Por Cust0m
Enumeração de usuários é uma classe de vulnerabilidade que permite a um atacante verificar se um usuário existe ou não em uma determinada aplicação. Existem diversas técnicas que permitem realizar tal distinção e, grosso modo, caso a aplicação se comporte de maneira distinta quando fornecido um usuário cadastrado ou um usuário não cadastrado, diz-se que a aplicação é vulnerável a enumeração de usuários.
Essa classe de vulnerabilidade se encontra de maneira mais comum, como veremos no decorrer deste blogpost, em funcionalidades como “login”, “esqueci minha senha” e “cadastre-se”, o que todavia não exclui outros cenários.
E por que eu deveria me preocupar com isso?
Embora aparentemente inócuo, o comportamento que viabiliza a enumeração de usuários traz consigo uma vantagem para um atacante em ataques como Brute Force e Engenharia Social (e.g. Spear Phishing). Conhecer os usuários válidos em uma aplicação torna o processo de força bruta mais assertivo, visto que parte do desafio login+senha já é conhecido. O mesmo se dá no caso de ataques de Engenharia Social, nos quais um atacante busca comprometer uma (ou um conjunto restrito de) vítima(s) através de uma interação fraudulenta; seja por email, SMS, telefone, instant message, etc. Saber que a potencial vítima possui uma conta em determinado serviço (e qual seria seu login) tende a tornar a engenharia social mais crível.
Além disso, diversas aplicações utilizam dados pessoais como CPF e email como login no processo de autenticação. Esse comportamento aumenta o impacto de uma enumeração de usuários, visto que, em certos contextos, essa informação pode ser considerada sensível, como: a enumeração de CPFs em um private banking, sites de apostas online, de relacionamentos adultos, etc.
Há por fim um outro agravante: a busca por senhas vazadas em leaks públicos (como aqueles vistos nos últimos anos) torna-se bem mais assertiva.
Sabendo que um conjunto de usuários está cadastrado em uma aplicação X, bastaria ao atacante buscar, em bases vazadas, por senhas associadas aos usuários enumerados e testar seu reuso.
E qual é a desse blogpost?
O objetivo desse blogpost é ilustrar como a enumeração de usuários pode ocorrer em aplicações web, desde o exemplo clássico até uns tricks que aprendemos no decorrer dos anos (e claro mostrar como evitar que isso ocorra).
O formulário de autenticação e suas diversas formas de enumeração de usuários
Caso 1 — o exemplo clássico
O exemplo clássico de enumeração de usuários ocorre quando a aplicação exibe duas mensagens distintas no momento do login, a depender de o usuário existir ou não na aplicação. Esse problema ocorre basicamente pela forma que é implementada a função de login, na qual, a depender da existência ou não do usuário, é escolhida uma mensagem em detrimento à outra.
O código abaixo é vulnerável à enumeração de usuários através da distinção entre mensagens de erro, nas quais, caso o login (neste caso o login é o email) fornecido esteja correto e a senha errada, a mensagem de erro “Invalid password” é exibida, e caso o login esteja errado a mensagem exibida é “invalid email”.

E como seria a versão corrigida do código acima? Basta alterar a mensagem de erro para que esta seja a mesma independentemente de o usuário existir ou não. Isso torna impossível para um atacante inferir se um usuário existe na aplicação através desta técnica. Segue o código corrigido para o caso 1:

Ok… é válido o argumento de que praticamente não se vê esse caso em aplicações modernas, a menos que a enumeração de usuários seja pretendida pelo projetista da aplicação para fins de usabilidade. De fato, a materialização deste caso depende de um esforço ativo do desenvolvedor em criar mensagens de erro distintas, o que tende a tornar tal caso cada vez menos comum (embora nós, que trabalhamos como pentesters, vejamos esse erro se repetir de maneira mais recorrente do que muitos imaginam). Segue o barco…
Caso 2 — enumeração baseada em tempo de resposta
Pois bem, mesmo no exemplo corrigido do caso 1, no qual a aplicação, independentemente de o usuário fornecido existir ou não, retorna exatamente a mesma página (e obviamente a mesma mensagem de erro), é possível utilizar um side channel para realizar a enumeração de usuários.
Isso normalmente ocorre pelo fato de a aplicação tomar caminhos diferentes durante sua execução, a depender do usuário fornecido. Caso um desses caminhos tenha um custo computacional consideravelmente mais alto, o tempo de resposta para a requisição de login pode ser também consideravelmente mais alto. O que seria consideravelmente mais alto? O mínimo para que, dentre duas requisições, seja possível diferenciar qual caminho foi tomado. A nossa experiência mostra que um atraso constante de, pelo menos, 30 milissegundos é suficiente para uma enumeração de usuário de forma automatizada.
E é exatamente o que ocorre no caso 1. Se analisarmos com cautela, podemos verificar que a função de hash utilizada só é executada caso o usuário fornecido exista na aplicação (em decorrência do condicional user.exists). Funções de hash utilizadas para armazenar senhas devem ser computacionalmente caras para mitigar ataques de força bruta offline. Portanto, é possível inferir que o tempo de resposta para processar uma requisição, cujo usuário fornecido existe na aplicação, é substancialmente maior do que quando fornecido um usuário que não existe. Com isso, através do tempo de resposta é possível enumerar usuários válidos.
Quem se interessar por uma leitura extra sobre o assunto, recomendo o paper “Time Trial Racing Towards Practical Remote Timing Attacks” de Daniel Mayer e Joel Sandin.
Como exemplo, nós pegamos um caso que encontramos durante um pentest realizado aqui na Tempest (nota: a vulnerabilidade já foi corrigida e os dados foram anonimizados). Repare na imagem abaixo que o tempo de resposta para a requisição, quando submetido um usuário válido, foi de 1211 milissegundos:
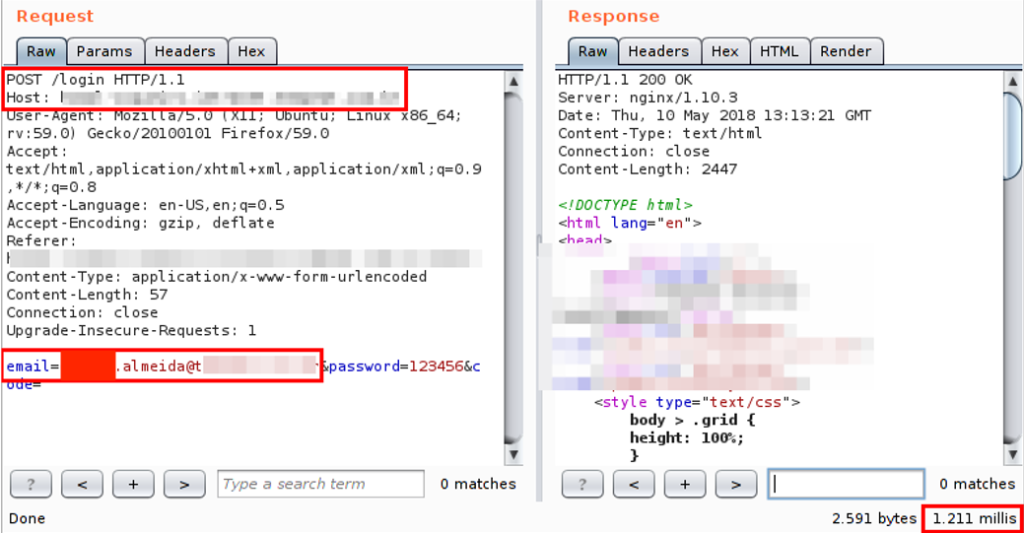
Em contrapartida, quando submetido um usuário não cadastrado, o tempo de resposta foi de apenas 4 milissegundos:
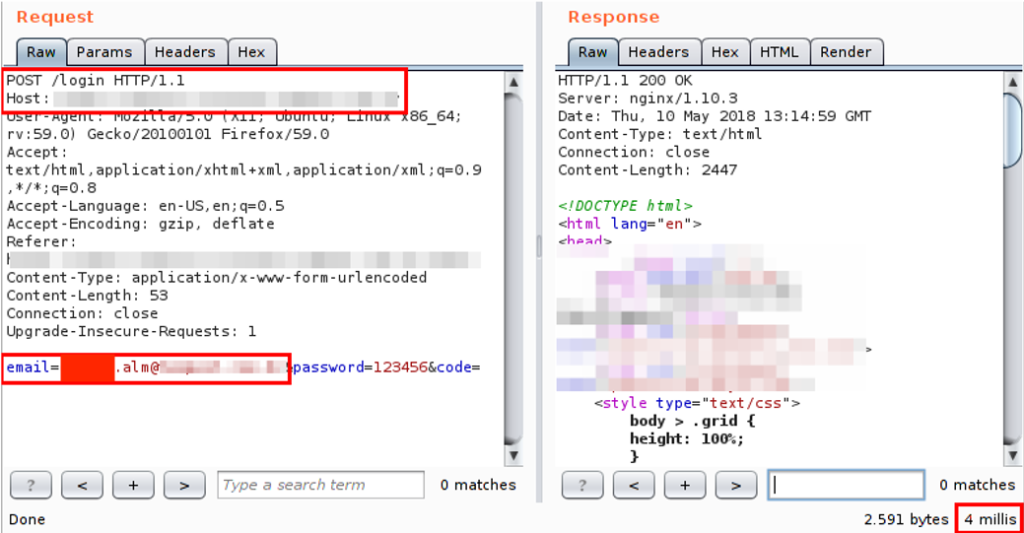
Vale notar ainda que, em ambas as requisições, a aplicação retorna os mesmos 2591 bytes, o que inviabiliza a enumeração de usuários através do caso 1.
“Massa! Mas como resolver o problema no código corrigido do caso 1?” Simples: basta realizar a operação de hash independentemente de o usuário existir ou não na aplicação. Desta forma, o hash sempre será computado e o tempo de resposta será aproximadamente o mesmo independentemente do usuário fornecido. O código ficaria assim:

Diferente do caso 1, eu desconfio que muitos de vocês leitores (especialmente os menos familiarizados com segurança) não conheciam esse tipo de situação.
Protip — É relativamente comum em arquiteturas de microsserviços realizar a autenticação em 2 fases: primeiro checar se o usuário existe e, caso exista, realizar a checagem do login+senha. Dada a latência no consumo dos serviços, esse comportamento quase sempre viabiliza a enumeração de usuários através da técnica descrita acima.
Caso 3 — bloqueio de conta
Voltando à superfície, vamos examinar como uma “medida de segurança” pode acabar sendo utilizada para comprometer a segurança da aplicação.
Provavelmente você já se deparou com um mecanismo de login no qual, ao errar a senha após N tentativas, a conta é bloqueada (às vezes de maneira temporária, outras de forma indeterminada). Um exemplo de como esse mecanismo é implementado pode ser visto no código a seguir:

O que o projetista da aplicação deseja ao bloquear um usuário é evitar que este sofra um ataque de força bruta, o que, convenhamos, é um objetivo nobre. Todavia, ao realizar esse bloqueio da forma descrita acima, alguns efeitos colaterais indesejados surgem: um atacante poderia causar uma negação de serviço contra um usuário (bloqueando propositalmente sua conta), bem como a aplicação poderia permitir a enumeração de usuários cadastrados.
“Massa! O primeiro efeito colateral eu entendi, mas como é que um atacante poderia explorar esse comportamento para enumerar os usuários da aplicação?” Elementar, meu caro leitor:
1 — O atacante escolheria um determinado login que ele supõe existir na aplicação;
2 — Utilizando esse login, ele tentaria se autenticar N + 1 vezes (onde N é a quantidade máxima de tentativas até o bloqueio, o que na maioria dos casos ocorre após 5 tentativas);
3 — Caso a mensagem “User blocked” seja exibida, significa que o usuário existe na aplicação; caso contrário, o usuário não existe.
“Massa! Mas e como corrigir?”
Pois bem, de maneira geral, não se recomenda bloquear usuários após determinada quantidade de logins inválidos, mas esta é uma discussão para outro blogpost (quem sabe outro dia eu escrevo sobre esse tema). Dessa forma, o recomendado para evitar esse tipo de enumeração de usuários seria, simplesmente, não bloquear o usuário.
“Beleza, mas meu chefe disse que eu tenho que bloquear o usuário por questões de ‘segurança’ e não importa o que eu argumente, iaí?” Iaí que, em última instância, o que está viabilizando a enumeração é a mensagem de erro e você não precisa informar para aquele que não conhece a senha do login que a conta está bloqueada. Logo, para inviabilizar a enumeração de usuários no caso 3, simplesmente utilize a mesma mensagem de erro, independentemente de o usuário estar bloqueado ou não. No momento em que o usuário se autenticar com o login e senha corretos, informe que a conta está bloqueada e siga com o procedimento para efetuar o desbloqueio. O código corrigido ficaria assim:

Caso 4 — apresentando o CAPTCHA após N tentativas de autenticação inválidas
Existe uma forma de enumeração de usuários bem parecida com a do caso 3, só que, ao invés de bloquear o usuário, a aplicação exibe um CAPTCHA após N tentativas de autenticação, mas isso ocorre apenas para usuários cadastrados.
O código vulnerável é basicamente o mesmo e as correções permeiam diversas possibilidades. Algumas abordagens são mais sofisticadas, como a utilização de browser fingerprint, outras mais chatinhas de implementar, como a contagem das tentativas de autenticação, mesmo para usuários que não existem na aplicação, e algumas mais conservadoras (sob a perspectiva de segurança) que é sempre exibir o CAPTCHA independentemente de o usuário existir ou não.
Caso 5 — apresente o 2FA!
Este talvez seja o caso menos comum dentre os aqui demonstrados e só ocorre em aplicações que utilizam uma abordagem de múltiplos passos para realizar a autenticação. O exemplo mais comum é quando a aplicação, após receber um login válido, solicita que o usuário apresente o segundo fator de autenticação. Caso o usuário forneça um login inválido, a aplicação exibe uma mensagem de erro qualquer. Trivial seria imaginar como realizar a enumeração de usuários nesse caso. Como seria mais ou menos um código vulnerável?

E a correção? Bem, a correção para esse cenário também é trivial: ou você solicita o segundo fator de autenticação apenas após o fornecimento da senha correta, ou solicita login, senha e segundo fator em uma mesma tela.
Caso 6 — senhas gigantes
Tás cansado, leitor? Eu também, mas o fim se aproxima, esse é o último caso de enumeração de usuários no mecanismo de autenticação. 🙂
Além de ser o último exemplo, esse é o mais raro e mais bizarro. Pra ser honesto, eu só vi isso umas 2 ou 3 vezes na vida… Mas eu sempre testo, vai que aparece a quarta, né verdade?
E como seria esse cenário? É simples! Alguns frameworks e funções de hash (muitas feitas in house) não conseguem processar senhas com tamanhos grandes. Por grande aqui entenda algo maior que 10000 bytes. O que normalmente ocorre é que, ao submeter um usuário válido e uma senha grande, a aplicação tenta processar essa senha e eventualmente “crasha”, resultando em um erro 500. Na prática a resposta 500 serve como side channel para identificar se o usuário fornecido existe ou não na aplicação.
Segue o questionamento: e para corrigir? Há algumas abordagens, umas bacanas e outras meio gambiarrescas. O ideal seria não utilizar funções de hash que não consigam tratar dados de tamanho arbitrário. Mas, no mundo real, onde é preciso matar um leão por dia, você pode simplesmente usar a correção do caso 2, computando sempre o hash independentemente de o usuário existir ou não. O efeito colateral seria que sua aplicação sempre retornaria um erro 500, mas dada a situação, “te abraça” com a solução e seja feliz. Uma última opção seria simplesmente “fatiar” a senha de modo que ela respeite os limites da função de hash. A aplicação teria uma limitação quanto ao tamanho da senha, o que, a depender da entropia desta, não seria um problema.
Além do formulário de autenticação
Caso 7 — esqueci minha senha (a.k.a. reset de senha) e cadastre-se
Ainda que até aqui tenhamos exposto 6 formas diferentes de enumerar usuários através do formulário de login, é importante notar que estas vulnerabilidades não se limitam a ele. Outras funcionalidades nas quais, historicamente, encontramos diversas enumerações de usuário são o mecanismo de “esqueci minha senha” e o “cadastre-se”.
De forma análoga ao que ocorre no caso 1, é bastante comum encontrarmos mecanismos de “recuperação de senha” que exibem mensagens de erro, caso o usuário informado para a recuperação não exista no sistema. Os mecanismos de cadastro, por sua vez, fazem o oposto, exibindo uma mensagem de erro caso o usuário já esteja cadastrado.
A correção da vulnerabilidade no reset de senha é óbvia: independentemente do login fornecido, a mensagem apresentada deve ser sempre a mesma, algo como “um link de reset de senha foi enviado para o endereço de email cadastrado”. Além disso, é importante que a exibição desta mensagem seja feita antes do envio do email de reset, caso contrário, abre-se novamente uma possibilidade de enumeração de usuários, por exemplo, a partir do tempo necessário para o envio do email (vai que o tempo de resposta do servidor SMTP é muito grande… já imaginou né!?).
A correção do “cadastre-se”, por sua vez, já não é tão óbvia e exige um custo um pouco maior de implementação, além de possuir uma restrição: faz-se necessário ter como login (username) da aplicação um endereço de email ou número de telefone.
A solução consiste em, durante o preenchimento do formulário de cadastre-se, fornecer um meio de comunicação, como endereço de email ou número de telefone. Uma vez conhecido o meio de comunicação, deve ser enviado um link de uso único e aleatório que, ao ser clicado, exiba um formulário com os dados cadastrais a serem preenchidos. Caso o usuário forneça um email ou telefone previamente cadastrado, a aplicação deve enviar uma mensagem para este email/telefone alertando sobre a nova tentativa de cadastro. Chatinho né verdade? Faz parte.
Conclusão
Se você chegou até aqui, deve ter notado o quão difícil é evitar uma enumeração de usuários. Quaisquer pequenos desvios podem gerar um side channel e acabar “vazando” os usuários cadastrados. Claro que, para diversas aplicações, ter uma enumeração de usuários não é lá grande problema, algumas aplicações até assumem isso como um requisito de usabilidade e não há motivos para pânico.
Todavia, caso sua aplicação não esteja dentro desse grupo e exija um nível de segurança mais alto, sugiro que não negligencie essa possibilidade. A composição de vulnerabilidades de baixo impacto pode gerar uma dor de cabeça grande e desnecessária.
Por fim, além das recomendações citadas em cada um dos casos, é válido lembrar que não custa muito utilizar CAPTCHAs em formulários de login, reset de senha e funções de cadastro. Além de evitar a automatização de ataques de força bruta, inviabiliza a enumeração de usuários em massa.
Espero que faça bom uso da leitura.