Por Renato Alpes
Este post é o resultado da última etapa de um ciclo de estágio em consultoria na Tempest: uma pesquisa sobre algum tema relacionado à segurança. Orientado pelo meu research advisor Jodson Leandro e pela minha bússola Nikolaos Eftaxiopoulos, escolhi um tema que se aproximava (pelo menos inicialmente) da área de hardware, com a qual tive mais contato durante a graduação. A pesquisa, eventualmente, tomou um caminho que a distanciou da ideia inicial, mas o importante é que deu tudo certo no final e concluí o primeiro ciclo do estágio com muito mais conhecimento do que quando entrei. Dito isto, vamos para uma breve introdução sobre as tecnologias estudadas nesta pesquisa.
A assistente pessoal de voz Alexa, lançada pela Amazon em 2014, está presente em mais de 100 milhões de dispositivos [1]. Boa parte destes usuários realiza suas interações com a Alexa através de um dispositivo da linha Echo, como o Amazon Echo Dot 3, que foi utilizado para testar os ataques proof-of-concept deste post.
O Echo Dot 3 é um speaker bluetooth pensado especificamente para ser utilizado como interface com a Alexa e tem essa cara:

A feature que é o foco desta pesquisa se chama Alexa Skills e permite que desenvolvedores third-party adicionem funcionalidades customizadas a Alexa de forma parecida com um aplicativo. Antes que um usuário possa utilizar uma Alexa Skill, é necessário que esta seja ativada. Isto pode ser feito manualmente através do companion app que controla o Echo, ou através de um comando de voz. A ativação por comando de voz pode acontecer de duas formas: intencionalmente, isto é, o usuário explicitamente fala em voz alta a frase de ativação especificada pela skill; ou de forma inferida, isto é, o usuário realiza um pedido que a Alexa não consegue atender com suas funcionalidades padrão e a Alexa ativa uma skill que ela considera capaz de completar o pedido.
Com a skill ativada, o usuário pode interagir com ela através do voice model definido pelo desenvolvedor da skill. Este modelo consiste em pelo menos três partes: um Invocation Name, que é o nome utilizado pelo usuário para iniciar a skill; uma ou mais Utterances, que são frases definidas pelo desenvolvedor que serão mapeadas para um Intent; e um ou mais Intents, que são objetos que definem uma intenção do usuário. Certos Intents também podem conter um ou mais Slots, que são informações extras (como um número de telefone ou cor) que serão utilizados no processamento deste Intent.
Com estas definições fora do caminho, é possível detalhar o funcionamento de uma interação do usuário com uma skill qualquer:
- o usuário enuncia uma frase que começa com a wake-up word da Alexa (“Alexa”, por padrão): “Alexa, abra o Spotify e toque Idol por Yoasobi”
- o Echo Dot reconhece a wake-up word, grava até que o usuário pare de falar e envia o resultado para o Alexa Service, nos servidores da Amazon. O arquivo de áudio é então processado por um algoritmo de Automated Speech Recognition, retornando uma transcrição que é enviada para um algoritmo de Natural Language Understanding.
- o NLU reconhece a skill solicitada através do Invocation Name utilizado (neste caso, “Spotify”) e utiliza o voice model previamente definido para ligar a Utterance “toque Idol por Yoasobi” ao Intent “PlaySong”. A definição deste Intent inclui os Slots “Song” e “Artist”, que são preenchidos com “Idol” e “Yoasobi” respectivamente.
- o objeto Intent gerado pelo passo anterior é encapsulado em um JSON que é enviado em uma requisição POST HTTP para o backend especificado pelo desenvolvedor (normalmente uma função lambda da AWS).
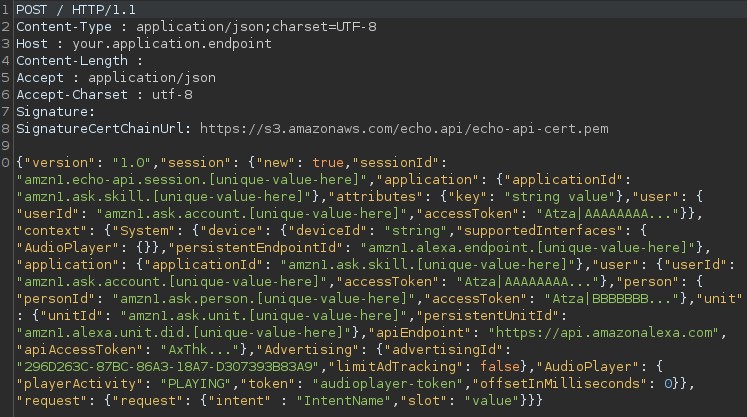
- o backend responde com um JSON que contém o objeto “response”, que é composto de diversos parâmetros que indicam o que o Echo deve responder ao usuário. Neste caso, é utilizada a funcionalidade “outputSpeech”, que vai ler em voz alta um texto do tipo “plainText”.
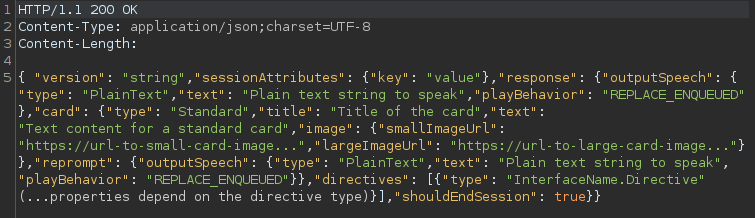
- o Alexa Service envia a resposta que vai ser enunciada ao usuário pelo Echo e o arquivo de áudio que deve ser reproduzido.
- o Echo Dot fala em voz alta “Tocando Idol por Yoasobi” e dá início a reprodução da música.
O processo de desenvolvimento de skills pode ser realizado inteiramente no console do desenvolvedor Alexa, sendo necessário que a skill desenvolvida passe por um processo de certificação antes de ser publicada.
Superfície de ataque
Juntando as observações feitas, podemos criar uma lista de pontos que podem ser controlados por um atacante e de comportamentos nesses pontos que podem ser utilizados para gerar um efeito específico.
Conexão Bluetooth
O modo de pareamento do dispositivo pode ser ativado por voz (“Alexa, bluetooth” já é suficiente) e não pede nenhuma autorização antes de parear, permitindo que um atacante com acesso físico a algum ambiente próximo ao dispositivo se conecte e assuma o controle do speaker. Em um ataque utilizando esta vulnerabilidade, um atacante poderia, por exemplo, gritar “Alexa, bluetooth” através de uma janela aberta e obter controle remoto do speaker para utilizar na exploração de outras vulnerabilidades.
Reconhecimento de comandos de voz
Embora o dispositivo seja capaz de reconhecer se a voz de quem está falando pertence a algum usuário previamente cadastrado, o comportamento padrão permite que qualquer fala registrada pelo dispositivo seja entendida como um comando, incluindo terceiros que nunca foram encontrados pelo dispositivo antes. Além disso, o dispositivo reconhece comandos enviados através de seu próprio speaker como comandos legítimos. Isso permite que um atacante que obteve controle do speaker através de alguma outra vulnerabilidade envie comandos de voz que serão executados pelo dispositivo.
Ativação da skill
O passo de ativação da skill é crucial para qualquer ataque capaz de fazer mais que apenas controlar o speaker. Um atacante interessado em fazer com que um usuário alvo ative uma skill em particular pode usar uma combinação de alguns dos seguintes comportamentos:
- o dispositivo realiza a ativação de qualquer skill cuja frase de ativação foi enunciada, sem confirmar com o usuário que essa realmente era sua intenção. Desta forma, é possível criar uma skill com uma frase de ativação comumente utilizada no cotidiano (Por exemplo: “Bom dia”);
- o Alexa Service realiza a ativação automática de skills que retornem uma resposta com um objeto CanFulfillIntent positivo quando um usuário faz um pedido sem utilizar uma frase de ativação que especifique uma skill em particular. Esse comportamento permite que um atacante crie uma skill que sempre retorna CanFullfillIntent = true, aumentando as chances de que sua skill seja executada automaticamente;
- o ecossistema de desenvolvimento de skills permite que sejam criadas skills com frases de ativação com pronúncia idêntica a de skills já existentes. Além disso, o algoritmo não prioriza skills mais antigas ou que já foram ativadas previamente no momento em que decide qual skill o usuário gostaria de ativar;
- falhas na API da Amazon já permitiram que um atacante ativasse skills arbitrárias, bastando que um usuário clicasse em um link malicioso.
Execução da skill
A execução de uma skill pode ser realizada em um servidor sob completo controle de seus desenvolvedores, de maneira que é impossível garantir que o comportamento da skill não foi modificado depois do processo de publicação e certificação. Além disso, mesmo quando utilizados os serviços de host da Amazon, desenvolvedores podem facilmente contornar o uso das APIs que a Amazon disponibiliza para coleta de informações sensíveis dos usuários (como endereço e telefone), obtendo a informação de forma direta. Por fim, durante os testes realizados, o dispositivo não alertou o usuário de nenhuma forma, mesmo quando a resposta da skill passou mais de nove minutos em silêncio.
Resposta ao usuário
O sistema de envio de respostas ao usuário utilizado permite o envio de respostas arbitrárias, e mais especificamente, permite o envio de respostas vazias (caracteres que geram um longo período de silêncio, como a diretiva <break/>) ou até mesmo de arquivos de áudio arbitrários que serão tocados pelo speaker (uma vulnerabilidade conhecida como full-volume vulnerability permite que áudios enviados sejam reproduzidos em volume máximo). Além disso, um desenvolvedor pode modificar a resposta para Intents comuns como ajuda, parar e cancelar. Um atacante pode utilizar estes comportamentos para fazer com que usuários acreditem que a interação com a skill acabou, quando na verdade a escuta continua ativa, ou para fazer com que usuários acreditem que estão falando com a Alexa, quando na verdade estão interagindo com uma skill.
Ataques
Através de uma combinação dos comportamentos mencionados, podem ser realizados diferentes tipos de ataques com cenários e objetivos diversos.
Bypass da certificação
O flowchart a seguir demonstra um ataque utilizado por pesquisadores para publicar skills com funcionalidade indesejável na loja:
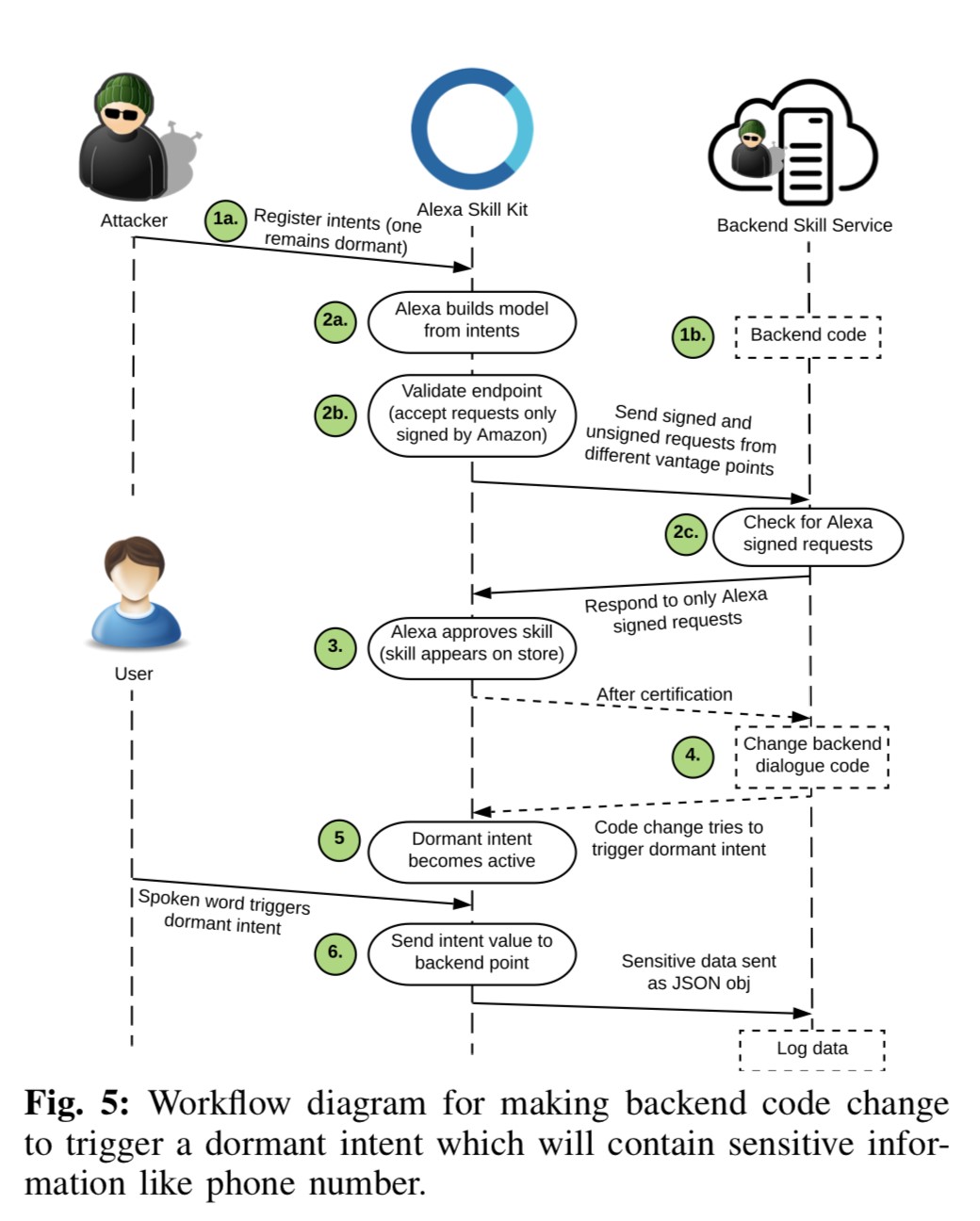
Este bypass é fundamental para conseguir atingir usuários comuns com skills maliciosas.
Skill Squatting
Neste ataque, o atacante utiliza a ativação automática de skills e a possibilidade de utilizar frases de ativação com colisões fonéticas para executar uma skill com funcionalidade arbitrária. O ataque funciona da seguinte maneira:
- usuário ativa a skill de notícias G1 na loja;
- atacante cria um skill com Invocation Name “g. um”;
- atacante publica sua skill na loja;
- usuário enuncia “Alexa, abra o G1”;
- skill do atacante é ativada e executada;
Alexa vs Alexa
Este ataque utiliza a vulnerabilidade que permite que o Echo interprete comandos enviados através do próprio speaker combinada com a full-volume vulnerability para controlar o dispositivo remotamente. A reprodução do arquivo de áudio utilizado para iniciar o ataque pode ser feita através de bluetooth ou de uma skill de rádio maliciosa.
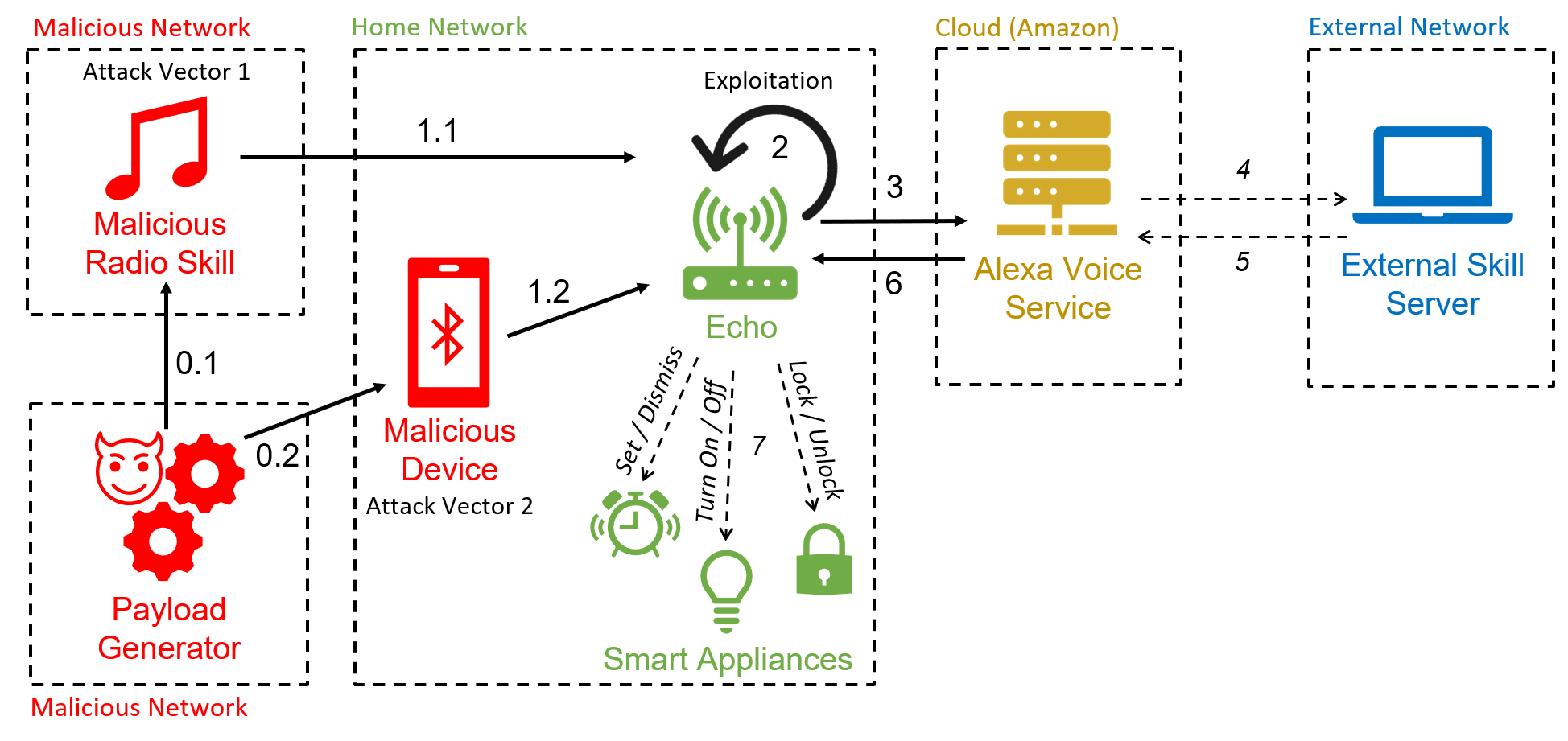
O ataque funciona da seguinte maneira:
- atacante prepara um aúdio malicioso utilizando algum serviço de text-to-speech;
- atacante se conecta no Echo vulnerável através do bluetooth;
- atacante reproduz o áudio no Echo Dot;
- speaker reproduz: “Alexa, turn off [pausa] Alexa, what time is it?”;
- echo reconhece e executa um comando arbitrário.
Os resultados deste ataque permitem que um atacante controle aplicações de smart home, edite calendários da conta, responda e delete e-mails, faça chamadas telefônicas, realize compras na Amazon (utilizando PINs obtidos previamente), invoque outras skills etc.
Mask Attack
Este ataque utiliza o controle que o atacante tem sobre a resposta enviada ao usuário para criar a ilusão de que o usuário alvo está se comunicando com a Alexa, quando na verdade está interagindo com uma skill maliciosa. O ataque funciona da seguinte maneira:
- Skill maliciosa é executada.
- Backend recebe o LaunchIntent.
- Backend responde o Intent com uma quantidade arbitrária da tag SSML break: “<break/><break/><break/><break/><break/>…”
- Skill permanece escutando por toda a duração da resposta.
- Usuário realiza uma interação: “Alexa, como está o clima em Recife?”
- Skill recebe cada palavra como um slot preenchido de InterceptIntent.
- Backend encaminha o pedido para a API da Amazon e retorna a reposta.
- Informação sensível fica armazenada no backend.
As consequências deste ataque incluem a captura de informações sensíveis como senhas, PINs e números de cartão de crédito, bem como ataques de phishing e a captura de informações de uso do Echo.
Bypass da API de informações sensíveis
Técnicas de engenharia social permitem que um desenvolvedor obtenha informações sensíveis sem obter a devida permissão e sem publicar uma política de privacidade para o uso dos dados.
Conclusão
Um atacante suficientemente determinado é capaz de utilizar as técnicas demonstradas neste post para obter controle de um dispositivo Echo Dot qualquer, ou até mesmo de um dispositivo em particular, para obter informações sensíveis ou realizar ações indesejáveis. No entanto, o fluxo dos ataques é complexo e exige interação por parte do usuário em diversos pontos.
Referências
A. Sabir, E. Lafontaine, A. Das (2022). “Hey Alexa, Who Am I Talking to?: Analyzing Users’ Perception and Awareness Regarding Third-party Alexa Skills”
Alexa, Google Home Eavesdropping Hack Not Yet Fixed | Threatpost Acesso em Janeiro de 2023.
[1] Amazon.com Announces Third Quarter Results Acesso em Janeiro de 2023.
Amazon Fixes Alexa Glitch That Could Have Divulged Personal Data | Threatpost Acesso em Janeiro de 2023.
Attackers can force Amazon Echos to hack themselves with self-issued commands | Ars Technica Acesso em Janeiro de 2023.
C. Lentzsch, S. Shah, B. Andow, M. Degeling, A. Das, W. Enck (2021). “Hey Alexa, is this Skill Safe?: Taking a Closer Look at the Alexa Skill Ecosystem”
D. Su, J. Liu, S. Zhu, X. Wang, W. Wang (2020). ““Are you home alone?” “Yes” Disclosing Security and Privacy Vulnerabilities in Alexa Skills”
Documentation Home | Alexa Voice Service Acesso em Janeiro de 2023.
How to Improve Alexa Skill Discovery with Name-Free Interaction and More Acesso em Janeiro de 2023.
HypRank: How Alexa determines what skill can best meet a customer’s need – Amazon Science Acesso em Janeiro de 2023.
K. M. Malik, H. Malik, R. Baumann (2019). “Towards Vulnerability Analysis of Voice-Driven Interfaces and Countermeasures for Replay Attacks”
Keeping the gate locked on your IoT devices: Vulnerabilities found on Amazon’s Alexa – Check Point Research Acesso em Janeiro de 2023.
Researchers Hacked Amazon’s Alexa to Spy On Users, Again | Threatpost Acesso em Janeiro de 2023.
S. Esposito, D. Sgandurra, G. Bella (2022). “Alexa versus Alexa: Controlling Smart Speakers by Self-Issuing Voice Commands”
The Scalable Neural Architecture behind Alexa’s Ability to Select Skills – Amazon Science Acesso em Janeiro de 2023.
Y. Kim, D. Kim, A. Kumar, R. Sarikaya (2018). “Efficient Large-Scale Neural Domain Classification with Personalized Attention”