By Magnon Souza
We live in an age of data explosion, it’s estimated that by 2020 we created about 1.7 MB every second. This equates to 2.5 quintillion bytes of data per day (a quintillion is the equivalent of no less than 18 zeros). This surreal volume of information has made many people question the security and privacy of their data, stirring the discussion about personally identifiable data capable of directly or indirectly recognizing an individual.
In this scenario was born the General Data Protection Regulation (GDPR) in Europe, the General Law of Data Protection (LGPD) in Brazil, and several other laws and regulations around the world. Along with these regulations emerges the need for companies to handle this type of data properly. For this procedure to be done properly, it’s important that the organization pays attention to factors such as: the nature and type of data that the organization intends to anonymize, risk management by the company when imposing control tools for protection, and the usefulness of these anonymized databases.
But what does data anonymization mean?
Anonymized data is basically information that has had its identifiable links removed. This can be the result of a process of breaking the link between the owner and the raw information. This process is called data anonymization or impersonation of data.
From raw data, one or more anonymization techniques are applied and the risk of re-identification is checked. Was the risk very low? If yes, we classify the data as anonymized. If not, we continue to apply different anonymization techniques and restart the check.
It’s worth pointing out that, according to the specialized literature, anonymization that guarantees 100% effectiveness is nothing but a myth or a theoretical idealization. Any anonymized data runs the inherent risk of being converted back into personal data. Does this mean that anonymization should be put on the back burner or seen as a low priority activity? Never! The reality is that as new anonymization techniques emerge, new tactics to circumvent impersonation processes are developed. Whether they are: new algorithms, greater computing power, cross-referencing data from different databases, and many others. This reality only ratifies the importance of the constant search for improvement in the application of anonymization techniques and maintenance of the protection of data already anonymized.
And what is the advantage of all this?
You might think that just the fact that there is a binding regulation on the processing of personal data and being in accordance with the law would be sufficient reason, but we’re going to list here some other relevant points that corroborate the importance and value of the process of anonymization of personal data.
The first point to be mentioned is the protection against loss of trust and market share. It’s not difficult to come across a news story about a data leak. Up to March 2021 alone, at least 8 (eight) cases have been reported in Brazil. Episodes like these can generate a lack of confidence in the company that suffered the leak and consequently result in impacts in the market. This is due to the fact that these leaked databases can be used as a reference for cross-referencing data in other bases, further increasing the risk of re-identification of the data. In this case, a well applied anonymization process works as a damage control measure.
Another advantage that can be noticed is the protection against misuse and exploitation of internal vulnerabilities. No matter how much you trust the staff handling or having access to sensitive data, there’s no way to guarantee the intentions of the person manipulating it. So the anonymization process helps to make it more difficult for potential internal attackers to misuse the data stored within the company.
What do you need to know before starting the anonymization process?
In order to get out of the conceptual field and start thinking about data impersonation, it is of fundamental importance to have a good understanding of the concepts, this way it’ll be possible to determine which techniques are most appropriate, as well as, the right level of anonymization. The relevant concepts are:
- Purpose of anonymization and usefulness of the data: it seems kind of obvious, but it’s important above all to have a good understanding of the motivation behind the idea of applying anonymization techniques to a given dataset. That’s because the process, regardless of the level or technique, will reduce the detail of the information contained in the original dataset to some degree. This creates a trade-off between acceptable (or expected) utility and attempting to reduce the risk of re-identification. It’s also important to keep in mind that this utility must be observed at the whole dataset level and not only at the attribute level.
- Characteristics of the techniques: it’s necessary to pay attention to the fact that certain methods are more appropriate for certain cases than others. Also, different techniques modify data in different ways.
- Information inference: it’s important to pay attention to the risk of crossing information. Even if a certain attribute is anonymized and with a low risk of re-identification, the risk of obtaining it through inference with the help of other attributes must be analyzed.
- Domain expertise: the appropriate choice depends on understanding the explicit and implicit information contained in the dataset, as well as the amount or type of information to be anonymized.
- Competence in the process and techniques: the anonymization task needs to be handled by someone with a good understanding of the entire procedure and its implications, especially for data being shared with third parties.
- Recipient: this is the person who will receive the anonymized data. So, factors such as knowledge on the subject and the application of control tools to limit their manipulation of the data, play an important role in the choice of the most appropriate techniques.
Can it be any kind of data?
One of the issues that will determine which anonymization techniques should be applied is the context. This can be thought of in terms of how the data is characterized. Depending on these characteristics, the techniques described in this text may not make sense or have the appropriate or expected effect. Therefore, before talking about these anonymization strategies you must first understand the scope of the data.
Another important distinction to observe, which impacts the choice of anonymization strategy, is the nature of the attribute itself: numeric or categorical. Numerical data is those that, as the name implies, are numbers. Thus, techniques that hide the value or replace it with another one cause a considerable drop in the usefulness of that data. Categorical data are those that can be viewed as distinct and finite groups based on some qualitative property. In both cases, it’s the analysis of the content of the attribute itself that will determine which technique is the most appropriate. Knowledge of the usefulness of that attribute and the risk of re-identification (given a certain technique and the level of anonymization applied) will guide the decision.
Techniques
With the purpose of the task in mind, as well as, the format of the data that will be anonymized and its particularities, one can then begin the process of analyzing and choosing which techniques will be used and on which attributes (or columns) they will be applied. These are some techniques:
- Generalization
This consists in reducing the precision of the data: the attribute values are substituted by others semantically similar, but less specific. In this way, generalization preserves the veracity of the data.
This is a technique that can be applied to both categorical and numerical attributes. When talking about numerical attributes, you could consider assigning a range. In this way, the data remains useful from an analytical point of view, without leaving explicit what the real data would be. In categorical attributes the strategy is similar, however, with a semantic hierarchy that abstracts the exact value of the data, but preserves the meaning.
It’s important to note that generalization cannot be done in a naive way, as this can lead to useless data, in particular for analysis tasks. Therefore, a minimal set of modifications should be sought in a way that favors utility and meets the minimum requirements for impersonation. An optimal solution to this problem unfortunately lies within the NP-hard class. Therefore, the most appropriate way is to search for a heuristic that reduces the search space and finds a near optimal solution.
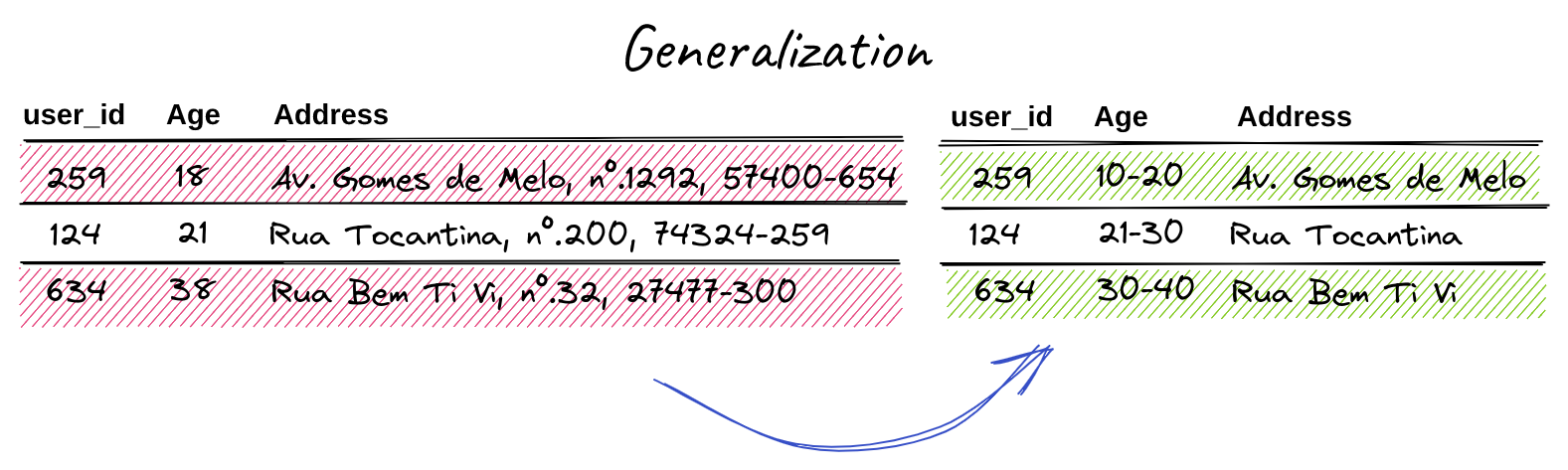
In the example above we can see the application of the technique in the columns “Age” and “Address”. In the first, the raw value of the individual’s age was transformed into an interval; in the second, there was a hierarchical abstraction of the value of the address field, which instead of having the street address, number and zip code, has only the name of the street address. These generalizations allow the information to preserve a certain level of analytical power and hide its exact value.
- Data aggregation
It’s the process of converting a set of data into a list of summary values. In other words, instead of a collection with several entries containing personal data, we transform it into new columns, which preserve the statistical properties of the base and mask the identity of the information carriers.
This tactic differs from generalization for numeric attributes, in that the latter only abstracts the value of each cell in a given column, while the former transforms the structure of the dataset, removing columns and creating others.
Care must be taken with the size of aggregate groups to avoid them having too few entries. For an attacker with enough information, a group with a single individual may contain information necessary for re-identification.

Here we can notice that the Donor information has been hidden by aggregating the monthly salary values in an interval, and the total donated no longer identifies an individual but corresponds to the sum of each set of intervals.
- Data masking
Also called character masking, this is a strategy focused on replacing characters in the value of a column or attribute with symbols such as “*” or “x”.
The masking is usually done partially on the attribute value, i.e. only part of the data is hidden. Thus, depending on its nature, the technique can be applied to a fixed quantity of characters (for example, in credit card numbers, since they have a specific length) or to a variable quantity (for cases such as e-mails, which have different lengths). To make this decision it’s necessary to analyze which part and size is most appropriate for masking so that the characters that remain visible do not make the re-identification possible.
For the special case in which the owner of the data must be able to re-identify it (for example, masking the last four digits of the Social Security Number in a contest result), it escapes the purpose of anonymization techniques, which is to make all possibilities of recognition by any individual impossible. Therefore, this scenario should be treated outside the scope of the impersonation task.
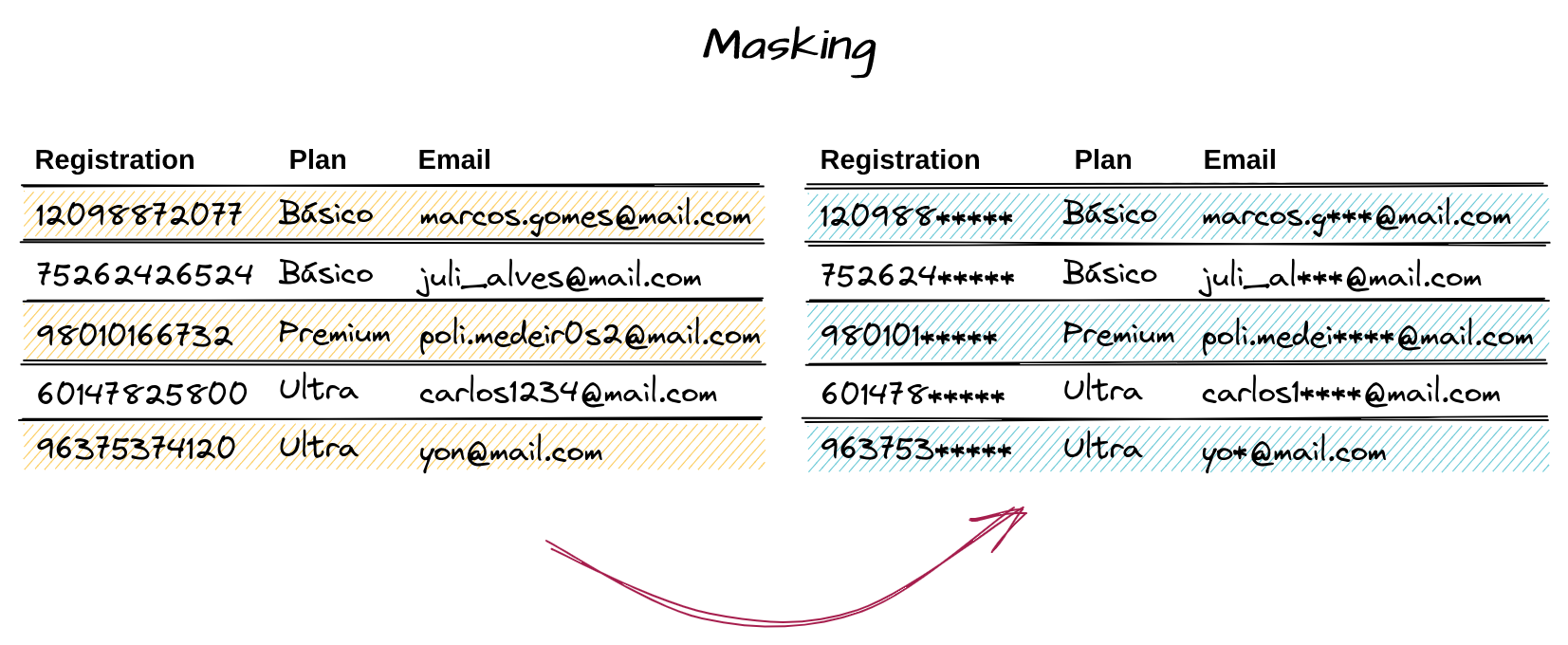
In the previous context, we can observe the two cases of masking: for the Enrollment column, a fixed number of characters were hidden, while for the Email field, which has a variable size, a fraction of the string was chosen (in this case, ⅓). It’s important not to determine an exact number of characters, as this can lead to the complete hiding of the information.
For cases where complete hiding of the data is more appropriate, a data suppression (technique where the column is completely removed from the database) is more suitable and less costly.
- Pseudo Anonymization
Probably one of the best-known anonymization techniques, pseudoanonymization is the replacement of an identifier with false values. These must be unique and unrelated to the original data.
The pseudonyms can be random or deterministically generated, but still, the information from the original data is completely lost. Thus, there is a great loss of usefulness. One attempt to preserve this is to use persistent pseudonyms, in other words, to use the same pseudonym to identify the same individual in several databases.
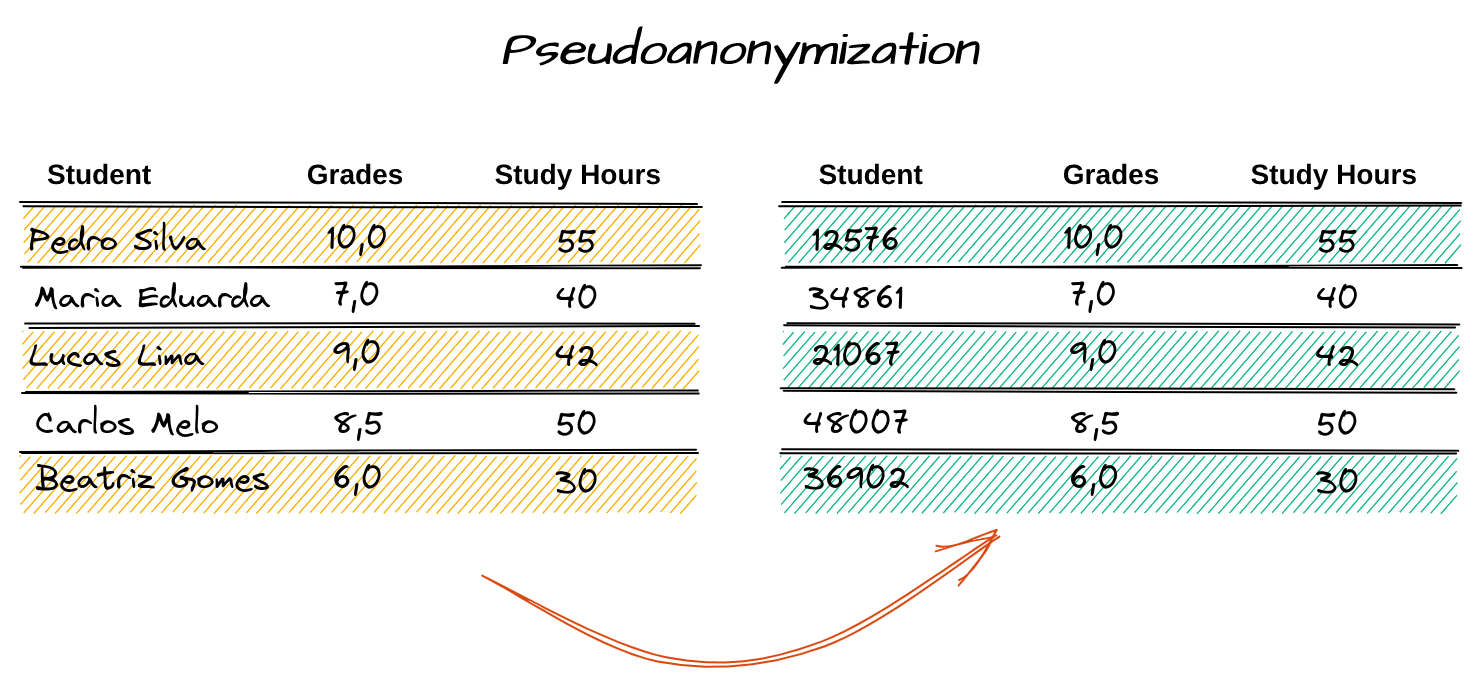
Notice in the example above that for the Student column, random false values have been generated to replace the original ones. Since this technique causes the total loss of information, another table is commonly used to relate the data before the anonymization to the one after, and it’s kept in the possession of third parties.
- Data Perturbation
In general, this technique consists in replacing the original attribute values by slightly different ones. Unlike generalization, this approach doesn’t preserve the veracity of the original data, so the usefulness of the data is strongly affected, even though the modification is subtle.
The degree of perturbation should be proportional to the range of the attribute values. In other words, if the base is small, the effect will be weaker, but if the base is too large, the difference in values can become too high. The disturbance can be done by adding noise (typical of numeric attributes), which consists of adding or multiplying the original value by an offset.
In this way, certain statistical properties are preserved, such as mean and correlation. On the other hand, it can produce values without expressive meaning. Another way of perturbation, applicable to numeric and categorical attributes, would be through another anonymization technique called data permutation. In this approach, different records are swapped with each other. Similar to noise addition, this method preserves some statistical properties (such as count and frequency), but ends up generating entries with no semantic value.

For the example above, we can notice that the data after the application of the technique suffered a small variation if compared to the original values, with the addition of noise. In this case, it was applied a rounding to the nearest multiples of five (height) and three (weight and age).
Conclusion
Data anonymization is therefore a task of latent importance nowadays. It demands not only sufficient effort in order to be properly applied, but also a thorough investigation and understanding of the data, as well as of the many different impersonation techniques.
The format and use of the data are the central points for defining the risks of re-identification of the original information. These will allow us to identify which attributes are the most favorable for impersonation. Then, the nature of the information will determine the most appropriate techniques so that the usefulness of the data is preserved as much as possible without compromising the masking of the information. Thus, it is important to have in-depth knowledge of the behavior of these strategies, not only to prevent the data from being associated with its owner, but also to ensure that it doesn’t lose its value from an analytical point of view.
The discussion of data anonymization is not limited to the scope of this paper. The purpose here was to bring an introduction to the subject in order to ratify its importance and to demonstrate some examples of its diversity of strategies. With this discussion, we hope that the readers can begin an analysis of their own scenario to start searching for the most appropriate way to apply anonymization to their databases.
References
BIONI, Bruno. Compreendendo o conceito de anonimização e dado anonimizado. Available at http://genjuridico.com.br/2020/08/05/conceito-anonimizacao-dado-anonimizado/ Accessed on July 25, 2021.
BRITO, Felipe Timbó. MACHADO, Javam. Preservação de Privacidade de Dados: Fundamentos, Técnicas e Aplicações. Available at https://www.researchgate.net/publication/318726149_Preservacao_de_Privacidade_de_Dados_Fundamentos_Tecnicas_e_Aplicacoes. Accessed on August 10, 2021..
CORPORATE FINANCE INSTITUTE. Data Anonymization: The process of preserving private or confidential information by deleting or encoding identifiers that link individuals and the stored data. Available at https://corporatefinanceinstitute.com/resources/knowledge/other/data-anonymization/. Accessed on August 11, 2021.
IMPERVA. What is Data Anonymization. Available at https://www.imperva.com/learn/data-security/anonymization/. Accessed on August 11, 2021.
MURTHY, S., BAKAR, A. Abu, RAHIM, F. Abdul, RAMLI, R. A Comparative Study of Data Anonymization Techniques | IEEE 2019 Conference Publication. Available at https://ieeexplore.ieee.org/document/8819477. Accessed on August 12, 2021.
PERSONAL DATA PROTECTION COMISSION SINGAPURE. Guide to Basic Data Anonymisation Techniques – 2018. Available at https://iapp.org/media/pdf/resource_center/Guide_to_Anonymisation.pdf. Accessed on August 11, 2021.
VASCONCELLOS, Hygino. Vazamento de dados de 220 milhões de pessoas: o que sabemos e quão grave é. Available at https://www.uol.com.br/tilt/noticias/redacao/2021/01/28/vazamento-expoe-dados-de-220-mi-de-brasileiros-origem-pode-ser-cruzada.htm. Accessed on August 11, 2021.