Those who work with data leak prevention tools are probably familiar with the Symantec DLP product, admittedly one of the best data leak prevention tools on the market.
The tool has a number of performance modules, the most common of which is the “DLP Endpoint”, which concentrates several performance functions for data leak prevention.
This technical article describes the resolution of problems applied to the Endpoint module, trying to explain the logic of the Endpoint Prevent as a whole, from the agent applied in the workstations, to the servers responsible for control and communication, as well as including routes and up to the technical level of the application.
Symantec is one of the companies with products focused on data security. One of these services offered includes Symantec DLP, which promises to monitor behavior in suspicious applications installed by the user, stop data theft, identify and prevent invalid applications from obtaining confidential data, and restrict transfers of non-conforming data and personal data of verifiable protection (according to the company’s own website). By analyzing Symantec DLP with a single Detection (Endpoint Server) you can understand the current status of your product health, as demonstrated below.
Firstly, by checking the status of each monitor and Enforce (the server responsible for administering the other monitors), it was possible to observe that the latter has more than 72 incidents in queue and the Endpoint Prevent is in “starting” status, without full operation. From this initial analysis and from the deepening of the suggested events and logs, the following results were obtained:
1. Enforce and the service “Symantec DLP Incident Persister”, responsible for the recordings of the .IDC files in the database, not doing its function, due to not having the necessary processing level.
2. Endpoint Prevent pointed out an error in the service responsible for delivering the incidents to the database. The monitor was not receiving new incidents.
Based on those situations, we have analyzed the alerts as well as the specific logs, allowing the identification of problems with critical and non-critical status, being them:
1. Event 1101 — Endpoint Agregator cannot start;
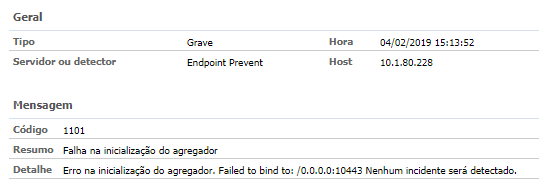
2. Event 3900 — Endpoint Agregator — Internal Communication Error;
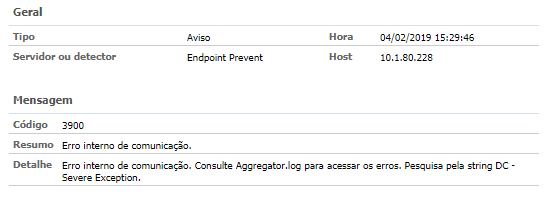
3. Event 1800 — Incident Persister cannot process the incident X;
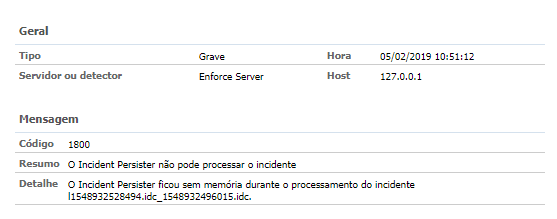
4. Event 2317 (non-critical) — Enforce E-mail Notification not sent;
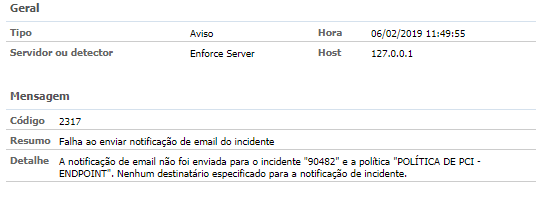
Once such events were identified, we analyzed whether traffic was affected in any way; either by the incidents’ halt or by the drop of some service, and we understood that the Endpoint Prevent service was not in full operation. Below is a picture of traffic during the week of the analysis, which shows a drop between January 31st and February 4th due to the queuing of unprocessed incidents stopped within Enforce.

With this information in hand, the Oracle Database was also analyzed in some specific tables, such as LOB_TABLESAPACE, responsible for storing the incidents. In this analysis, we obtained a fully satisfactory result, demonstrating that the health of the tables is at 100%, as shown in the image below.
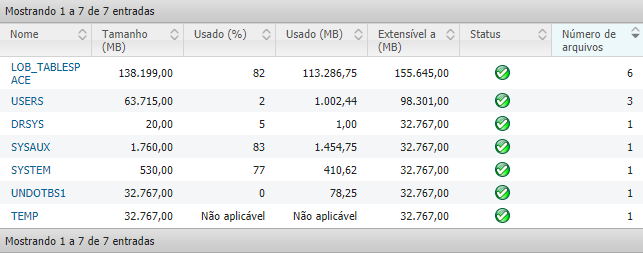
In order for the tables to work without problems, they must be configured by the person in charge of the database, so that if they are completely filled, new tables can be created and filled.
Possible Causes and Actions
The causes of the problems highlighted in the analysis are listed and described below. Some of these problems are interrelated, such as the level of processing in Enforce and Queued Incidents.
Queued Incidents
The queued incidents occurred due to the size of the .idc files (incidents) within the temporary folder where they remain until they are processed by the service responsible for delivering to the database. When the service does not have the required level of processing, it enters a processing and drop cycle. As it tried to load the incident into the database and could not do it, the time-out was activated and so, after a few seconds, another attempt was generated, which again resulted in a failure. As a result, incidents larger than 300mb remained in the temporary folder without being delivered, generating a queue.
Possible Action: Deliver more processing to the JVM responsible for uploading and administering the service, so you will have the necessary performance to send the database.
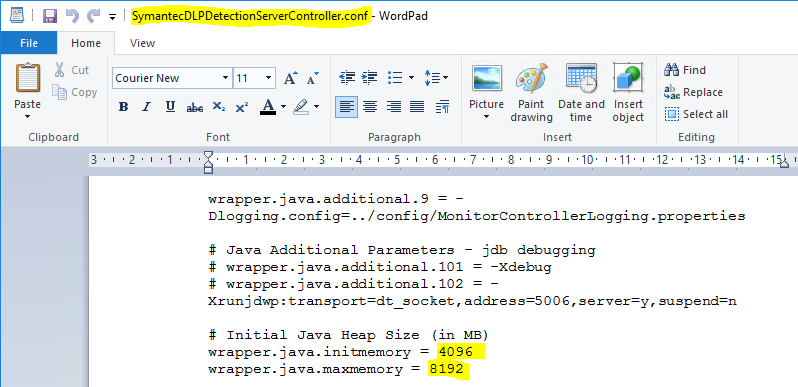
As an action taken to solve the “incidents in queue” problem, a modification was made to the environment involved in the server’s processing, asking for another 8gb of ram, leaving 16gb in total. In addition, the files responsible for the processing location for the JVM, through which it manages the DLP services, have been modified so that they can deliver the maximum processing necessary to the JVM, thus the incidents are delivered to the database. The change was made to the following path:
C:\Program Files\Symantec\Data Loss Prevention\Enforce Server\15.1\Protect\services, modificando os arquivos SymantecDLPDetectionServerController.conf, SymantecDLPIncidentPersister.conf, e SymantecDLPManager.conf.
Note on the images the specific locations of the files that were changed.
In the following areas:
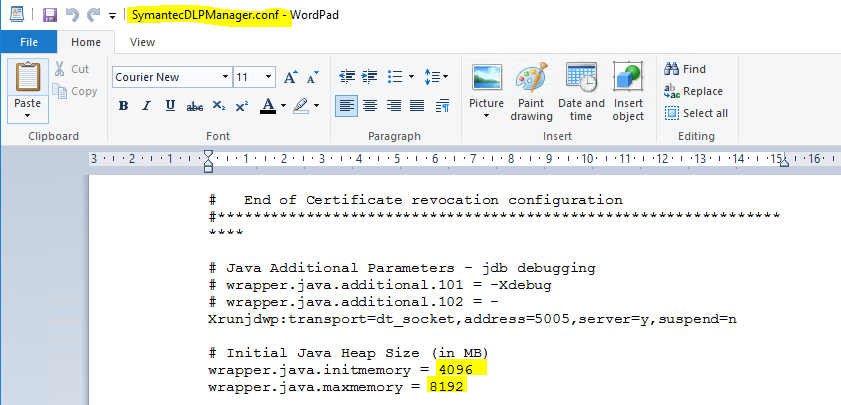 Modifications at the file SymantecDLPIncidentPersister.conf.
Modifications at the file SymantecDLPIncidentPersister.conf.
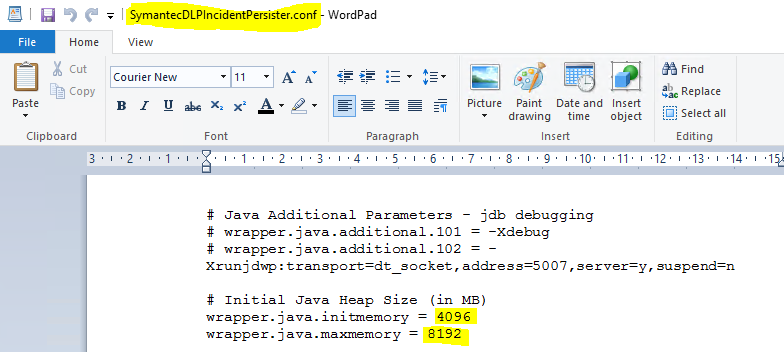
With these changes, it was possible to have the incidents processed and the queue zeroed, from incidents of 300mb to incidents of 1gb or more.
Result of the action;
– Queue zeroed;

· Server disk usage — from 80–85% went to 50–58%;
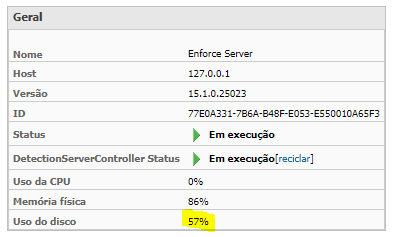
– Delivery of all .idc to the database, both the 300mb ones and the one with over1gb;
Action taken:
Endpoint without full operation
With the failure of the Agregator, which is responsible for the conference and the stabilization of the communication ports, the Endpoint is unable to receive or deliver the incidents, as it was not able to make the FQDN conference (absolute domain name). It was also observed that, by default, Company X is activating IPV6 on all servers. Also, for some reason not yet justified by Symantec, the Detection Endpoint Prevent service is not able to check the FQDN or raise the ports responsible for IPV6 traffic.
Possible action: Disable IPV6 and leave only IPV4 on the server until hearing a Symantec’s opinion. It is also recommended to configure the Communication file so that Bind runs in the correct way, because the file is different than usual.
Note: This possible action will result in the correction of both problems, this and “Endpoint server aggregator not initializing”.
Agregator Malfunction
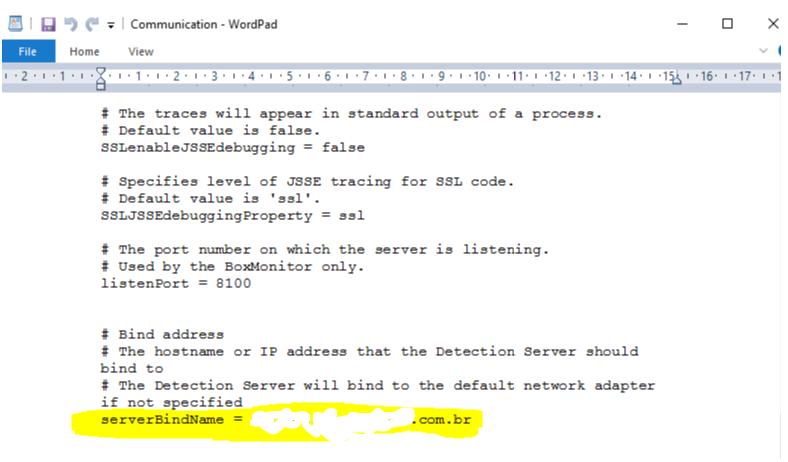
To solve the Agregator malfunction, the “Communication” file was modified inside the Endpoint Prevent server so that the Bind can be executed by FQDN (TestCompanyX.com.br). The IPV6 of the server was also deactivated and the IPV4 was maintained. The modification was made to the following file in the following location
C:\Program Files\Symantec\Data Loss Prevention\Detection Server\15.1\Protect\config, no arquivo Communication.
Through this process it was possible to restart the Endpoint Prevent services, and the communication returned to normal, as well as the monitor to deliver and receive the incidents.
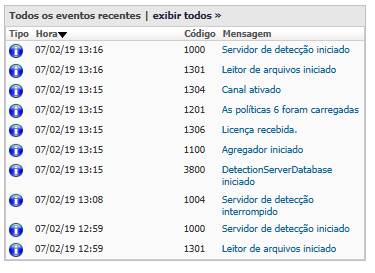
Result of the action:
– Endpoint Prevent service working normally;
– Agregrator keeping the conference running smoothly;
Incident Persister not processing incidents
Incidents from Endpoint prevent were directed to a temporary Enforce folder awaiting processing by the Persister Service. However, the service was unable to process any incident greater than 300mb due to its processing timeout and required branch.
Possible Action: Change the files responsible for the processing limit pointing given to the JVM that controls the services, thus respecting the server’s 8gb ram memory limit. With this change, the JVM will allocate more memory for processing the incidents considered large (greater than 300mb).
Enforce Server Disk with over 80% usage.
Like the 300mb incidents, in this case, the JVM was forced to process the incidents and by failing to give the “time-out” and finalize the process, for, seconds later, starting it again, forcing the server processing. With the possible action suggested in the following item “Queued incidents”, it would be possible to decrease the processing, because incidents up to 800mb will be processed; but only those with weight less than 1gb.
Possible action: Increase the server’s ram memory from 8gb to 16gb and configure the files responsible for the JVM and processing division so that they can use as much processing as necessary without delivering a “time-out”.
Recommendations for improvements to the environment
Point 1 — In order for the environment to work without a single monitor being overloaded with all the functions, it would be of great interest and technical beauty if more Detections were added to the environment, such as Mail Prevent, which could take full responsibility for analyzing the traffic and files that navigate through SMTP. This would take a great deal of processing away from Endpoint agents, making the policies currently applied to do SMTP inspection focused on other information processes.
In order to retain email and not delete it in any eventual blocking policy, it is also recommended the integration with Symantec Anti-Spam, SMG (Symantec Messaging Gateway), as well as the integration through Flex-Response. This way it is possible to activate the quarantine mode, so that administrators can release or delete messages that were detected through the DLP, thus maintaining greater control and agility in the DLP’s WorkFlow.
Point 2 — Another recommended monitor is the Discover; this monitor scans mainly File Server, thus being able to point policies with intelligence for recognition of critical documents for the business and/or confidential for certain areas, causing them to be removed from certain directories and relocated to another, thus ensuring that only directories with allowed and regulated access can have permission to read and modify specific files.
This monitor allows you to place a .txt warning in the directory where the document that was reallocated was so that the user knows about the action.
Point 3 — In order to test policies rather than effective blockades, Detection server Monitor is indicated. This is the only detection that Symantec asks to be physical, because of network cards. The detection is connected directly to the switch’s span port in order to monitor and discover traffic protocols that navigate the company’s internal network, thus having a view of everything that is mirrored to it. In addition, they can test with any type of policy they need to develop and create maturity before applying to their monitors.
Conclusion
It is not advisable to add all the tasks of Symantec DLP in a single Detection; it is indicated to distribute the tasks of prevention to the Detections each with its specific channel of communication.
This article is intended to help analysts and consultants in the information security area to promote an analysis of the environment of the Symantec DLP product.
Recommended readings for further protection and mitigation methods:
Site:
https://support.symantec.com/en_US/article.DOC10941.html
Data Loss Prevention DLP-S500 Hardware Appliance Quick Start Guide
https://www.symantec.com/docs/DOC10613
Symantec Data Loss Prevention Administration Guide
https://www.symantec.com/docs/DOC9261
Symantec Data Loss Prevention Detection Customization Guide
https://www.symantec.com/docs/DOC9356
Symantec Data Loss Prevention Email Quarantine Connect FlexResponse Implementation Guide
https://www.symantec.com/docs/DOC8720
Symantec Data Loss Prevention Endpoint Server Scalability Guide
https://www.symantec.com/docs/DOC8789
Symantec Data Loss Prevention MTA Integration Guide for Network Prevent for Email
https://www.symantec.com/docs/DOC9467
Symantec Data Loss Prevention Release Notes
https://www.symantec.com/docs/DOC10600
Symantec Data Loss Prevention System Maintenance Guide
Symantec Data Loss Prevention System Requirements and Compatibility Guide