Por Ricardo Henrique
Gostaria de iniciar esse post com uma breve apresentação. Sou estagiário do setor de Consultoria da Tempest, onde realizamos projetos de segurança ofensiva. Anteriormente, atuei como engenheiro de software, desenvolvendo aplicações mobile em uma startup aqui mesmo, no Recife.
Meu interesse em migrar da área de engenharia de software para segurança ofensiva deu-se por influência do professor Marcelo Araújo. Foi ele quem me apresentou à segurança da informação, tendo sido também um guia na escolha do curso de Sistemas de Informação, que curso atualmente na Universidade Federal Rural de Pernambuco. Valeu, Marcelo!
Uma breve reflexão sobre filtragens baseadas em URL
No decorrer desse blogpost, verificaremos como falhas relacionadas à validação de condições com base em URLs podem acarretar em problemas de segurança. Avaliamos exemplos em 4 linguagens de programação: JavaScript, Java, Python e GoLang.[1] Veremos ainda como evitar que essas falhas aconteçam. Uma vez que não encontramos uma nomenclatura específica para esse tipo de problema, decidimos, para fins didáticos, chamá-los genericamente de URL Filter Subversion.
De onde surgiu a ideia?
Durante um dos pentests em que tive a oportunidade de participar como shadow, encontrei uma aplicação que possuía um comportamento anômalo.
O problema estava na funcionalidade listar usuários, que deveria ser acessada apenas pelo perfil de usuário administrador. A requisição era algo mais ou menos assim:
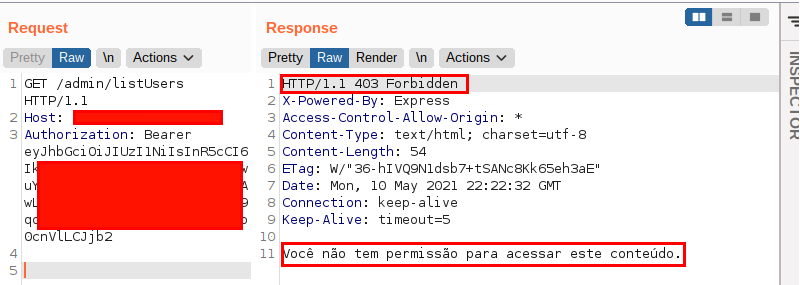
Porém, tentando alguns payloads diferentes para a construção da URL, deparei-me com o seguinte comportamento: ao inserir um parâmetro arbitrário seguido do termo js, a aplicação permitiu que eu acessasse a funcionalidade de listagem de usuários. Isso mesmo, mesmo não sendo um usuário administrativo, a aplicação realizou a ação supostamente restrita. A imagem seguinte ilustra o comportamento:

Fiquei absolutamente intrigado com o cenário e decidi consultar meus colegas. Foi assim que descobri que outro analista, Jodson Leandro, já havia se deparado com o mesmo problema e estava desenvolvendo essa pesquisa. Muito gentilmente, ele explicou do que se tratava, e me orientou a escrever esse blogpost. Valeu, Jod!
Mas afinal, o que estava viabilizando esse comportamento na aplicação? É o que veremos nos próximos tópicos.
Como desenvolvedores validam URLs para permitir acesso a determinados recursos?
Antes de ir direto à resposta desta pergunta, vamos entender como essas filtragens de URL são implementadas (pelo menos em alguns casos). Como comentei anteriormente, eu fui desenvolvedor de software no passado, o que me remeteu ao modo como eu fazia este tipo de validação: eu utilizava um método para verificar qual recurso o usuário queria acessar; e validava, segundo uma lista, se aquele usuário/perfil tinha acesso ou não. Aqui mora o perigo: existem diversas formas (métodos) de se obter o recurso que um usuário deseja acessar. Se não houver um entendimento claro sobre o que esses métodos retornam, o risco de fazer alguma bobagem é grande.
Por exemplo, numa aplicação escrita em JavaScript que utiliza o framework Express, existem, pelo menos, 3 métodos para tal, a saber: originalUrl, path e baseUrl.
Embora pareçam equivalentes, cada um desses métodos possui um comportamento peculiar e foi exatamente aí onde o desenvolvedor da aplicação que eu estava testando errou: ele utilizou o método originalUrl quando deveria ter usado o método path. Como assim? Explico.
Ao utilizar o método originalUrl, o Express irá retornar a URL “completa”, incluindo eventuais parâmetros. É provável que o desenvolvedor, sem conhecer o esse comportamento, tenha assumido que o método retornaria apenas o caminho (path), desconsiderando possíveis parâmetros, o que levou ao erro.
De forma diferente, o método path, retorna apenas o caminho (path) do recurso que está sendo solicitado, o que, provavelmente, era o esperado pelo desenvolvedor para validar se o acesso deveria ser concedido ou não. Simples assim.
O código abaixo é uma inferência (o teste era blackbox) do que o desenvolvedor havia escrito:
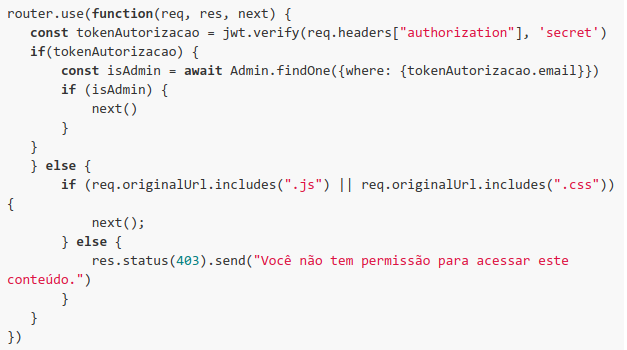
Interessante, não é? Achei massa a vulnerabilidade, mas Jodson questionou: Esse comportamento existe também em outras linguagens de programação? Sendo a resposta afirmativa, será que esta vulnerabilidade (a implementação errada da filtragem) existe em outras aplicações? Pois bem, foi o que investiguei e é o que veremos nos próximos tópicos.
A propósito, como já mencionado inicialmente, por não termos encontrado nenhum nome específico para essa classe de vulnerabilidade, decidimos chamá-la de URL Filter Subversion.
Cavando um pouco mais
De modo a avaliar outras aplicações, comecei a pesquisar quais eram os métodos de outros frameworks/bibliotecas/linguagens de programação relacionados à leitura de URLs. Após entender quais eram os métodos mais utilizados e como eles funcionavam, eu comecei a procurar no Github aplicações que realizassem filtragem de URL de maneira análoga àquela observada durante o pentest supracitado.
Para isso, busquei por códigos que fizessem uma validação de URL com método “inadequado” (originalUrl, por exemplo) seguido de uma validação relativa ao que existe na resposta deste método (endWith, por exemplo). A ideia era verificar a existência de exemplos similares aos que havíamos observado, com o intuito de inferir se esse comportamento era pontual ou se era utilizado em larga escala. Como resultado, para apenas um conjunto de métodos, encontramos aproximadamente 17.000 referências de código com esse comportamento. Inferimos, com isso, que o comportamento existe em larga escala.
Não só encontramos diversos potenciais problemas, como tivemos que restringir o escopo da pesquisa de modo a viabilizar sua conclusão. Desse modo, veremos exemplos de como URL Filter Subversions pode surgir também em Java, Python e GoLang.
Java
O código que vamos avaliar será uma implementação em Java utilizando HttpServletRequest para a leitura da URL. O código abaixo é suscetível à URL Filter Subversion:

Antes de entendermos porque esta implementação está incorreta, vamos entender qual o propósito geral da funcionalidade. Quando o desenvolvedor resolveu implementar esta funcionalidade, ele assumiu a premissa de que as requisições que buscam recursos terminados com .js ou .gif não serão salvas no arquivo de log. Todas as outras serão.
Agora que entendemos qual foi a ideia original do desenvolvedor, iremos apontar onde ele errou e qual o impacto deste erro dentro do contexto da aplicação.
O problema principal nesta funcionalidade é a utilização do método getRequestURL, pois esse método retorna o caminho (path) da URL juntamente com os seus parâmetros, o que faz com que a funcionalidade não consiga validar corretamente o recurso que está sendo buscado.
Então, caso um atacante queira navegar por toda a aplicação sem deixar rastros, bastaria ele adicionar no final de suas requisições um dos valores esperados. A imagem a seguir ilustra o fato:
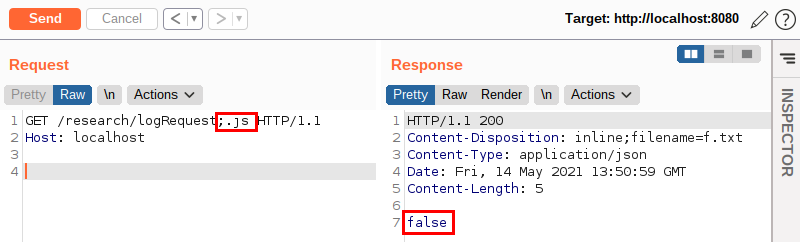
Note que existe uma peculiaridade nesta requisição: para passar um parâmetro na URL, eu utilizei um “;” e não uma “?” como é tradicionalmente usado na maioria das outras linguagens.
A utilização do ponto e vírgula nesta requisição veio, mais uma vez, de um conhecimento prévio: o caractere ponto e vírgula em Java é reconhecido como URL path parameter. Desse modo, para aplicações escritas em Java, a informação .js é apenas um parâmetro e não será entendida como parte do caminho requisitado (path).
Como podemos ver, a funcionalidade devolveu-nos o valor false, ou seja, ela não salvou a nossa requisição no arquivo de log! Curioso, não?
Python
Agora nós vamos analisar um código implementado em Python utilizando o framework Django. O código que será analisado está representado pela figura a seguir:

Essa funcionalidade visa implementar o seguinte comportamento: qualquer requisição que não atenda a um dos requisitos listados abaixo deverá ser salva no arquivo de log.
Requisitos:
- O caminho começa com /adm;
- O caminho começa com /super_adm;
- O caminho termina com .ico.
Mais uma vez, o problema da funcionalidade está na utilização de um método de leitura de URL que retorna não apenas o caminho (path) da URL, mas a URL junto com os parâmetros. Neste caso, o método utilizado foi o get_full_path, que faz com que a funcionalidade não consiga validar corretamente o recurso que está sendo buscado.
Desta forma, para subverter a verificação acima, bastaria adicionar no final da URL um parâmetro contendo o valor .ico. A imagem a seguir ilustra o fato:
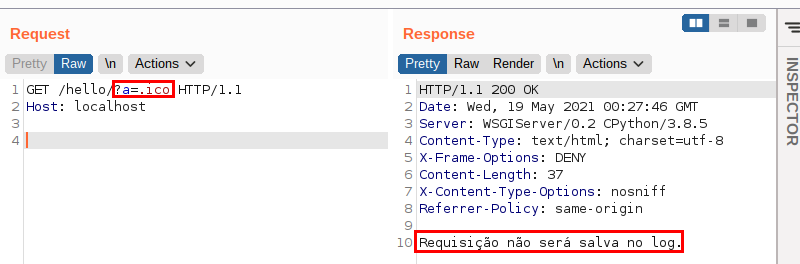
Se você leu o código com um pouco mais de atenção, deve estar se perguntando: por que ele não escolheu enviar a requisição que começasse, por exemplo, com /admin ou /static?
Mais uma vez, esta opção vem de um conhecimento prévio: o Django não aceita que a URL contenha um conjunto de caracteres como ../.
GoLang
Por fim, vamos avaliar um exemplo de má implementação em GoLang utilizando a biblioteca net/http. Segue o código:

Esta funcionalidade tem como objetivo definir se o recurso que está sendo buscado deve ser realizado de maneira não autenticada ou autenticada. Para isso, o desenvolvedor assumiu duas premissas:
- A primeira premissa é de que, caso o recurso que está sendo buscado contenha no início da sua URL os valores /api/public/AGENDA ou /api/public/TAREFAS, a resposta será false e a requisição não será processada;
- A segunda premissa é de que, para a requisição ser processada, a URL deve conter: ou, em seu início, as palavras /home ou /public/; ou, em seu final, .css ou .js.
Logo, para subverter a verificação acima, bastaria para um atacante adicionar ao final da requisição um dos valores esperados. A imagem a seguir ilustra um exemplo deste cenário:
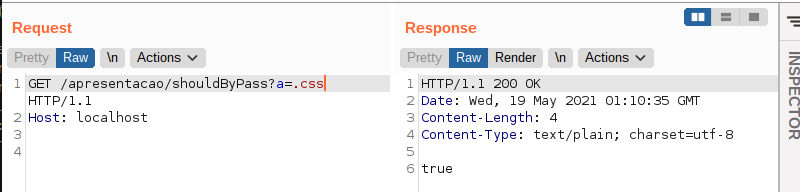
Recomendações
Existem diversos frameworks e bibliotecas, referendadas pela comunidade de segurança, que viabilizam a checagem de URLs. Se possível, prefira a utilização destas bibliotecas em detrimento de implementações “in house”. Todavia, caso seja necessária essa implementação para situações específicas, utilize métodos que retornem apenas o caminho (path) que está sendo requisitado. Essa prática faz com que informações como “querystring” (parâmetros) não sejam consideradas na avaliação da URL.
Conclusão
Como pudemos observar, independentemente de qual seja a linguagem de programação adotada, existem indícios de que engenheiros de software optam por implementar “in house” filtragens baseadas em URL. Existem também indícios de que essa filtragem está sendo realizada muitas vezes de maneira inadequada e em larga escala, o que viabiliza o surgimento de diversos cenários de ataque, mais notadamente a navegação “furtiva” e a subversão do controle de acesso.
[1] Disclaimer: nenhum 0-day será reportado neste blogpost, falhas eventualmente encontradas durante a confecção desta pesquisa foram pontualmente reportadas aos fabricantes.