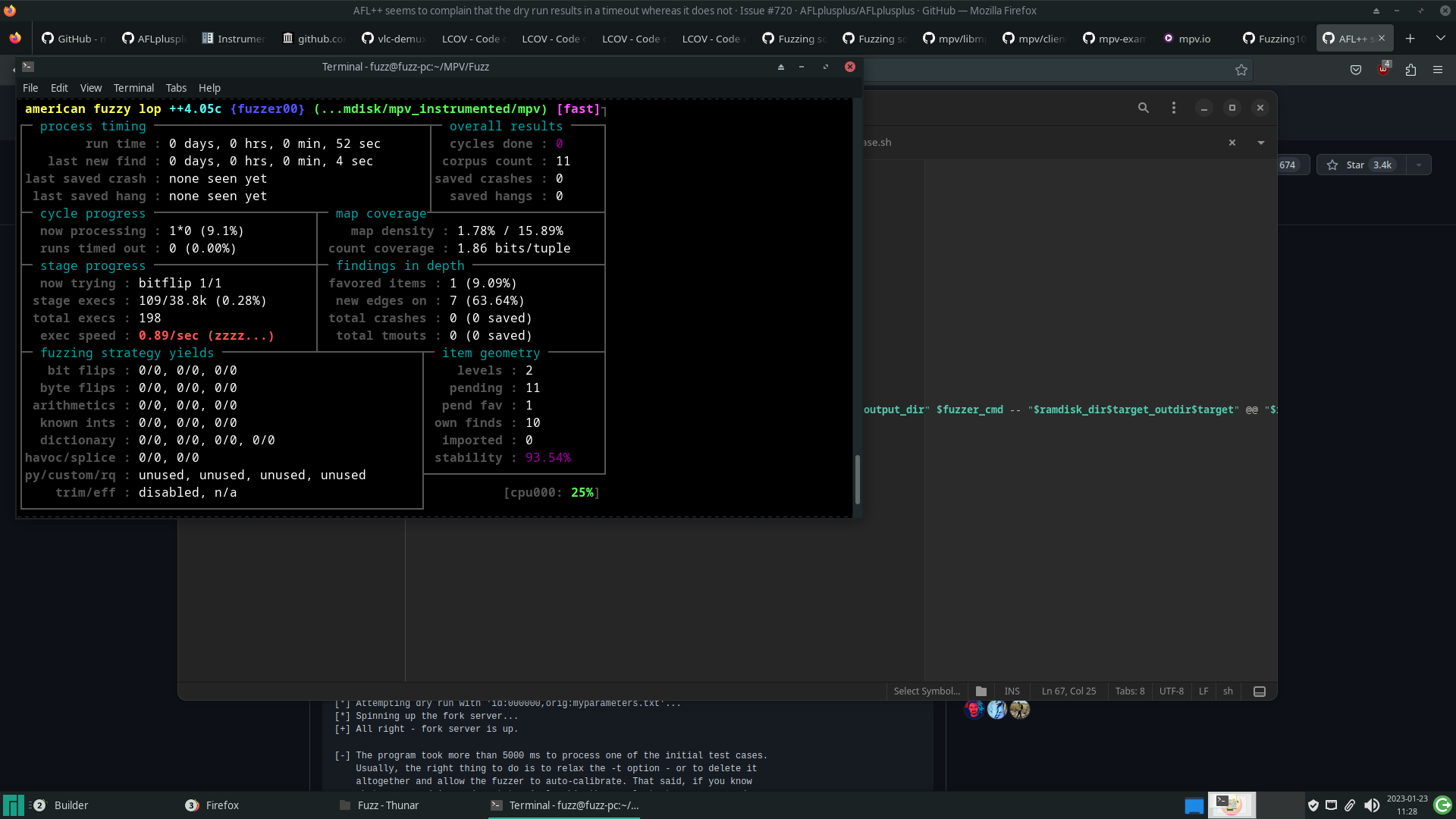
Essa limitação se deu, pois, para cada execução do AFL++, o player realiza toda a sua inicialização, reproduz completamente o vídeo e, por fim, finaliza-o. Realizar todo esse processo em cada execução demanda muito tempo.
Uma primeira tentativa foi alterar o código do MPV para que a execução fosse interrompida logo após a inicialização e os primeiros processamentos terem sido realizados no arquivo de entrada, ilustrado pela figura abaixo, com a adição da linha 1679.
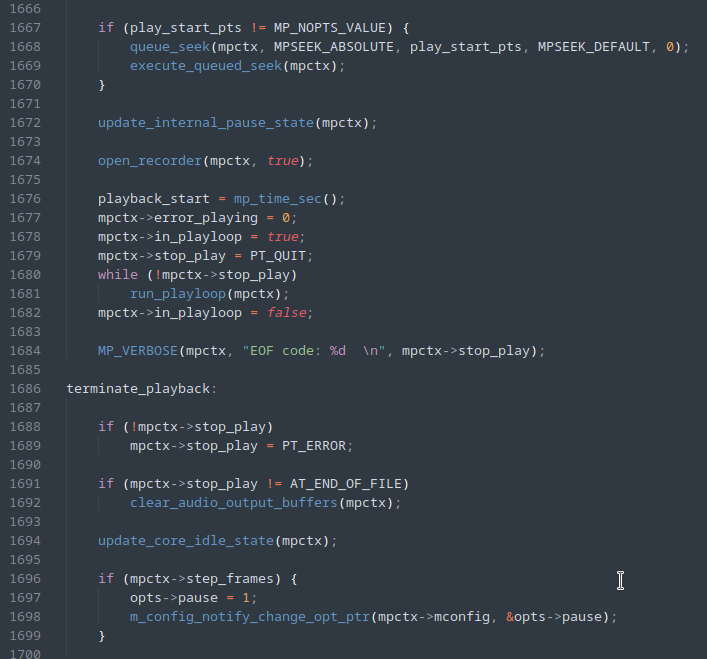
Ao executar, novamente, o fuzzer com as modificações acima, podemos observar uma melhora na velocidade.
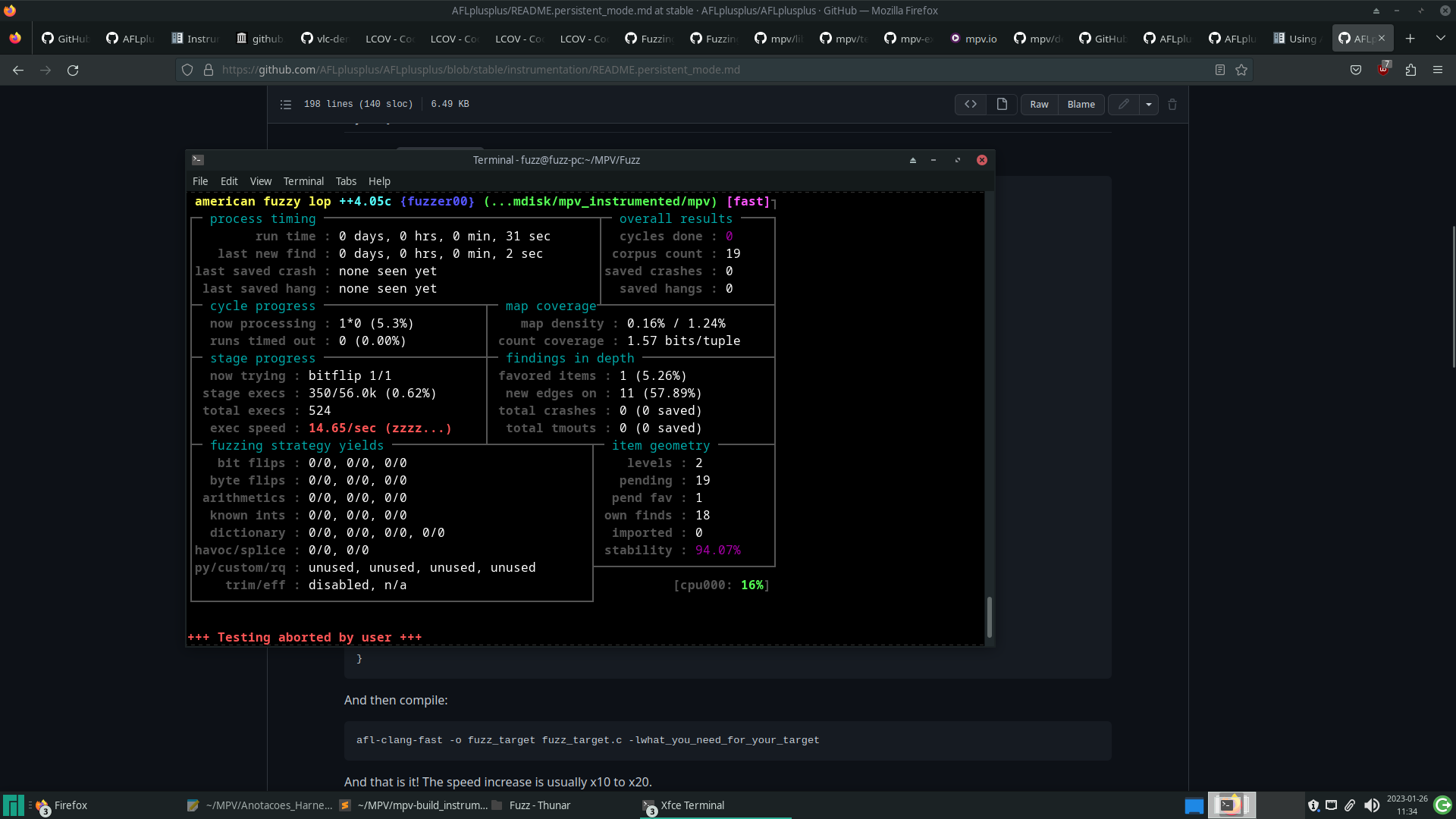
Porém, o programa ainda realiza todo o processo de inicialização e de finalização para cada nova entrada sendo executada. Uma alternativa é o uso do persistent mode do AFL++, ao qual é adicionado um laço de repetição especial no código, que executa uma mesma parte do código para diversas entradas diferentes, aproveitando-se de um único processo de inicialização do programa.
A mudança no código pode ser vista na imagem abaixo.
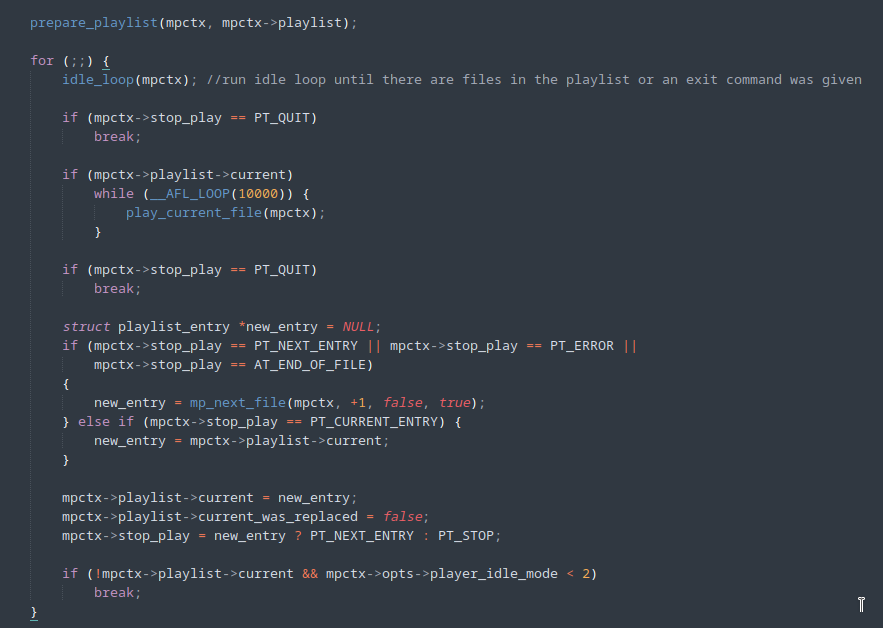
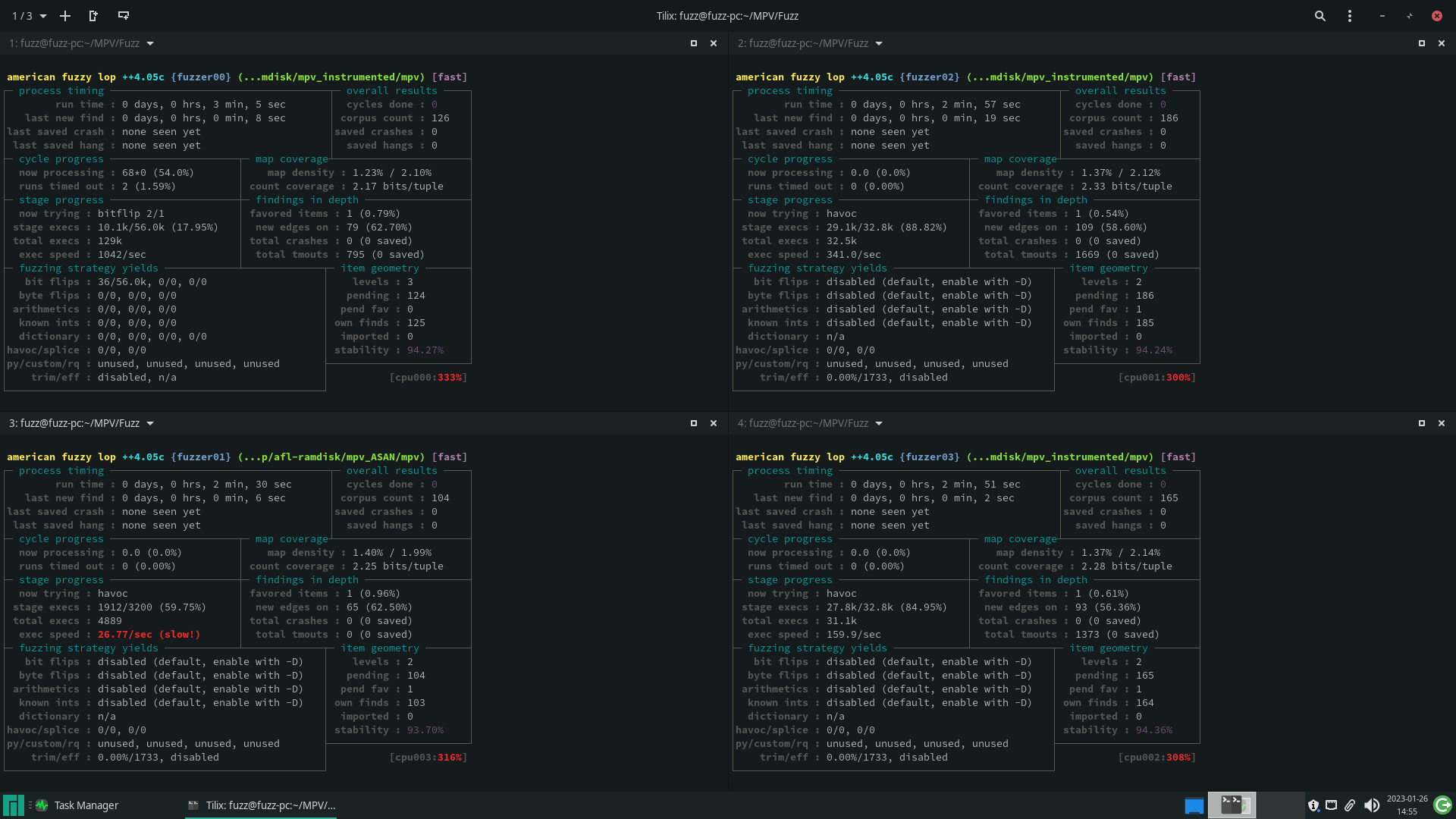
Ao utilizar o persistent mode, a velocidade de fuzzing subiu consideravelmente.
Instrumentação Parcial
Programas complexos como o MPV possuem diversos arquivos ou módulos responsáveis por diferentes funções. Alguns responsáveis pelo controle da interface gráfica, outros pelo gerenciamento das legendas, além de diferentes arquivos para lidar com os diferentes formatos de mídia suportados pelo programa. Por conta dessa complexidade, o fuzzer encontra uma quantidade muito grande de possíveis ramificações, o que pode diminuir bastante sua efetividade.
Como exemplo do que afirmamos anteriormente, podemos imaginar uma campanha de fuzzing utilizando alguns arquivos MKV no corpus. Em algum momento, uma mutação pode alterar os arquivos de entrada de modo que eles passem a ser reconhecidos como arquivos AVI. Com isso, diversas funções específicas para processamento de AVI passam a ser executadas. As entradas são marcadas como interessantes e adicionadas de volta à fila de casos testes. O fuzzer passa a utilizar esses arquivos “AVI” como base para novas mutações, com isso, ele deixa de focar nos módulos que processam MKV, e o pior, o faz de maneira muito ineficiente, pois esses novos arquivos, apesar de serem reconhecidos como AVI, possuem em sua maior parte uma estrutura de MKV. [14]
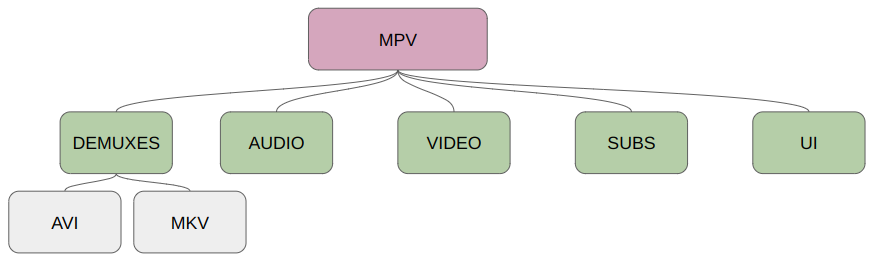
Uma maneira de manter o fuzzer focado em alguns arquivos ou funções específicas é utilizar a instrumentação parcial. Nesta técnica, é passada uma lista de arquivos ou funções para o compilador, e somente esses trechos de código serão monitorados pelo fuzzer, qualquer mutação que cause novas ramificações fora desses trechos é ignorada.
Como o foco inicial dessa campanha de fuzzing é no processamento de arquivos MKV, o trecho abaixo mostra parte da lista de arquivos e funções que foram monitoradas pelo AFL++ durante o processo de fuzzing.
demux/cue.c demux/demux.c demux/demux_mkv.c demux/timeline.c stream/*.c audio/*.c #cue.c fun: lstrip_whitespace fun: read_cmd fun: eat_char fun: read_quoted fun: read_int fun: read_time fun: skip_utf8_bom fun: mp_probe_cue fun: mp_parse_cue fun: mp_check_embedded_cue #demux.c fun: get_foward_buffered_bytes fun: check_queue_consistency fun: set_current_range
Preparando a Campanha
Após as mudanças no código, foram compilados cinco binários com o afl-clang-lto, utilizando distintas configurações de compilação:
- um binário compilado normalmente;
- um binário compilado com o ASan;
- um binário compilado com o módulo LFINTEL;
- um binário compilado com o módulo RedQueen;
- Um binário com o LCOV, utilizado para monitorar de forma mais fácil a cobertura de código obtida pelos casos de teste.
Foram também obtidas amostras de vídeo no formato MKV para compor o corpus inicial. É interessante que essas amostras contenham informação suficiente para que o player execute o máximo de trechos de código que se deseja testar, porém, de maneira geral, quanto maior forem esses arquivos, mais lento será o processo de fuzzing. Montar um bom corpus envolve encontrar o máximo de cobertura de código com o mínimo de overhead de execução.
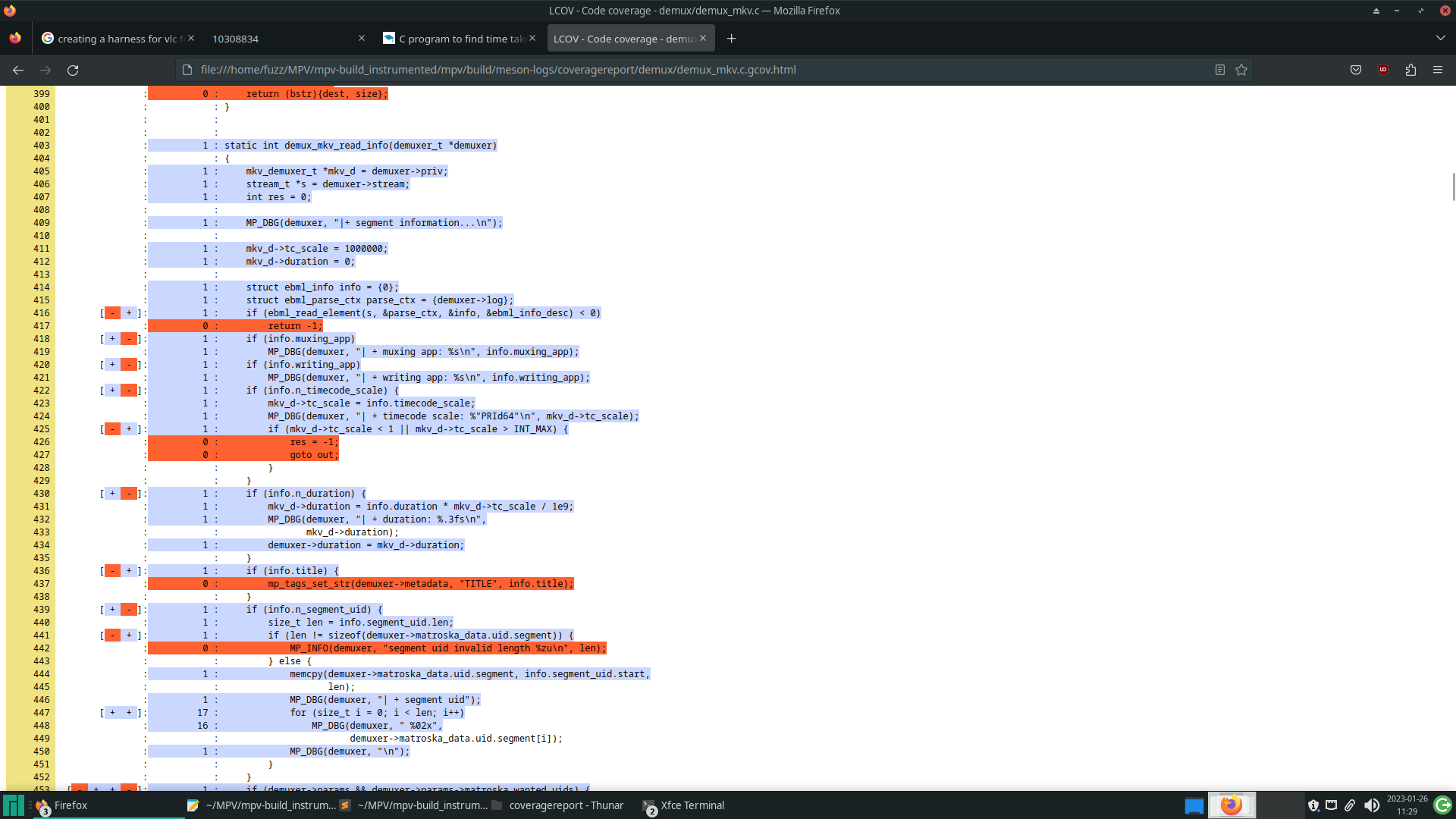
Antes de iniciar a campanha de fuzzing, é importante validar se, após as mudanças, os trechos de código que se deseja testar ainda estão sendo executados, além de, também, avaliar a cobertura de código do corpus inicial. A ferramenta utilizada nesta prática foi o LCOV, que é uma interface gráfica que obtém os resultados do gcov, uma ferramenta para obter informações sobre a cobertura de código de programas, apresentando-os de uma forma mais legível.
A imagem abaixo mostra os resultados do LCOV sobre um trecho de código, obtido após a execução do corpus. As linhas marcadas em azul foram executadas pelo programa e, ao início de cada linha, existe uma contagem de quantas vezes ela foi executada.
Por fim, foi criado um dicionário contendo as sequências de bytes que possuem significado especial em um arquivo do formato MKV.
Executando o fuzzer
Durante a execução da campanha, o AFL++ pode realizar bilhões de operações de escrita e leitura em disco. Em alguns casos, isso pode acarretar um desgaste prematuro no HD ou SSD. Para contornar esse possível problema, foi utilizado um ramdisk, armazenamento volátil que utiliza a RAM para armazenar os arquivos e, por consequência, as operações de leitura e gravação passam a ser executadas na memória RAM e não no SSD.
Para cuidar da inicialização de todas as instâncias do AFL++, foi utilizado um script baseado no auto-afl [12]. O script montado auxiliava, ao criar o ramdisk, inicializar todas as instâncias do fuzzer, fazer backups periódicos – vale lembrar que o processo estava em RAM, que é uma memória volátil – e realizar otimizações na fila de casos de teste após longos períodos de campanha.
Monitorando a Campanha
A campanha AFL++ traz diversas informações sobre o progresso do fuzzing, como o tempo total de execução, o tempo desde a última nova descoberta, a quantidade de crashes e timeouts encontrados, entre outros. A partir da análise dessas informações, é possível avaliar se o processo está progredindo como esperado ou se está estagnado.
Caso o progresso não esteja progredindo como esperado, uma possibilidade é utilizar novamente ferramentas como o LCOV para observar a cobertura de código que está sendo obtida com os casos atualmente presentes nas filas de teste. Com isso, pode ser possível identificar trechos de código em que o fuzzer não consegue atingir e, pode-se, manualmente, criar novos inputs que façam o programa executar esses trechos.
Uma maneira de ‘ensinar’ o fuzzer sobre esses novos inputs é iniciar uma nova instância temporária do AFL++ contendo esses novos arquivos criados manualmente como corpus e deixá-la executando por um tempo. Essa nova instância executará esses trechos que ainda não foram explorados pelas demais e, após um período de tempo, as demais instâncias sincronizarão entre si, obtendo as entradas baseadas nesses novos inputs. Após isso, a instância temporária pode ser parada.
Resultado
Essa pesquisa com fuzzing foi parte do meu período de estágio na Tempest e, por conta disso, o tempo de execução da campanha foi limitado. Após alguns dias de execução, nenhuma instância do AFL++ havia encontrado algum crash válido e diferentes fatores podem ter gerado esse resultado.
O primeiro fator pode ter sido as mudanças realizadas no código-fonte, que foram muito simples. O binário como testado pelo AFL++ executava somente algumas das funções que o player executaria ao reproduzir arquivos de vídeo e, apesar do LCOV mostrar uma razoável cobertura de código nos principais arquivos alvos do fuzzing, uma análise mais detalhada sobre o funcionamento do player pode resultar em melhores modificações no código ou até na criação de um harness que deixe o processo de fuzzing mais efetivo.
Outro fator pode ser o tempo de campanha, talvez com um maior tempo de fuzzing alguma entrada que executasse um trecho de código vulnerável poderia ter sido gerada. Além de diversos outros detalhes que podem ser melhorados, como montar um corpus inicial melhor.
Referências
[1] MORALES, A. Fuzzing-101. Disponível em: <https://github.com/antonio-morales/Fuzzing101>. Acesso em: 15 dez. 2023.
[2] Fuzzing in Depth. Disponível em: <https://aflplus.plus/docs/fuzzing_in_depth>. Acesso em: 15 dez. 2023.
[3] Fuzz Testing of Application Reliability. Disponível em: <http://www.cs.wisc.edu/~bart/fuzz/>. Acesso em: 15 dez. 2023.
[4] FIORALDI, A. et al. AFL ++ : Combining Incremental Steps of Fuzzing Research. [s.l: s.n.]. Disponível em: <https://www.usenix.org/system/files/woot20-paper-fioraldi.pdf>. Acesso em: 15 dez. 2023.
[5] Technical “whitepaper” for afl-fuzz. Disponível em: <https://lcamtuf.coredump.cx/afl/technical_details.txt>.
[6] How Fuzzing with AFL works! | Ep. 02. Disponível em: <https://youtu.be/COHUWuLTbdk>. Acesso em: 15 dez. 2023.
[7] Address Sanitizer Algorithm. Disponível em: <https://github.com/google/sanitizers/wiki/AddressSanitizerAlgorithm#short-version>. Acesso em: 15 dez. 2023.
[8] Afl Fuzz Approach. Disponível em: <https://aflplus.plus/docs/afl-fuzz_approach/>. Acesso em: 15 dez. 2023.
[9] REDQUEEN: Fuzzing with Input-to-State Correspondence – NDSS Symposium. Disponível em: <https://www.ndss-symposium.org/ndss-paper/redqueen-fuzzing-with-input-to-state-correspondence/>.
[10] How to Build a Fuzzing Corpus. Disponível em: <https://blog.isosceles.com/how-to-build-a-corpus-for-fuzzing/>. Acesso em: 15 dez. 2023.
[11] Matroska Element Specification. Disponível em: <https://www.matroska.org/technical/elements.html>. Acesso em: 15 dez. 2023.
[12] RENWAL. auto-afl. Disponível em: <https://github.com/RenWal/auto-afl/>. Acesso em: 15 dez. 2023.
[13] laf-intel. Disponível em: <https://lafintel.wordpress.com/>.
[14] ANTONIO-MORALES. Fuzzing software: common challenges and potential solutions (Part 1). Disponível em: <https://securitylab.github.com/research/fuzzing-challenges-solutions-1/>. Acesso em: 15 dez. 2023.