Por Maria Fernanda Rodrigues Vieira e Silva
O uso de Machine Learning (ML) na área de segurança da informação possui um grande potencial que vem se desenvolvendo cada vez mais ao passar do tempo (IBM, 2022). O seu uso pode ser direcionado a vários objetivos, como, por exemplo, detecção de intrusão, detecção de fraudes e detecção de vulnerabilidades. No contexto de detecção de vulnerabilidades, podemos destacar três tipos de técnicas para identificar possíveis superfícies de ataque em aplicações:
- Técnicas estáticas: baseiam-se na análise de código-fonte;
- Técnicas dinâmicas: analisam o software em tempo de execução;
- Técnicas híbridas: combinam técnicas estáticas e dinâmicas.
Neste artigo, explicaremos como funciona o Functionally-similar yet Inconsistent Code (FICS) (AHMADI, 2021), um mecanismo de detecção de vulnerabilidade que é baseado em técnicas estáticas para analisar a similaridade e identificar inconsistências em códigos, que, por sua vez, podem representar bugs que causam falhas de segurança. De modo geral, esse mecanismo utiliza uma representação customizada do código-fonte na forma de grafo em conjunto com o algoritmo de ML de clusterização hierárquica. Nas seções a seguir, explicaremos o funcionamento do FICS (AHMADI, 2021) e quais as suas vantagens e principais resultados. Em seguida, apontaremos quais as limitações desse sistema e o que poderia ser feito para melhorá-lo.
Functionally-similar yet Inconsistent Code (FICS)
Para analisar e encontrar inconsistências em códigos-fonte, o FICS recebe o código-fonte de um software escrito em C, o transcreve para a linguagem de representação intermediária do compilador Low Level Virtual Machine (LLVM) (BAKSHI, 2022) e o transforma em grafos chamados de “constructs”, que, por sua vez, são vetorizados.
A partir disso, os vetores dos constructs passam por uma primeira clusterização cujo objetivo é agrupar representações que se parecem. Essa primeira clusterização possui um filtro mais “grosseiro”, mais permissivo, que permite a criação de uma quantidade menor de clusters, cada um com uma quantidade maior de elementos.
Em seguida, o FICS realiza uma segunda clusterização cujo objetivo é identificar, dentro dos grupos criados na primeira clusterização, os vetores que diferem entre si. Assim, aplica-se um filtro mais “fino”, menos permissivo, que nos permite identificar essas diferenças, destacando os vetores que se parecem, mas que possuem alguma inconsistência na sua construção.
Por fim, essas diferenças encontradas na construção dos vetores, chamadas de bugs pelo FICS, são apresentadas a um analista em formato de código, para que este identifique se elas podem causar falhas de segurança. A Figura 1 é uma representação macro dos principais passos realizados pelo FICS. (AHMADI, 2021 e AHMADI, 2022)
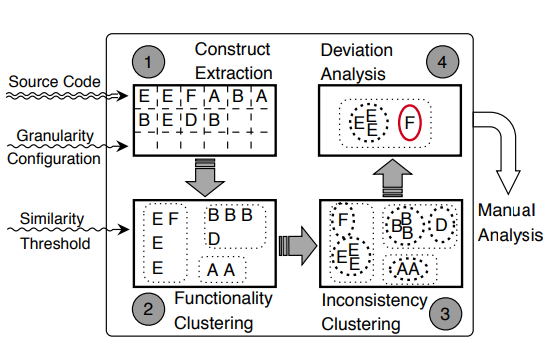
Se você ainda estiver se questionando “Ok… Mas ainda não entendi como todo esse processo funciona…” está tudo certo. Então, vamos explicar melhor a seguir!
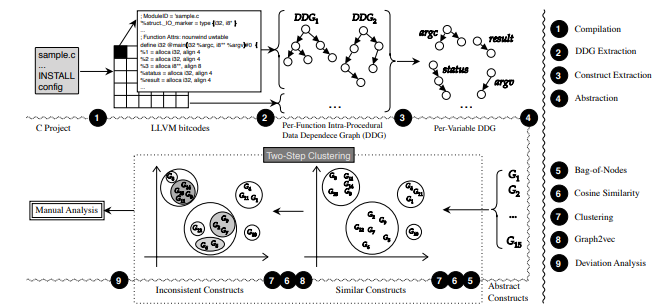
Podemos ver melhor na figura 2 os passos realizados pelo FICS, os quais podem ser subdivididos em quatro partes, que são detalhadas a seguir:
- Transformação do Código em Vetores;
- Primeira Clusterização;
- Segunda Clusterização;
- Análise Manual.
Parte 1: Transformação do Código em Vetores
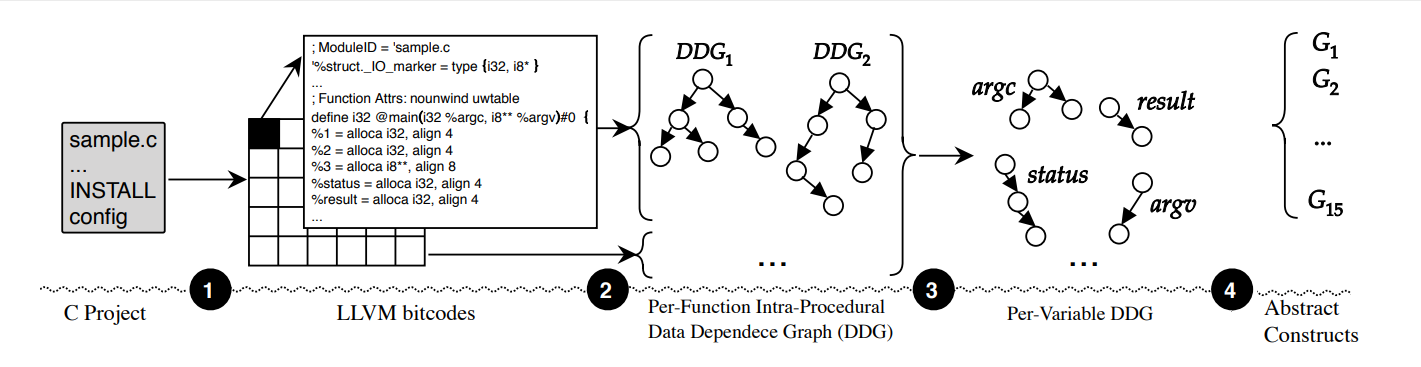
Como apresentado, em sua primeira etapa, o FICS transforma códigos-fonte em representações passíveis de serem clusterizadas. Para isso, realiza quatro ações, como indicadas na Figura 3: i) compilação, ii) extração de data dependence graphs (DDGs) e formação de constructs, iii) abstração de constructs e iv) bag of nodes.
Compilação
O objetivo desse passo é compilar o projeto em C e representá-lo na forma de bitcode (.bc). O sistema utiliza o compilador LLVM que possui as ferramentas OPT, responsável pela otimização do código no processo de compilação e Clang, responsável pela tradução do código C em bitcode, como podemos ver na Figura 4. (CHRISTOPHER, 2022)
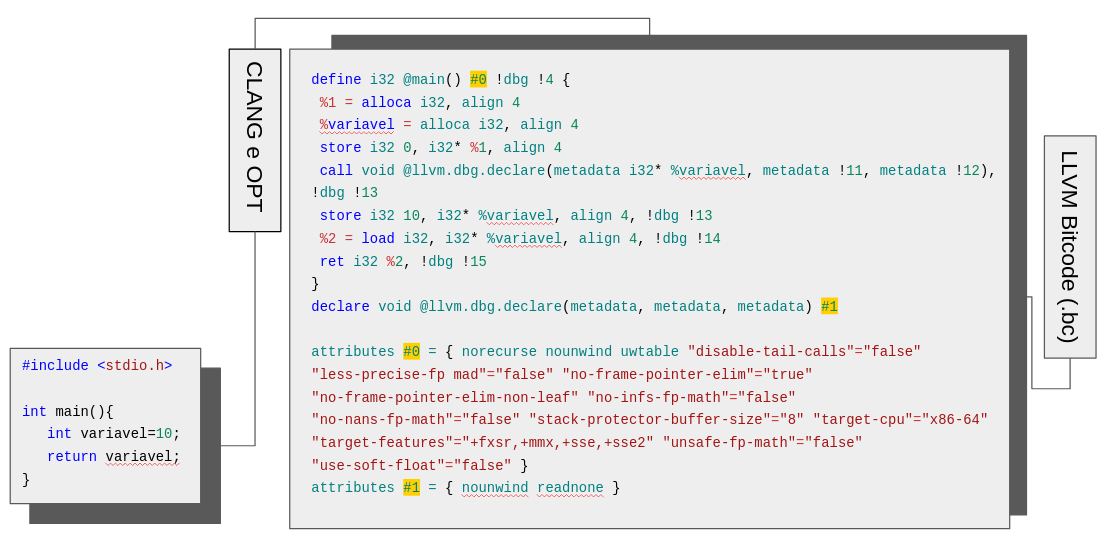
Com essa representação, extraímos as partes mais importantes das computações ocorrendo no código-fonte, indicadas na cor azul, como, por exemplo, a instrução alloca, responsável por alocar memória na pilha da função que está em execução, a instrução store, responsável por escrever instruções na pilha de memória da função em execução, e a instrução load, responsável por ler instruções da memória. Mais informações sobre essas operações podem ser encontradas em (LLVM Foundation, 2023).
Extração dos Data Dependence Graph e Formação dos Constructs
Após converter o código fonte para bitcode, o FICS extrai DDGs, que são grafos que representam como as várias partes do código se relacionam, de todas as funções presentes no código. Assim, obtém-se, na forma de grafos, a forma com a qual as funções do código-fonte se relacionam. A Figura 5 ilustra a extração de DDGs de uma função em C.
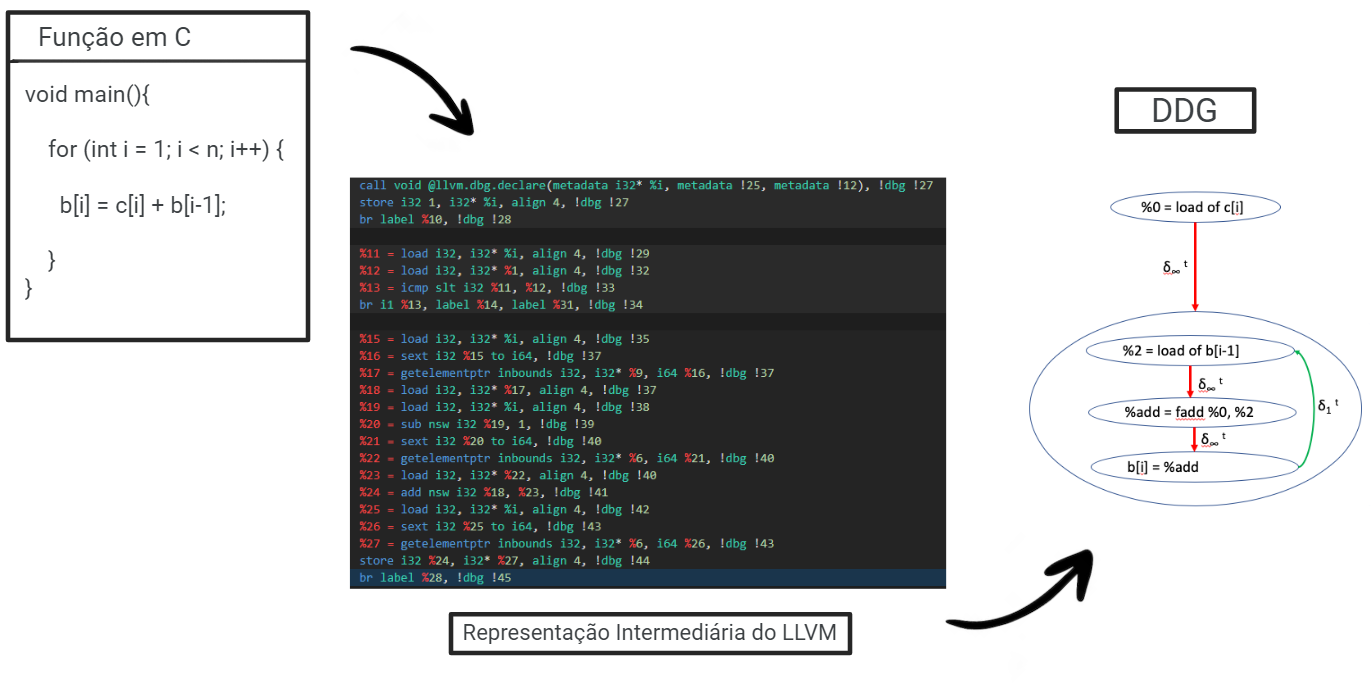
Mas, como funciona essa representação em grafo? Vamos ver rapidamente. Podemos definir os grafos em duas estruturas, os Nodes, que representam declarações, predicados, operações ou operandos relacionados aos elementos do código, e as Edges, que representam as dependências dos nodes entre si. São considerados uma das melhores formas de representação de código, visto que é possível explicitar graficamente as interdependências dos nodes durante todo o projeto.
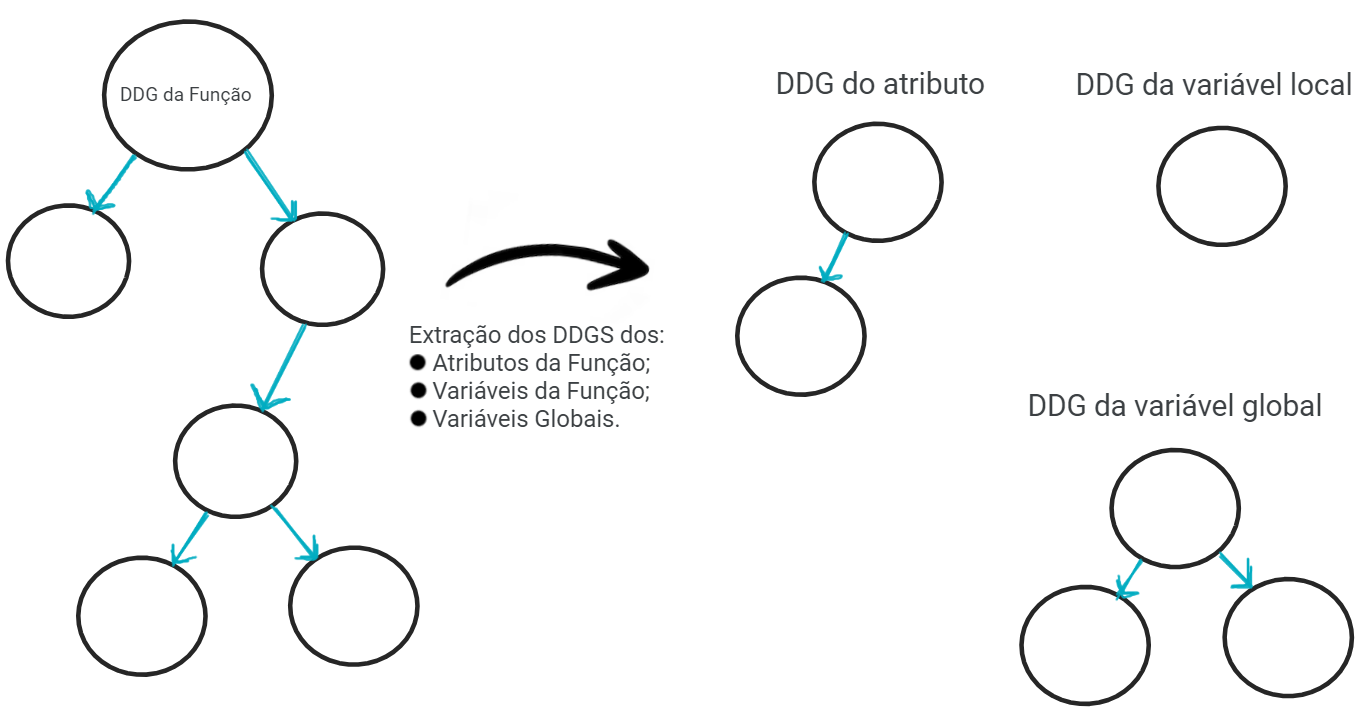
Após a extração dos DDGs das funções, o FICS faz uma segunda extração de DDGs, mas agora para todos os atributos, variáveis locais e variáveis globais do código, como exemplificado na Figura 6.
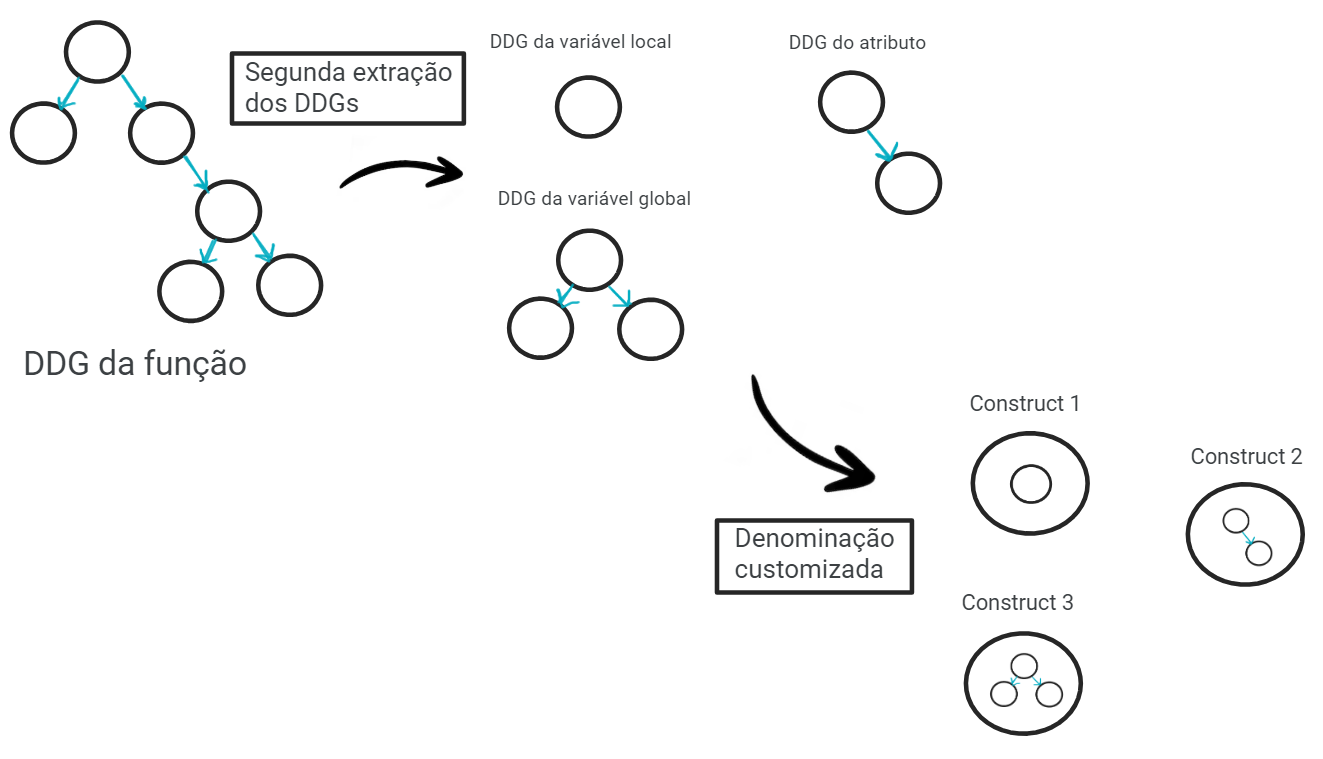
Os autores do FICS propõem uma representação customizada do código, chamada de Construct, que são construídos através dos resultados desta segunda extração dos DDGs. Cada elemento do código terá a sua representação na forma de construct, explicitando as suas dependências por todo ele, como podemos ver nas figuras 7 e 8.
Abstração dos Constructs
Após a extração dos constructs, algumas informações são descartadas, como, por exemplo, o nome das variáveis, as versões, as constantes e literais. Permanecem apenas os tipos das variáveis e as computações mais importantes, indicadas no processo de compilação. Como exemplo, a figura 9 apresenta o construct, na sua forma abstraída, da variável data da função. É possível reconhecer apenas as operações feitas e os tipos dos dados.
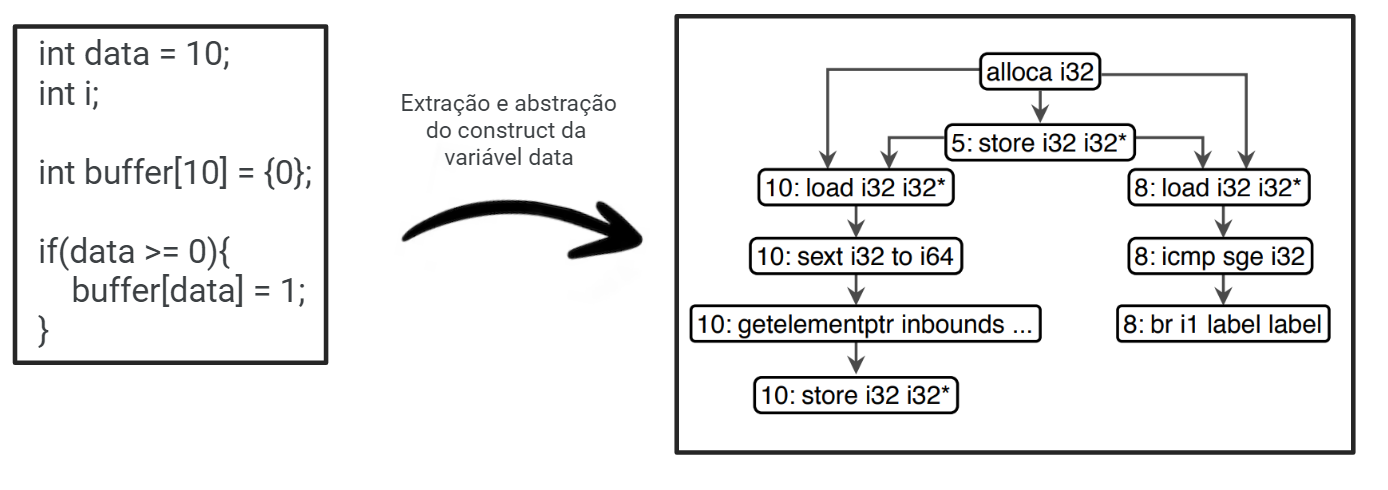
Bag of Nodes
Depois da abstração, o próximo passo é a construção de embeddings para os constructs abstraídos. Embedding se refere às técnicas de transposição de informações de um objeto complexo para um mais simples, em nosso caso, na transformação de uma estrutura de grafos, que possui uma complexidade maior, em vetores, que possui uma complexidade menor. O FICS utiliza o embedding bag of nodes que transforma os grafos dos constructs abstraídos em vetores. Esse processo ocorre de forma que cada operação presente no node, tal como alloca i32, store i32 i32*, load i32 i32*, icmp sge i32 e br i1 label label, são alocadas para um index específico dentro de um vetor, como apresentado na figura 10.
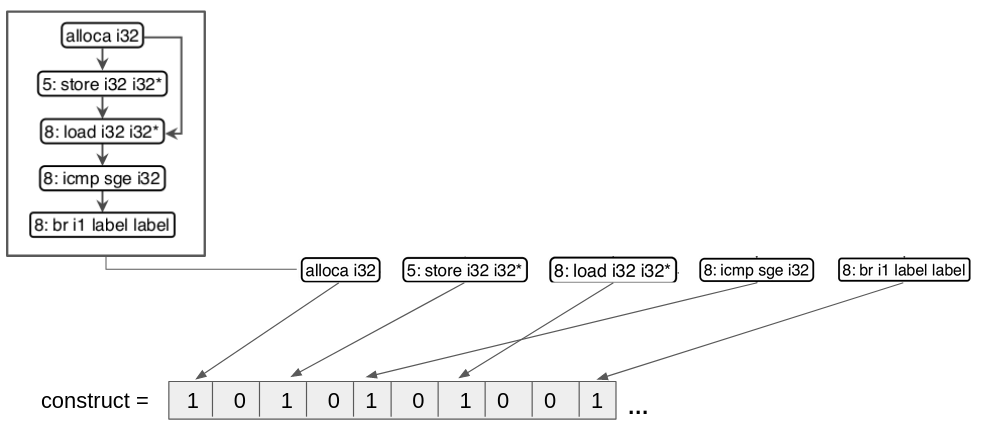
Esse processo ocorre para todos os constructs e, após isso, tem-se todo o código fonte representado por vetores.
Parte 2: Primeira Clusterização
Uma vez que o código está representado na forma de vetores, o FICS realiza uma primeira clusterização agrupando os vetores em clusters de acordo com uma métrica de distância. A métrica de distância utilizada é a medida dos cossenos, também conhecida como cosine similarity, a qual calcula a distância entre os vetores a partir do cosseno do ângulo entre eles. Quanto mais próximo de 1 o resultado for, mais similares são os vetores e vice-versa. Assim, cada par de vetores terá o seu valor de cosine similarity que será fornecido ao algoritmo connected-components, responsável pela formação dos clusters, como demonstrado na figura 11.
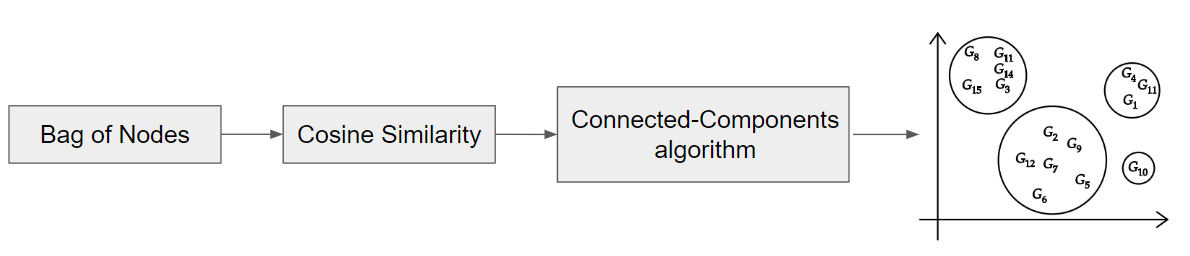
Parte 3: Segunda Clusterização
Após a criação dos primeiros clusters, será criado um segundo embedding através da ferramenta graph2vec, que também transforma grafos em vetores, e a cosine similarity é novamente aplicada entre os pares de vetores resultantes do graph2vec a segunda clusterização, com um mais filtro fino, como explicitado na figura 12.

Parte 4: Análise Manual
Por fim, as partes de código com inconsistências serão destacadas como demonstrado na figura 13 a fim de serem analisadas por um especialista de segurança, que irá verificar o real potencial dessas inconsistências gerarem problemas de segurança.
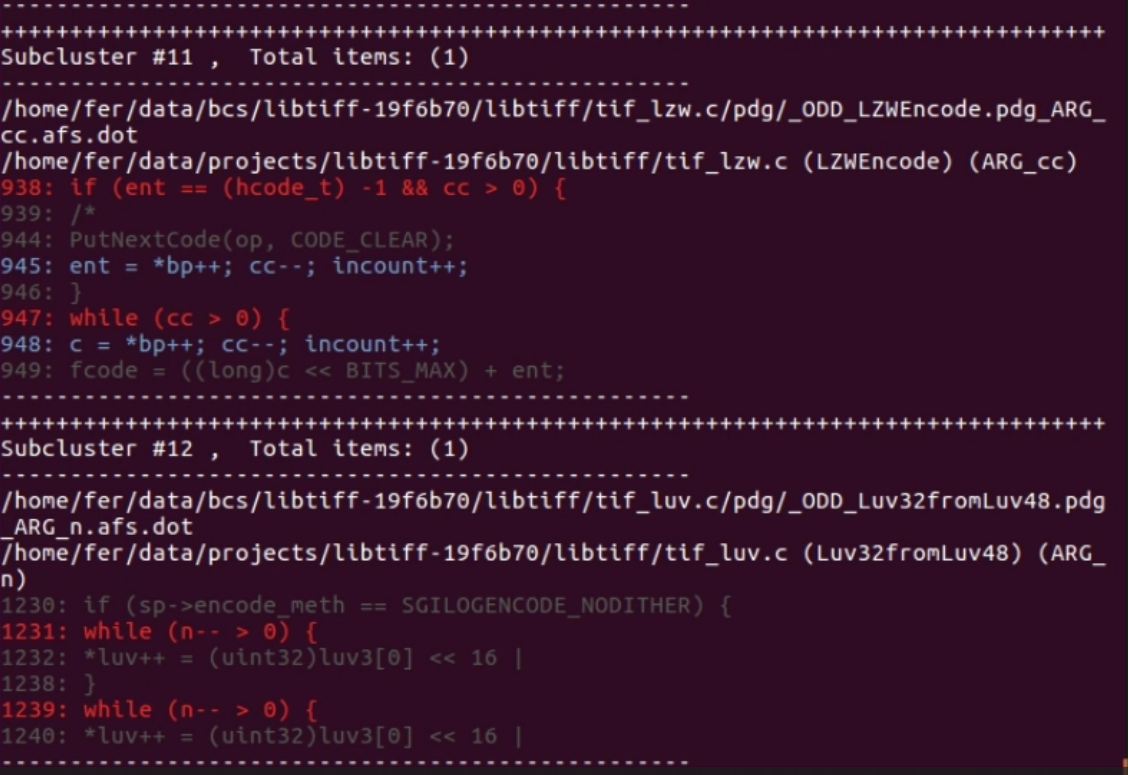
Principais Resultados
Destacamos aqui os principais resultados do FICS (AHMADI, 2022). Ele prova seu valor ao detectar 22 vulnerabilidades novas em 5 projetos diferentes, que já haviam sido testados anteriormente:
- LibTiff: 5 bugs de 93 inconsistências detectadas;
- OpenSSH: 1 bugs de 121 inconsistências detectadas;
- OpenSSL: 9 bugs de 310 inconsistências detectadas;
- QEMU: 4 bugs de 1206 inconsistências detectadas;
- WolfSSL: 3 bugs de 91 inconsistências detectadas.
Limitações e Recomendações
O sistema possui algumas limitações a serem consideradas como, por exemplo, o funcionamento para apenas uma linguagem de programação (linguagem C) e a restrição de que os códigos analisados não podem nem ser muito pequenos, pois não seria possível comparar várias partes do código entre si, e nem muito grandes, pois a representação dos constructs seria muito pesada computacionalmente.
Mediante essas limitações, fizemos algumas recomendações de melhorias para o FICS. A fim de que haja uma melhoria de performance, há a necessidade de avaliar alguma outra forma de representação do código-fonte, pois os constructs são muito pesados computacionalmente, dificultando a aplicação do FICS em projetos grandes. Além disso, a possibilidade de transferir o aprendizado de um projeto para outro, através de técnicas de transferência de conhecimento (transfer learning) por exemplo, bem como a avaliação de outros algoritmos de clusterização, poderiam proporcionar melhores resultados.
Considerações Finais:
Apresentamos neste artigo o FICS (AHMADI, 2021), um sistema que utiliza uma representação customizada de código fonte (constructs customizados) para comparar e detectar bugs, que possam gerar vulnerabilidades de segurança.
O seu grande diferencial é o fato de que ele não requer nenhum dado prévio. Toda a curva de aprendizagem é oriunda do próprio código-fonte ao qual o mecanismo é aplicado. Não é usada nenhuma base de dados de vulnerabilidades tabeladas a qual ele irá treinar e aplicar o aprendizado a outro projeto. O objetivo é achar partes do próprio código que se pareçam, mas que por qualquer motivo possuem alguma inconsistência, e assim, podem levar possivelmente a uma falha de segurança.
Todo esse processo abre portas para um vasto horizonte de possibilidades dentro do mundo de Machine Learning, mas que como vimos, ainda precisa ser muito aperfeiçoado para que possamos aplicar ao cotidiano de um profissional de segurança
Referências:
AHMADI, M. FARKHANI, R. M. WILLIAMS R., LU, L. Finding bugs using your own code: Detecting functionally-similar yet inconsistent code, in Proc. 30th USENIX Secur. Symp. (USENIX Security), 2021, pp. 2025–2040.
AHMADI, M., FARKHANI R. M., WILLIAMS, R. Finding Bugs Using Your Own Code: Detecting Functionally-similar yet Inconsistent Code. Disponível online em: https://github.com/RiS3-Lab/FICS. 2022. Acessado em 20 de Setembro de 2022.
AHMADI, M., FARKHANI R. M., WILLIAMS, R. USENIX Security ’21 Youtube video: Finding Bugs Using Your Own Code: Detecting Functionally-similar yet. Disponível online em: https://www.youtube.com/watch?v=nO7FHQEu2bc. 2021. Acessado em 20 de Setembro de 2022.
BAKSHI, Tanmay. How LLVM & Clang work. Disponível em https://www.youtube.com/watch?v=IR_L1xf4PrU. Acessado em 10 de Setembro de 2022.
CHRISTOPHER, E. DOERFERT, J. 2019 LLVM Developers’ Meeting: Introduction to LLVM. Disponível em https://www.youtube.com/watch?v=J5xExRGaIIY. Acessado em 10 de Setembro de 2022.
IBM. What is machine learning? Disponível em https://www.ibm.com/topics/machine-learning. Acessado em 15 de Setembro de 2022.
LIN, G., WEN, S., HAN, Q., ZHANG, J. AND XIANG, Y. Software Vulnerability Detection Using Deep Neural Networks: A Survey. Disponível online em: https://ieeexplore.ieee.org/document/9108283. Acessado em 15 de Setembro de 2022.
LLVM Foundation. LLVM Language Reference Manual. Disponível online em https://llvm.org/docs/LangRef.html#instruction-reference. Acessado em 20 de Setembro de 2023.