Por Antonio Silva
Introdução
Hoje em dia é muito comum querermos ter a visibilidade dos ativos de tecnologia ou endpoints de uma rede, especialmente quando existe uma preocupação com a segurança e com o seu respectivo monitoramento. Isso acontece por conta da importância que uma visão em tempo real pode proporcionar para equipes de segurança defensiva de uma empresa. O grande problema é que nem sempre encontramos ferramentas de baixo custo que supram essa necessidade.
Felizmente, em meados de 2014, o Facebook lançou uma ferramenta de código aberto chamada Osquery que possibilita suprir essa necessidade, podendo ser utilizada para o monitoramento de anomalias de segurança, checagem compliance e políticas de segurança, análise de performance ou até mesmo na resposta e análise de um incidente de segurança.
O Osquery é uma ferramenta que permite monitorar o sistema operacional e vários de seus atributos e configurações de uma maneira diferente. Basicamente, ele possibilita entender sobre um determinado sistema operacional que está rodando e o que está acontecendo numa máquina. Tudo isso acontece através de consultas SQL, de forma similar ao que é feito quando um Banco de Dados é consultado. Esse comportamento abre um leque gigantesco de possibilidades de consultas que podem retornar informações valiosas sobre o estado do sistema. Com ele é possível, por exemplo, monitorar a integridade de arquivos, conexões de sockets, processos em execução e muito mais.
No Osquery as tabelas correspondem a um determinado conjunto de dados que representam componentes e estados do SO com os respectivos atributos dos objetos que os representam. A seguir, vemos uma consulta referente à tabela “logged_in_users”, que representa usuários ‘logados’ no sistema operacional.

No exemplo demonstrado acima, é possível observar o resultado de uma simples consulta que fornece detalhes dos usuários ‘logados’ no sistema operacional em questão. E isso é apenas a ponta do iceberg do que o Osquery possibilita fazer como ferramenta de monitoramento e detecção de anomalias. Agora talvez fique mais fácil perceber o potencial da ferramenta, e o que podemos tentar gerar com os insumos dos resultados. Esses podem ser utilizados minimamente para enriquecimento dos logs em um SIEM e para a construção de casos de uso. Se ainda não tiver muito claro, vamos aprofundar sobre essas possibilidades nos tópicos de monitoramento e detecção de anomalias.
Visibilidade e Monitoramento
Como já comentado no início deste artigo, um problema comum nas organizações é a baixa visibilidade de seus endpoints. Devido a isso, algumas equipes não sabem exatamente quais endpoints compõem seu ambiente, nem mesmo a configuração física de cada um deles, quais programas estão em execução, ou se as atualizações do sistema operacional estão em dia. O Osquery pode fornecer uma visão bem clara, garantindo o estado dos endpoints bem como se estão funcionando adequadamente.
A capacidade de visibilidade é fundamental não só para o monitoramento, mas também para a tomada de decisão quando algo está fora dos trilhos. Além disso, a visibilidade permitirá entender melhor o ambiente para responder a perguntas como:
- Os endpoints com Sistema Operacional Windows possuem quais KB’s instalados?
- Qual o usuário logado no momento?
- Quais processos estão em execução?
- Qual configuração de hardware o endpoint possui?
Embora o Osquery traga a visibilidade necessária dos endpoints, para que possa auxiliar as equipes de Segurança da informação ou TI, e possa fornecer um mecanismo robusto de consulta para expor informações, normalmente isso não é o suficiente para que seja usado em um monitoramento adequado. O fato é que o Osquery não fornece um servidor ou mesmo uma GUI (acrônimo do inglês Graphical User Interface), uma interface gráfica que facilite o gerenciamento. Nesse ponto, FleetDM, antigo Kolide, ajudará no gerenciamento da visibilidade e do monitoramento.
O FleetDM facilita o gerenciamento de enpoints com Osquery possibilitando e fornecendo de maneira centralizada:
- Visão total dos endpoints que possuem o Osquery instalado;
- Centralização dos logs de consulta;
- Agendamento de consultas;
- Packs de consulta para monitoramento contínuo.
A seguir uma tela do FleetDM com sua interface demonstrando detalhes iniciais interessantes a respeito dos endpoints:
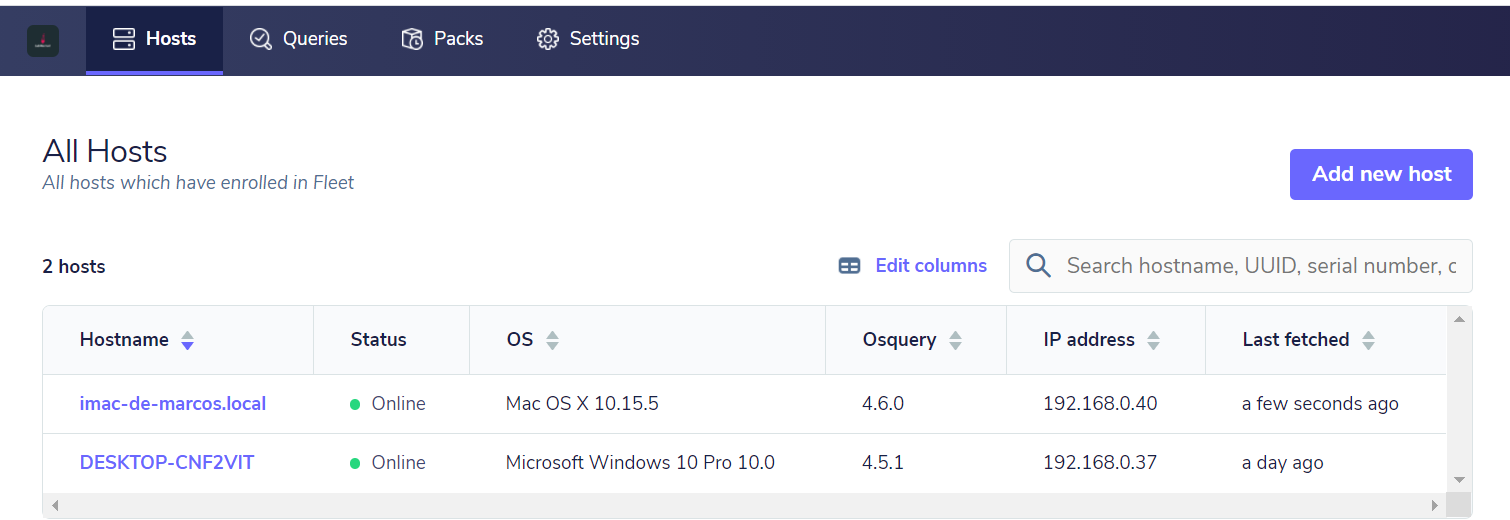
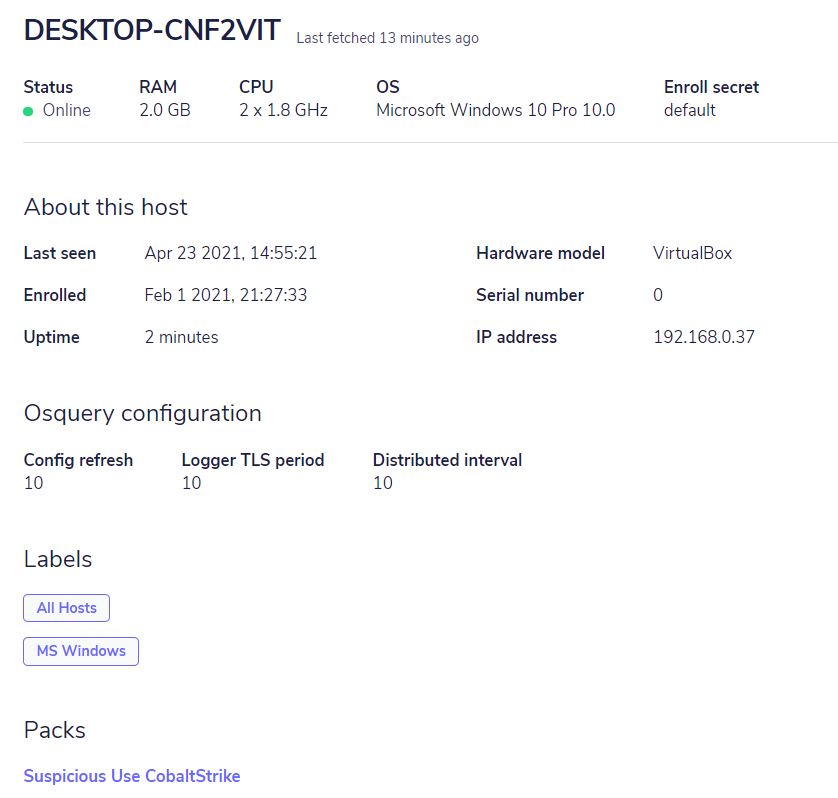
Com a centralização do gerenciamento, podemos ter um monitoramento eficiente para centenas de endpoints, através das consultas realizadas ao Osquery. Atualmente, o Osquery conta com 273 tabelas (e isso muda e aumenta o tempo todo), que em combinação com as consultas poderão responder a inúmeras questões sobre o ambiente, de modo que, através do FleetDM, poderá manter um monitoramento contínuo através de consultas agendadas. O detalhamento das tabelas do Osquery pode ser consultado em sua página oficial.
Como o monitoramento está intrinsecamente ligado à visibilidade do ambiente, é importante que tenhamos em mente boas perguntas para que as respostas sejam as mais adequadas. Iniciamos com: “O que está com problema?”. Para que então seja possível ter a resposta mais adequada do “Por quê?”. Sendo assim, o monitoramento será baseado em um possível sintoma ou comportamento específico que queremos monitorar, para acompanhar possíveis mudanças de estado ou comportamento dos ambientes.
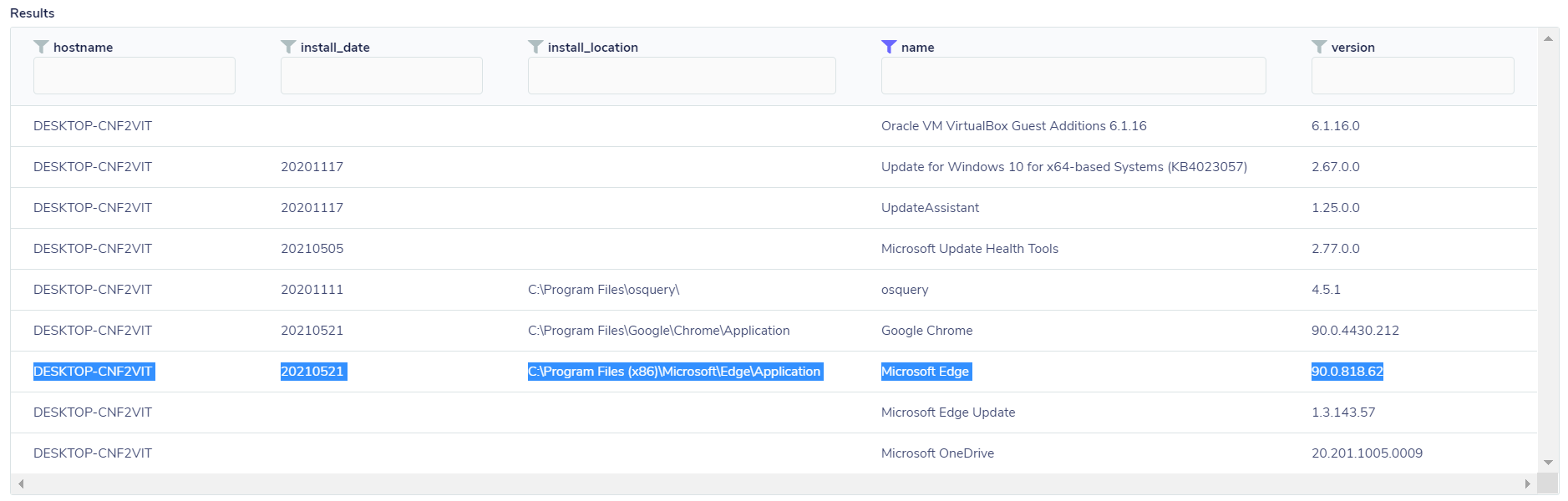
Nesse ponto, o FleetDM pode nos ajudar, pois ele trabalha com duas diferentes formas de consulta: uma delas é aquilo que você deseja visualizar no atual momento, e é chamada de Live query/Distributed query, que é basicamente uma consulta “ao vivo” do estado naquele exato instante. Imagine que você queira saber se houve um novo programa instalado recentemente, em um ou mais endpoints, para tal, basta realizar uma consulta distribuída ao vivo através da tabela “programs”, que listará todos os programas instalados, para que se possa verificar, através das datas, qual foi recentemente instalado, como no exemplo abaixo:
SELECT install_date, install_location,name,version FROM programs
Por outro lado, se você deseja se concentrar em algum tipo de problema ou comportamento mais específico, é possível realizar uma pesquisa programada. Caso você queira monitorar alterações de estado ou desvios de comportamento, desejando sobretudo que sejam produzidos logs para serem enviados a um SIEM, no intuito de enriquecer o monitoramento do SOC, o FleetDM possui packs que são coleções de consultas. Um detalhe é que não precisa haver, necessariamente, mais de uma consulta para ser um pack.
Um bom exemplo disso seria monitorar os processos e as informações de um endpoint, juntamente com o hash de seus respectivos executáveis, para enviar essas informações ao SIEM, com base no processo e no hash. Assim, seria possível correlacionar esses dados com algum banco de feeds para verificar se o hash pertence a alguma ameaça já conhecida.
Mas, antes de ter o pack propriamente dito, é necessário fazer uma consulta de teste para verificar se a mesma está correta e se trará as informações necessárias e suficientes. No exemplo a seguir, serão usadas três tabelas: process para monitorar os processos em execução, users para monitorar os usuários que estão executando os respectivos processos, e por último a tabela hash que trará as informações de hash em md5. Para essa consulta, é necessário um JOIN, que terá a função de consolidar as informações em uma única saída:
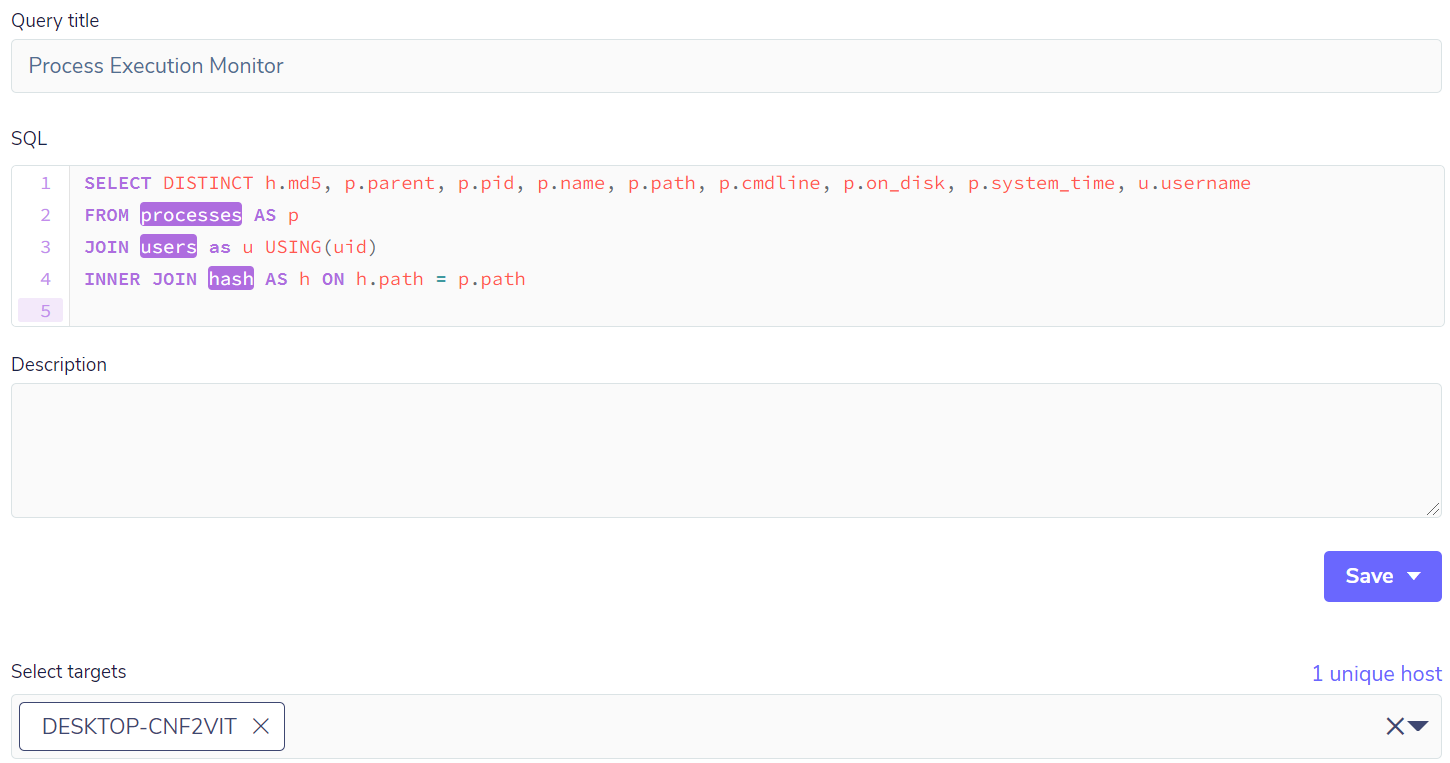
O resultado trará todos os processos em execução naquele instante. Para não tornar o exemplo muito grande, vamos pegar apenas um processo para verificar se todos os campos estão corretos, e se a consulta possui insumos para a criação de um pack:


A consulta trouxe dados relevantes de processo, usuário, e hash, entre outros, e agora é possível ter um pack para monitorar os processos. Esse pack poderá, futuramente, possuir mais consultas que sejam relevantes, de forma que este pack possa vir a ser uma coletânea de consultas relacionadas a processos.
A configuração do pack como consulta programada é algo simples e requer poucos passos. Os mais importantes são: definir quais serão os alvos, o intervalo de execução, o sistema operacional, e o tipo de log – os quais podem ser diferenciais ou snapshots. No modo snapshot, o pack sempre trará as informações, independente de ter havido ou não uma mudança de estado.
No modo diferencial, o pack trará apenas as alterações de estado desde a consulta anterior. Caso não haja nenhuma alteração, não haverá o registro de logs. Na configuração, ainda é possível definir se você quer dados de todo o ambiente ou somente uma amostra, definida por porcentagem através do campo shard.
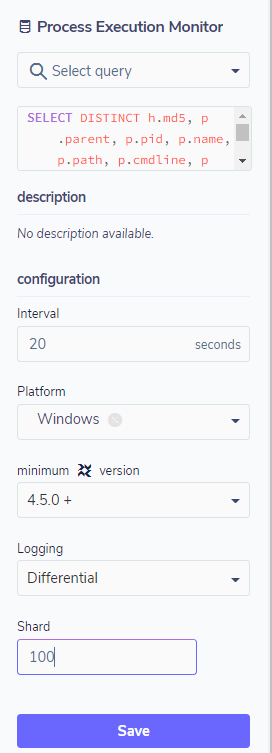
Com o pack criado, e o intervalo de tempo de execução definido, o FleetDM irá requisitar a consulta ao Osquery, e salvará o resultado dessa consulta em um local definido na instalação e configuração do FleetDM em formato JSON, que pode ser exportado para algum SIEM através do syslog ou logstash, abaixo um exemplo deste resultado:

Outro bom exemplo de monitoramento, para apoio às equipes, é o monitoramento dos patches de atualizações. Eles podem ser úteis para verificar se os endpoints possuem alguma vulnerabilidade passível de correção via patch, mas que ainda não tenha sido aplicada.
Partindo do ponto mais simples, para esse tipo de monitoramento, a tabela que será utilizada é patches. Com essa tabela, é possível verificar todas as instalações de atualizações, até mesmo as atualizações de segurança. Abaixo uma simples consulta demonstrará todas atualizações de um determinado host:
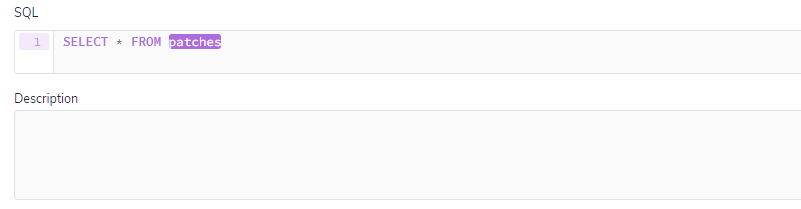
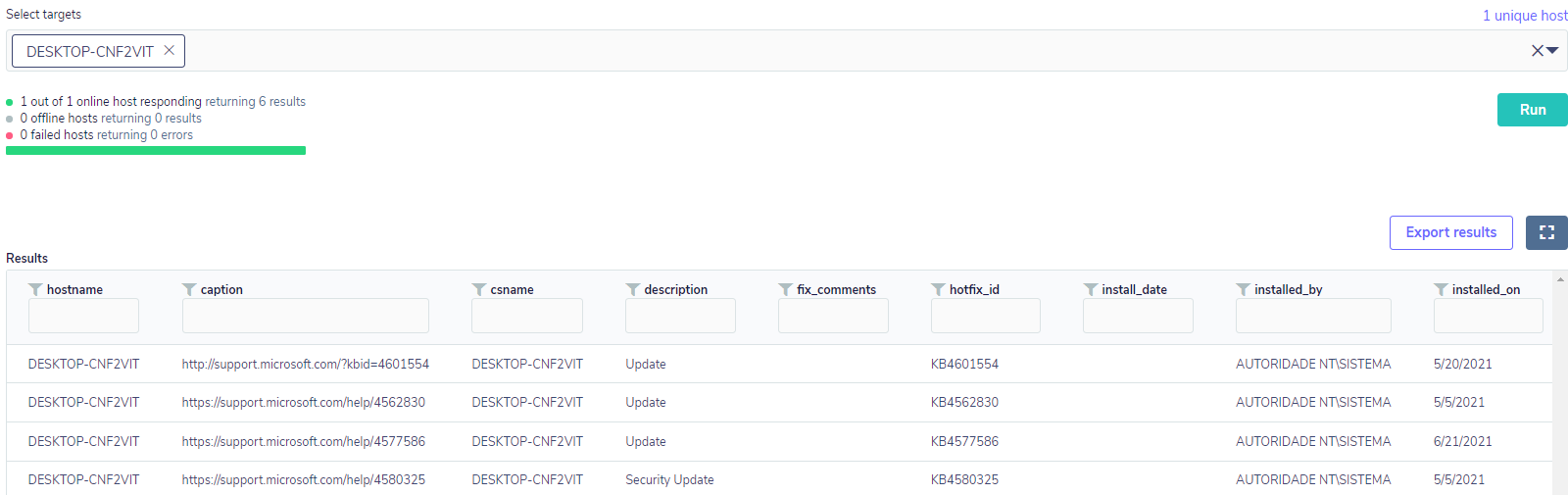
Com base nesses dados, é possível montar uma consulta mais complexa para procurar por patches específicos referentes a alguma vulnerabilidade crítica, como por exemplo a CVE-2020-0601, que permitia a um ator de ameaça assinar um executável malicioso.
Neste caso, para montar um pack para monitorar se um endpoint está ou não vulnerável, precisaríamos ao menos saber quais KB’s corrigem a vulnerabilidade do CVE. Neste caso, os KB’s que corrigem a vulnerabilidade são os seguintes:
‘KB4534306’
‘KB4534271’
‘KB4534276’
‘KB4534293’
‘KB4534273’
‘KB4535550’
‘KB4528760’
Com essa informação, o pack irá rodar, em um intervalo de tempo específico, uma consulta para buscar quais endpoints não possuem o patch instalado; descobrindo também se a build do sistema operacional é a build afetada. Além disso, no caso do patch já ter sido instalado, a consulta também verificará se o endpoint foi reiniciado após a instalação do patch, para que o patch tenha sido devidamente aplicado no sistema operacional.
Abaixo está a query na íntegra – a mesma não é de minha autoria e possui artigo no blog oficial da kolide com um detalhamento muito maior de sua construção:
WITH
split_date AS
(SELECT *,
SPLIT(installed_on, '/', 2) AS year,
SPLIT(installed_on, '/', 0) AS month,
SPLIT(installed_on, '/', 1) AS day
FROM patches),
date_reconstructed AS
(SELECT *,
year
|| '-' ||
SUBSTR(('0' || month), -2)
|| '-' ||
SUBSTR(('0' || day), -2)
|| ' ' ||
'00:00:01' AS install_date_utc
FROM split_date),
restart_check AS
(SELECT *,
CASE
WHEN
(SELECT
datetime(
time.local_time - uptime.total_seconds, 'unixepoch')
FROM time, uptime) > install_date_utc
THEN 'true'
ELSE 'false'
END AS restart_since_install
FROM date_reconstructed),
operating_system AS (
SELECT
CAST(SPLIT (version, '.', 0) AS integer) AS major,
CAST(SPLIT (version, '.', 2) AS integer) AS build,
CAST(SPLIT (version, '.', 3) AS integer) AS patch
FROM kernel_info),
vulnerable_build AS (
SELECT *,
CASE
WHEN major = 10 AND build = 10240 AND patch < 18453 THEN 'true'
WHEN major = 10 AND build = 14393 AND patch < 3443 THEN 'true'
WHEN major = 10 AND build = 16299 AND patch < 1625 THEN 'true'
WHEN major = 10 AND build = 17134 AND patch < 1246 THEN 'true'
WHEN major = 10 AND build = 17763 AND patch < 973 THEN 'true'
WHEN major = 10 AND build = 18362 AND patch < 592 THEN 'true'
WHEN major = 10 AND build = 18363 AND patch < 592 THEN 'true'
ELSE 'false'
END as affected_build
FROM operating_system),
failing_state AS
(SELECT CASE WHEN (SELECT 1
FROM restart_check
WHERE hotfix_id IN (
'KB4534306',
'KB4534271',
'KB4534276',
'KB4534293',
'KB4534273',
'KB4535550',
'KB4528760'))
THEN 'true'
ELSE 'false'
END AS CVE_2020_0601_patch_installed,
CASE WHEN (SELECT 1
FROM restart_check
WHERE hotfix_id IN (
'KB4534306',
'KB4534271',
'KB4534276',
'KB4534293',
'KB4534273',
'KB4535550',
'KB4528760')
AND restart_since_install = 'false')
THEN 'false'
END AS restart_since_install,
CASE WHEN (SELECT 1
FROM vulnerable_build
WHERE affected_build = 'true')
THEN 'true'
END AS affected_build)
SELECT *,
CASE WHEN (restart_since_install = 'false'
OR cve_2020_0601_patch_installed = 'false')
AND affected_build = 'true'
THEN 'true'
END AS vulnerable
FROM failing_state
WHERE vulnerable = 'true'
Com a execução da query, havendo algum endpoint que satisfaça as premissas da query mencionadas anteriormente, o resultado será parecido com o seguinte:

Caso não exista nenhum endpoint vulnerável, nenhum resultado será mostrado. Assim, as equipes poderão atuar com mais assertividade na correção de uma vulnerabilidade crítica existente em seu ambiente, mesmo não possuindo uma ferramenta de gestão de vulnerabilidade específica.
Detecção de anomalias
As ameaças vêm evoluindo constantemente, e boa parte dos atacantes costuma fazer suas investidas, em especial, contra os endpoints pela possibilidade de ser o meio “mais vulnerável” em uma organização. Tendo em vista que os mesmos são mantidos por usuários comuns, os quais quase sempre não reconhecem quando algo está errado ou existe alguma anomalia de comportamento em andamento, o uso aliado do FleetDM junto ao Osquery torna possível a detecção de algumas anomalias de maneira interessante. Para isso basta criar consultas e packs que possam detectar anomalias que se deseja detectar de forma proativa visando uma ação imediata. Apesar de já termos feito alguns processos de consulta e packs anteriormente, vamos ilustrar algo mais próximo de como funciona uma engenharia de detecção de uma anomalia nas partes que estão por vir. Você verá que o maior esforço não está em escrever as querys em si, mas sim em saber qual a query deve ser feita e o que deve ser retornado como resultado de forma a proporcionar a detecção dos comportamentos maliciosos de forma precisa. Cabe ressaltar que mesmo o FleetDM e Osquery sendo poderosos e tendo o seu funcionamento de modo similar a um Endpoint Detection and Response (EDR), o processo de respostas não são automatizadas como em geral ocorre em um EDR propriamente dito.
Impedindo a troca de senha dos usuários
Aqui vamos simular um caso hipotético de uma anomalia de um um ataque bem-sucedido, onde o atacante busca manter persistência no ambiente afetado. Para isso, é comum a criação de Golden Tickets e Silver Tickets. O Kerberos utiliza tokens de autenticação ou tickets para validar identidades do AD, e isso inclui usuários que possuem uma senha no Active Directory.
Quando o atacante tem acesso ao endpoint, ele vai tentar extrair a hash da conta de serviço, para assim, através de uma ferramenta como o “Kerbeoast” quebrar a senha e, posteriormente, poder gerar um Silver Ticket falso. Isso pode permitir que serviços façam login sem verificar novamente se o token é válido ou não, podendo inclusive permitir que o atacante escale privilégios.
Os Silver Tickets falsos são muito difíceis de serem detectados, pois os registros são locais, não havendo uma comunicação entre o serviço e o controlador de domínio. Com base nisso, o intuito de detecção de anomalia não seria detectar o Silver Ticket em si, mas sim um comportamento que indique seu uso.
Após todo esse processo, o atacante sabe que se houver uma alteração de senha da conta, o Silver Ticket perderá a validade. E é aqui que podemos monitorar uma anomalia: geralmente os administradores implementam políticas para trocas recorrentes de senha nos endpoints. Entretanto, os atacantes, sabendo disso, e já possuindo uma elevação de privilégio, podem, através do registro do Windows, impedir a troca de senha.
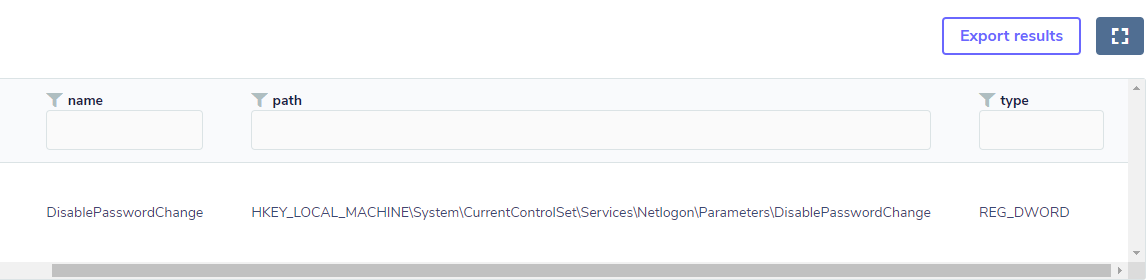
A chave que controla esse aspecto é:
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\Netlogon\Parameters\DisablePasswordChange
O atacante altera seu valor para 1 impedindo que a troca de senha ocorra, assim ele ganha persistência, visto que seu Silver Ticket ainda será válido. Ou seja, a alteração do valor da chave é o ponto de anomalia que estávamos procurando, mesmo sem saber necessariamente se houve um Silver ticket, havendo um forte indicativo como este, deve-se considerar esse ponto de anomalia inicial para a realização de uma investigação mais apurada.
Vamos ver na prática como seria o monitoramento dessa anomalia. Primeiramente, é preciso criar um pack com uma consulta simples que irá monitorar a alteração de estado da chave da seguinte forma:

Caso o valor da chave seja alterado do padrão, cujo valor é 0, a consulta retornará um resultado como este:
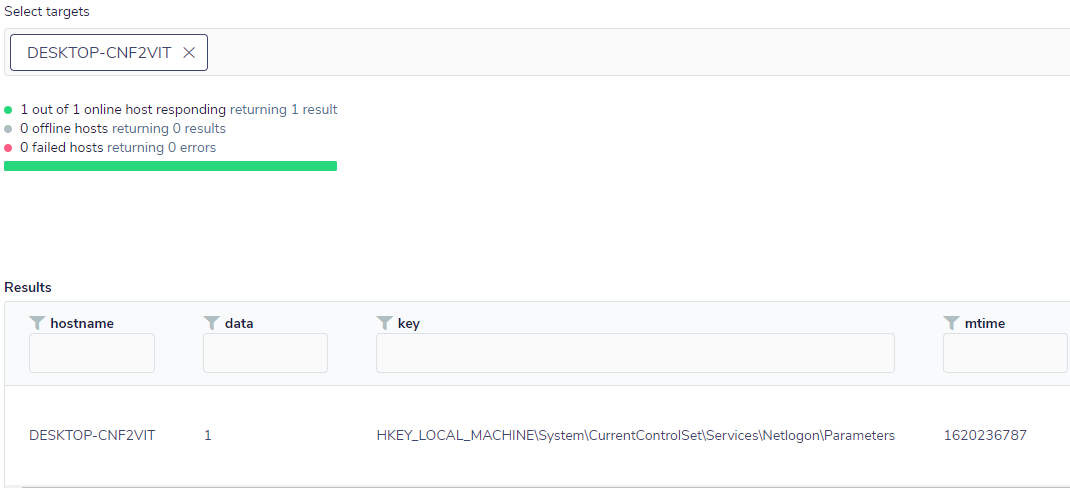
A alteração do valor padrão da chave vai na contramão de um ambiente onde exista uma política de alteração de senhas, sendo portanto um indicativo de que algo possivelmente não está normal. Entretanto, somente isso não indica com certeza se houve a criação ou uso de um Silver Ticket falso, por isso, trata-se de uma anomalia que carece de outros elementos para ser comprovada. Todavia, neste aspecto, o FleetDM juntamente com o Osquery podem dar a visibilidade a um SIEM de uma maneira simples; além disso, outras consultas referentes a este tema podem ser agregadas ao pack, para aumentar o nível de detecção com maior assertividade.
Conta local administrativa
Como visto antes, aqui teremos mais um caso para ilustrar uma forma de persistência, algo que é bem perigoso em uma pós exploração, onde os atacantes costumam criar contas locais, geralmente com privilégio administrativo, para que possam realizar outras ações maliciosas no ambiente já comprometido.
O Windows possui grupos de identificadores exclusivos para entidades ou grupos, e esses valores únicos podem identificar a qual grupo um usuário pertence. No caso, o SID do Windows possui um identificador relativo, que são os três últimos numerais do SID. Segundo a documentação oficial da Microsoft sobre os identificadores relativos ao valor 544, este número representa que o usuário tem privilégios administrativos.
Com base nisso, podemos criar um pack para detectar uma anomalia de criação de conta local com privilégios administrativos. Todavia, também sabemos que em um ambiente corporativo podem ocorrer adições ocasionais de usuários com privilégios administrativos, por isso, é importante que sejam validados através de uma lista no SIEM.
A consulta do pack pode ser inicialmente como essa:
select s.hostname,users.uid,users.gid,users.username,users.directory, user_groups.gid from users JOIN user_groups ON users.uid=user_groups.uid,system_info s where user_groups.gid=544
Em testes, tínhamos apenas o usuário local administrador conforme consulta abaixo:
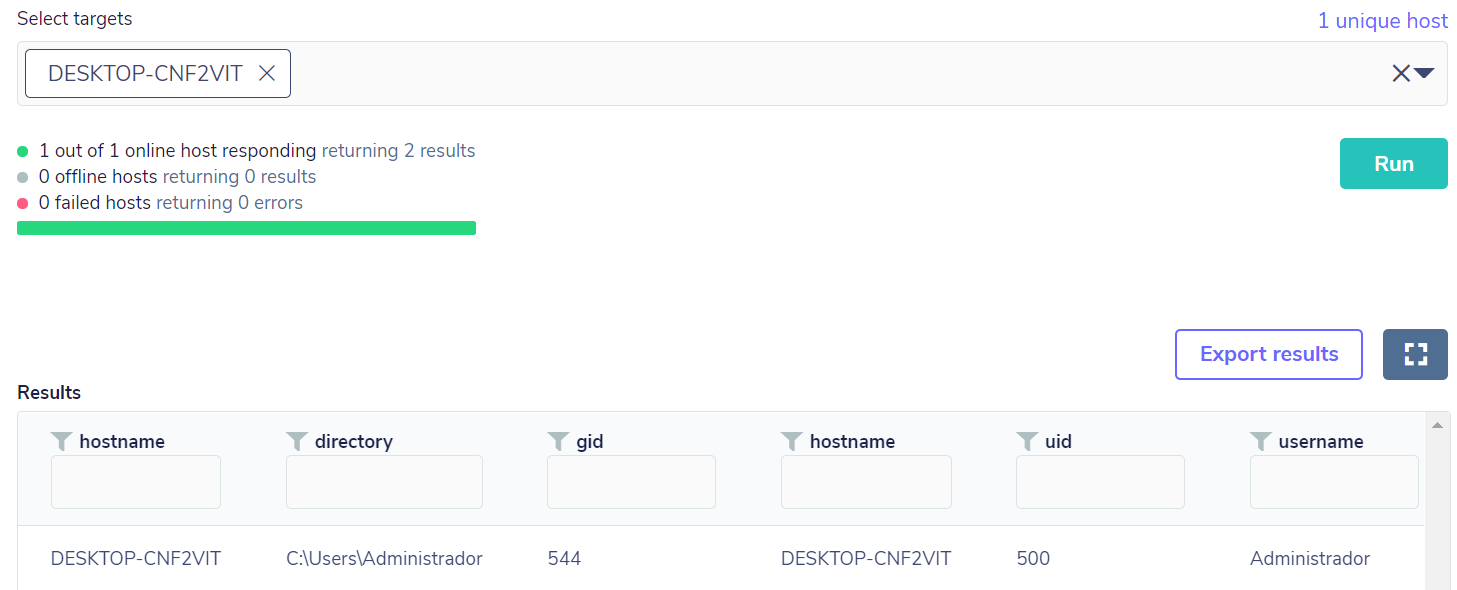
Em seguida, foi realizada uma adição de conta local, com privilégios administrativos, de modo que a consulta retornou o resultado como esperado, com base no campo “gid” com valor 544:
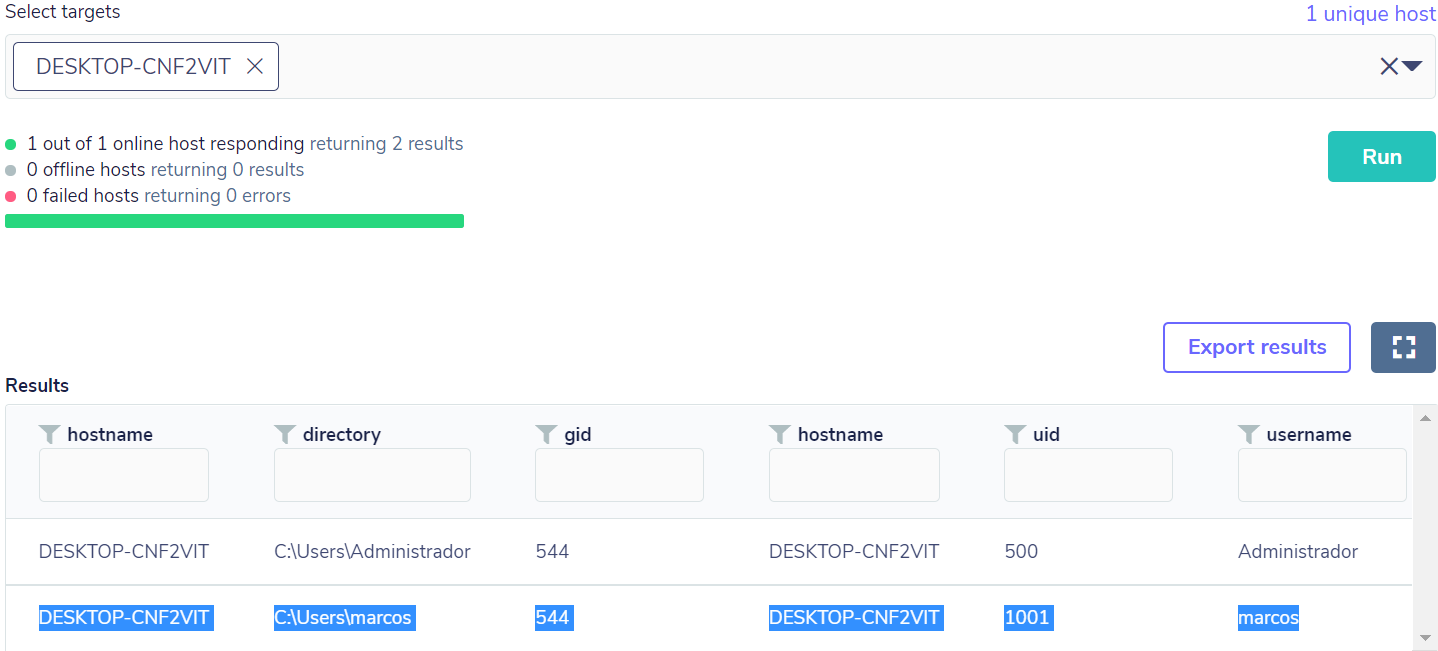
Após essa detecção de anomalia, é possível fazer uma correlação com outras atividades a fim de determinar uma atividade potencialmente maliciosa.
Persistência, chave de execução (RunOnceEX)
Outro tipo de anomalia relacionada à persistência, é a criação de chaves no registro no sistema operacional, chaves estas que podem ser utilizadas para executar uma carga arbitrária ou uma dll maliciosa.
Em meados de 2018, Oddvar Moe descobriu um local do registro do Windows que poderia permitir a execução de uma dll ao realizar o logon. Está tudo documentado com detalhes em seu blog “ODDVAR MOE’S BLOG”. Todavia, esse tipo de ação requer privilégios administrativos, mas que provavelmente o atacante poderia conseguir de outras formas, como demonstrado nos tópicos anteriores.
A chave que Oddvar descobriu seria essa:
HKLM\SOFTWARE\Microsoft\Windows\CurrentVersion\RunOnceEx\0001\Depend /v 1 /d "C:\temp\messageBox64[.]dll"
Uma vez que o atacante estivesse em poder do endpoint comprometido, o mesmo poderia adicionar a chave ao registro conforme exemplo abaixo:

Tendo em vista que este é um tipo de anomalia ainda mais séria que as demonstradas anteriormente, e requer, portanto, maior atenção, podemos montar um pack com uma consulta que verificará a existência e o estado dessa chave, juntamente com o seu valor. Assim, o campo data possivelmente fará referência a algum executável ou DLL.

Caso a chave exista, e a mesma possua algum valor atribuído, haverá um resultado similar como o demonstrado abaixo:

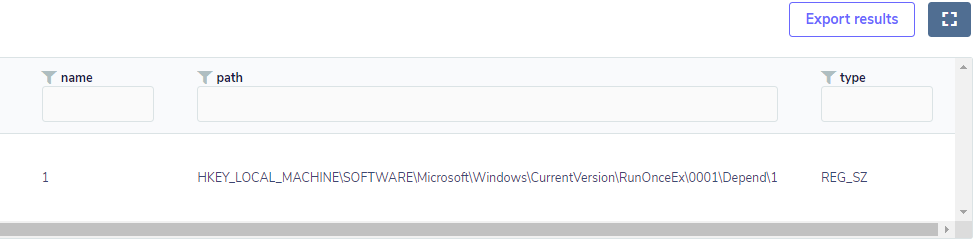
Isso servirá como pontapé inicial para uma investigação aprofundada no endpoint, pois demonstra que possivelmente houve uma exploração.
Considerações Finais
Como vimos, visibilidade e monitoramento são dois pontos importantes, visados por muitas organizações. Por isso mesmo, com uma ferramenta simples e Open Source é possível sair à frente dos atacantes: já que só é possível monitorar e detectar aquilo que se vê.
Além disso, uma ferramenta que dê tamanha liberdade de pesquisa é de muito interesse. Porém, é importante entender as ameaças e certos problemas que se deseja observar, pois somente dessa forma faz-se boas consultas para obter resultados proveitosos, de modo a poder correlacionar esses resultados com outras fontes em seu SIEM, e assim poder ser mais proativo nas mitigações.
A ideia aqui foi apresentar e demonstrar maneiras para uma melhor utilização do FleedDM associado ao Osquery, e assim demonstrar que a utilização dessas ferramentas podem ser utilizadas como ponta pé inicial para ganho de visibilidade e monitoração.
Para saber mais sobre o projeto FleetDM, consulte sua página oficial no github, onde são mantidas as versões e a documentação de implementação da ferramenta.
Referências
[1] Stuifbergen, Joshua. IBM. Monitorando ambientes conteinerizados com osquery. Disponível em: https://developer.ibm.com/br/technologies/systems/articles/monitoring-containers-osquery/ . Acessado em: 04/Out/2021.
[2] Facebook Engeneering. Introducing osquery. Disponível em: https://engineering.fb.com/2014/10/29/security/introducing-osquery/. Acessado em: 05/Out/2021.
[3] Metcalf, Sean. Active Directory Security. Disponível em: https://adsecurity.org/?p=2011. Acessado em: 06/Out/2021.
[4] Microsoft. Security identifiers. https://docs.microsoft.com/en-us/windows/security/identity-protection/access-control/security-identifiers . Acessado em: 05/Out/2021
[5] Mitre Att&ck. Create Account: Local Account. Disponível em: https://attack.mitre.org/techniques/T1136/001/ . Acessado em: 11/Out/2021.
[6] Oddvar Moe’s Blog. Persistence using RunOnceEx – Hidden from Autoruns.exe. Disponível em:
https://oddvar.moe/2018/03/21/persistence-using-runonceex-hidden-from-autoruns-exe/
Acessado em: 08/Out/2021.
[7] Kolide. Using Kolide + osquery to find and fix critical Windows Crypto Vulnerability. Disponível em: https://blog.kolide.com/using-kolide-osquery-to-find-and-fix-critical-windows-crypto-vulnerability-b6c05e33a9cf . Acessado em: 11/Out/2021.
[8] Osquery. Schema. Disponível em: https://www.osquery.io/schema . Acessahttps://blog.kolide.com/using-kolide-osquery-to-find-and-fix-critical-windows-crypto-vulnerability-b6c05e33a9cfdo em: 12/Out/2021.
[9] Mitre Att&ck. Boot or Logon Autostart Execution: Registry Run Keys / Startup Folder. Disponível em: https://attack.mitre.org/techniques/T1547/001/ . Acessado em: 13/Outu/2021.