Por Eduardo Müller
There is an illusory sense of security, which believes in the use of a firewall, or another resource accessible only by the internal network, as being sufficient to protect against external attacks. For those who already have some knowledge in the area of cybersecurity, our title is already enlightening. However, our goal is precisely to present and explain, for those who are not familiar, a type of vulnerability that should get rid of this false sense of security.
Server Side Request Forgery, also known as SSRF, is a vulnerability that allows an attacker to make requests through a vulnerable server. Their targets can be external or internal networks. It is also possible to communicate with services of other protocols, which means that the attacker is able to induce the vulnerable application server to carry out requests in an arbitrary manner.
The image below shows the main idea of an SSRF attack:
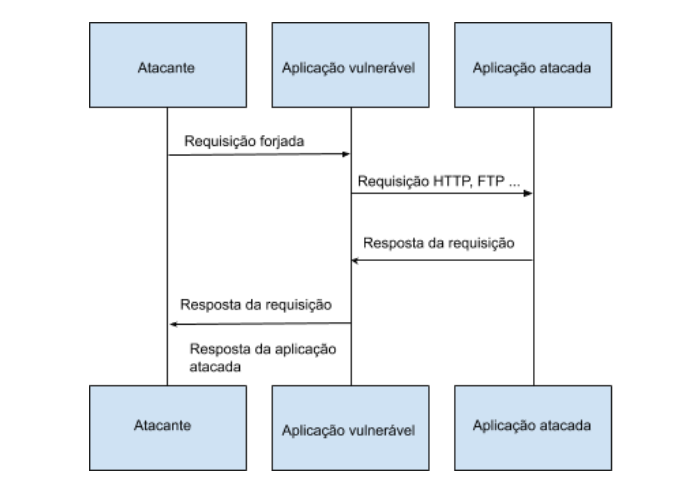
It is worth mentioning that the SSRF technique is not limited only to the HTTP protocol, it can be used by different types of protocols, such as FTP, SMB, SMTP, etc. The use of different schemes is also feasible in SSRF, such as, data://, file://, etc. Therefore, both the use of the protocol and the scheme will depend exclusively on the requirements of the application.
To better exemplify what we are saying, let’s assume that the application to be tested is a blog. In this imaginary blog, users can publish, as well as, comment, like and share publications by other users. Specifically, in the functionality of posting a publication, it is possible to upload an image file or upload an image using a URL. When the second resource is utilized — upload an image using a URL — the application makes the following request:

An eventual attacker, upon seeing this request, will try to change the value of the load_picture parameter, in order to make a request to a server under his control. The amended request will take the following form:

The attacker expects the application to make a request to your server. If this happens, it is very likely that it may be vulnerable to SSRF attacks; since it was possible to forge an HTTP request to a specific server through the blog application in an arbitrary way.
SSRF types
SSRF can be presented in two ways, Basic or Blind.
Basic is the most obvious to detect and to be explored, since it is the case where the application displays the content of the response: it can be either an error message, a json or even another webpage.
In Blind, the application does not display the response content. However, this does not mean that you are not vulnerable to SSRF. What happens is that the exploration process will be different. Thus, we’ll have to pay attention to the response time of the request and the HTTP response codes, to look for some logic or pattern that helps us to understand the operation of the application. Only then, it will be possible to exploit the vulnerability in cases of Blind SSRF.
Accessing Internal Files
Returning to our example of sending photos to the blog, when we saw that it was possible to load an external object into the application, we asked: What would happen if the server did not distinguish between external and internal objects? Would it be possible to access internal files? Yes, that’s right: The Server Side Request Forgery technique makes it possible to access internal files through fuzzing. With this method, the attacker can check for files of your interest to gain access to them. Thus, it would be necessary to make the following request to gain access to a possible passwd file:

Scanning Ports
Once the firewall has been bypassed, by making requests to the internal network, based on the response time of the requests, you can scan the ports to find out which ones are open or closed. For example, the following request has an HTTP 200 response code (OK):

As a result of the port change, this other request has an HTTP 500 response code (Internal Server Error):

Thus, it can be deduced that door 20 is open, while door 25 is closed.
Enumerating Services
When scanning ports, it is also possible to enumerate services by obtaining their respective versions. With this information in hand, attacks aimed at specific services can be developed, thus increasing the chances of success. By using public exploits, this technique makes an eventual attack against a specific service (with the specific version) more efficient.
The following request illustrates an example of obtaining the version of a service used:

And this way we discovered version 6.7 of the OpenSSH service through the response:
Attacking Internal Applications
It is common in the business environment to use internal applications, which are accessed only through the internal network, or at least they should be, as they are part of the company’s intranet. Unfortunately, it is also common for such applications to have a low level of security when compared to external applications. This is because, due to the fact that they are on the intranet, they bring a false and illusory sense of security, which has been with them since the development phase. For this reason, using an SSRF, it is possible to carry out attacks on such applications.
For this vulnerable scenario, let’s assume that there is an administrative interface accessible through http://localhost/admin. Like most internal applications, it also has several other vulnerabilities, which allow the following request to be executed in an unauthenticated manner:

This way, it becomes possible to remove a user from an internal application in an unauthenticated way through a vulnerability in an external application, bypassing firewall rules. With these few examples, we believe it has already been possible to attest to the danger of SSRF attacks. So, let’s see what can be done to minimize the risks.
Mitigating SSRF
In general, there are two cases in which an SSRF can happen:
1. The application only sends requests to other trusted applications (this method is very close to an Allow-List);
2. The application allows sending requests to any external IP or domain.
In the first case, it is possible to think of a scenario where this situation occurs. As an example, imagine a first application that needs to make a request for a second, located on another network, in order to search for some type of information. The first measure to be considered is input validations. In this scenario, the application will expect to receive a certain set of information about the URL to be requested. This information would be: IP address; domain name; URL and any specific string that needs to be in the request. Let’s see, quickly, how to make the first three information safer:
IP address
It must be ensured that valid values of IPV4 or IPV6 addresses are being entered; in addition, the provided IP must be identified as trusted by the application. The IP address must be confirmed with an allow-list of IPs whose permission to communicate with the internal application is duly validated.
Domain name
It is possible to perform a DNS resolution to verify the existence of a domain. It is necessary to have a validation of the domain to know if it is a valid, reliable and identified by the application. As with the IP address, it is necessary to make an allow-list with all the domain names to be identified. We emphasize that, even with all of this, you have to be careful when performing this type of check, as the application may still be vulnerable to DNS pinning. Therefore, it is important to ensure that domains are part of your organization and are resolved internally by internal DNS servers. In addition, the list of valid domains must be monitored in order to detect when one of these resolves to a local IP.
URL
It is not recommended to use full URLs coming from the user, because validating and parsing URLs becomes more complicated.
When the application allows requests to be sent to any external IP or domain, this second case occurs when a user can control an external URL and the vulnerable application makes the request for that URL. As there is no type of control in this second case, allow-lists are not considered, since there is no list of IPs or domains that validate this input. This is the worst case to defend, making blocking dynamic URLs at the application layer a challenging task.
Safety Recommendations
To be brief, here are some security recommendations, in line with our goal of contributing to a more secure digital world:
● Perform validation and filtering of the data received by the user;
● Disable unused URL schemes, such as ftp://, sftp:// and http://;
● Use an allow-list with the necessary IPs for the application to work.
References
- https://portswigger.net/web-security/ssrf
- https://www.hackerone.com/blog-How-To-Server-Side-Request-Forgery-SSRF
- https://www.netsparker.com/blog/web-security/server-side-request-forgery-vulnerability-ssrf/
- https://medium.com/swlh/intro-to-ssrf-beb35857771f
- https://medium.com/@vickieli/exploiting-ssrfs-b3a29dd7437
- https://medium.com/@madrobot/ssrf-server-side-request-forgery-types-and-ways-to-exploit-it-part-1-29d034c27978
- https://medium.com/@madrobot/ssrf-server-side-request-forgery-types-and-ways-to-exploit-it-part-2-a085ec4332c0
- https://medium.com/@gupta.bless/exploiting-ssrf-for-admin-access-31c30457cc44