I would like to start this post with a brief introduction. I’m an intern at Tempest Consulting, where we develop offensive security projects. Previously, I worked as a software engineer, developing mobile applications in a startup located here, in Recife.
Professor Marcelo Araújo influenced my interest in migrating from software engineering to offensive security. He was the one who introduced me to information security and was also a guide in choosing my major in Information Systems, which I am currently attending at the Federal Rural University of Pernambuco. So, thanks, Marcelo!
A quick look at URL-based filtering
In this blog post, we will verify how flaws related to URL-based validation of conditions can lead to security problems. We evaluate examples in 4 programming languages: JavaScript, Java, Python, and GoLang. [1] We will also learn how to prevent these flaws from happening. Since we couldn’t find a specific terminology for this type of problem, we decided to generically call them URL Filter Subversion for didactic purposes.
Where did the idea come from?
During one of the pentests I had the opportunity to participate as a shadow, I found an application that had anomalous behavior.
The problem was in the list users feature, which should only be accessed by the administrator user profile. The request looked like this:
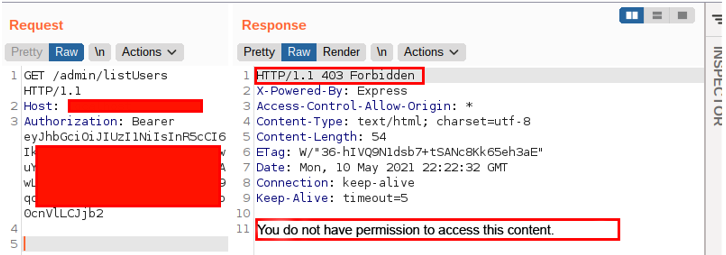
However, trying a few different payloads to build the URL, I encountered the following behavior: by entering an arbitrary parameter followed by the term js, the application allowed me to access the user listing functionality. That’s right, even though I am not an administrative user, the application performed the supposedly restricted action. The following image illustrates the behavior:
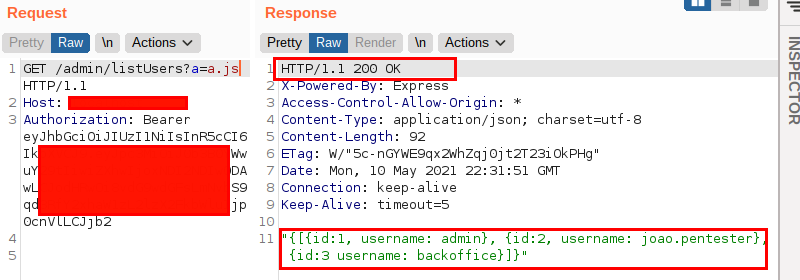
I was absolutely puzzled by the scenario and decided to consult my colleagues. This is how I found out that another analyst, Jodson Leandro, had already encountered the same issue and was developing this research. Very kindly, he explained what it was about and oriented me to write this blog post. Thanks, Jod!
But after all, what was making this behavior possible in the application? That is what we will see in the following topics.
How do developers validate URLs to allow access to particular resources?
Before getting straight to the answer to this question, let’s understand how this URL filtering is implemented (at least in some cases). As I commented before, I was a software developer in the past, which reminded me of how I did this kind of validation: I used a method to check which resource the user wanted to access; and then validated, according to a list, whether that user/profile had access or not. Here lies the danger: there are several ways (methods) to get the resource that a user wants to access. If there is no clear understanding of what these methods return, the risk of doing something foolish is great.
For example, in an application written in JavaScript using the Express framework, there are at least three methods: originalUrl, path, and baseUrl.
Although they seem equivalent, each of these methods has a peculiar behavior. This is precisely where the developer of the application I was testing made a mistake: he used the originalUrl method when he should have used the path method. How so? Let me explain.
When using the originalUrl method, the Express will return the “complete” URL, including eventual parameters. It is likely that the developer, not knowing this behavior, assumed that the method would return only the path, disregarding possible parameters, which led to the error.
On the other hand, the path method returns only the path of the resource being requested, which was probably expected by the developer to validate whether access should be granted or not. It is as simple as that.
The code below is an inference (the test was blackbox) of what the developer had written:
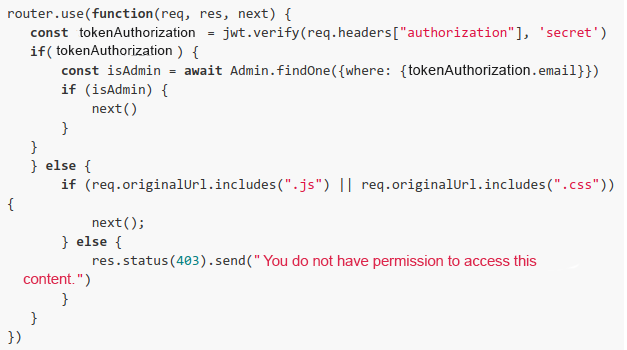
Interesting, isn’t it? I thought the vulnerability was cool, but Jodson asked: Does this behavior exist in other programming languages as well? If so, does this vulnerability (the wrong implementation of filtering) exist in other applications? Well, this is what I have investigated and what we will see in the next topics.
By the way, as mentioned initially, as we couldn’t find any specific name for this kind of vulnerability, we decided to call it URL Filter Subversion.
Digging A Little Deeper
In order to evaluate other applications, I started researching which methods of other frameworks/libraries/programming languages were related to reading URLs. After understanding which techniques were the most used and how they worked, I started to search on Github for applications that perform URL filtering in a manner analogous to the one observed during the pentest mentioned above.
To do so, I searched for code that validated a URL with an “inappropriate” method (originalUrl, for example) followed by a validation concerning what exists in the response of this method (endsWith, for example). The idea was to check for examples similar to the ones we had observed to infer if this behavior was punctual or if it was used on a large scale. As a result, we found approximately 17,000 code references with this behavior for just one set of methods. We infer from this that the behavior exists on a large scale.
Not only did we find several potential problems, but we had to restrict the scope of the research in order to be able to complete it. This way, we will see examples of how URL Filter Subversions can also appear in Java, Python, and GoLang.
Java
The code we will evaluate is a Java implementation using HttpServletRequest to read the URL. The code below is susceptible to the URL Filter Subversion:
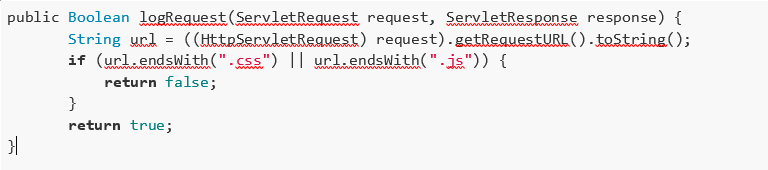
Before we learn why this implementation is incorrect, let’s understand the general purpose of the feature. When the developer decided to implement this feature, he assumed that requests looking for resources ending with .js or .gif would not be saved in the log file. All other requests will be.
Now that we understand what the developer’s original idea was, we will point out where he went wrong and the impact of this error within the context of the application.
The main problem with this feature is the use of the getRequestURL method. This method returns the URL path along with its parameters, making the feature unable to properly validate the resource fetched.
So, if an attacker wants to browse through the whole application without leaving any traces, he would simply add one of the expected values at the end of his requests. The following image illustrates this:
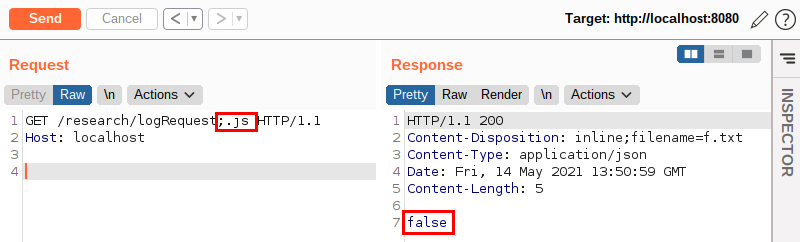
Notice that there is a peculiarity in this request: to pass a parameter in the URL, I used a “;” and not a “?” as it is traditionally used in most other languages when using HTTP protocol.
The use of the semicolon in this request came, again, from prior knowledge: the semicolon character in Java is recognized as a URL path parameter. Thus, for applications written in Java, the .js information is just a parameter and will not be understood as part of the requested path.
As we can see, the feature returned the false value, meaning that it did not save our request in the log file! Curious, isn’t it?
Python
Now we are going to analyze a code implemented in Python using the Django framework. The following image represents the code that will be analyzed:
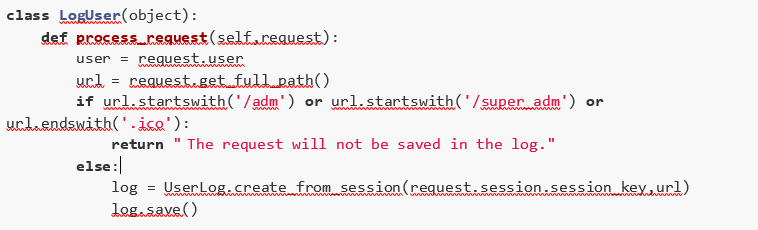
This functionality aims to implement the following behavior: any request that doesn’t meet one of the requirements listed below should be saved in the log file.
Requirements:
- The path starts with /adm;
- The path starts with /super_adm;
- The path ends with .ico.
Once again, the problem with the feature lies in using a URL reading method that returns not just the URL path but also the URL along with parameters. In this case, the method used was get_full_path, which causes the feature to fail to properly validate the resource being fetched.
So, to subvert the above verification, it would be enough to add a parameter containing the .ico value at the end of the URL. The following image illustrates this:
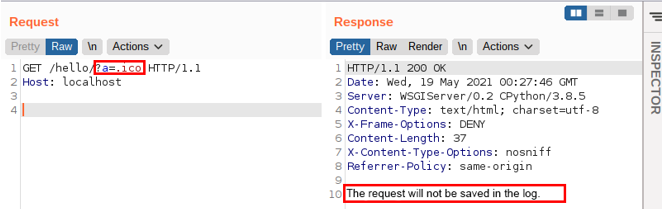
If you read the code a little more carefully, you might be wondering: why didn’t he choose to send the request that started with, for example, /admin or /static?
Again, this choice comes from prior knowledge: Django doesn’t accept an URL containing a set of characters like ../.
GoLang
Finally, let’s evaluate an example of a bad implementation in GoLang using the net/http library. Here is the code:

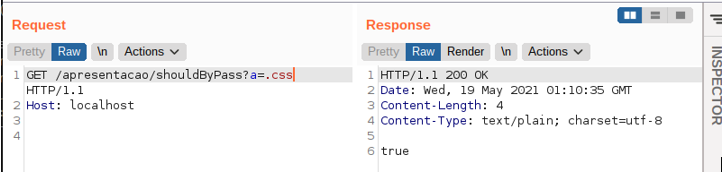
This functionality aims to define whether the resource being searched for should be done unauthenticated or authenticated. To do so, the developer made two assumptions:
- The first assumption is that if the resource being fetched contains at the beginning of its URL the values /api/public/CALENDAR or /api/public/TASKS, the response will be false, and the request will not be processed;
- The second assumption is that for the request to be processed, the URL must contain: either, at its beginning, the words /home or /public/; or, at its end, .css or .js.
So, to subvert the above check, an attacker would simply add one of the expected values to the end of the request. The following image illustrates an example of this scenario:
Recommendations
There are several frameworks and libraries endorsed by the security community, which enable URL checking. If possible, use these libraries instead of “in-house” implementations. However, if you need this implementation for specific situations, use methods that return only the path that is being requested. This practice prevents querystring information from being considered when evaluating the URL.
Conclusion
As we have seen, regardless of which programming language is used, there is evidence that software engineers choose to implement “in-house” URL-based filtering. There is also evidence that this filtering is often performed inadequately and on a large scale, enabling a variety of attack scenarios to emerge most notably “stealth” browsing and access control subversion.
[1] Disclaimer: no 0-day will be reported in this blogpost, flaws eventually encountered during the creation of this survey were occasionally reported to the manufacturers.