The Internet is a hostile environment. It’s not uncommon to hear about data leaks and hackers compromising online applications and systems. In fact, any system that interacts with the internet must be prepared to defend itself from a large arsenal of techniques and attacks, used by malicious agents, in an attempt to subvert functionalities of an application. Among the many techniques employed by these agents, one of the most common, and most basic ones, is Brute Force Attack.
According to the 2020 Data Breach Investigations Report, of the 3,950 data leaks analyzed, more than 80% of them made use of stolen credentials or Brute Force Attacks.
A Brute Force Attack consists of trying to set valid credentials for an application through trial and error of all possible values — or at least a large number of possible values. These are attacks made by scripts or programs that automate requests for the application’s login functionality, sending different combinations of usernames and passwords, until a valid credential is found.
Although Brute Force is commonly used against authentication mechanisms, an attacker may benefit from attacks against any data processing features. In registration and password recovery mechanisms, for example, this abuse can generate harmful consequences to the target application.
In this blogpost, we will address problems related to Raw Force attacks, presenting some tools used by the attackers, proposed solutions to defend these attacks, the respective consequences for each proposed solution and, finally, the layers of protection needed against the Raw Force.
Impact
Since it is possible to automate the sending of requests to an authentication mechanism by performing numerous login attempts, a sufficiently motivated attacker will commit the target with valid credentials in a matter of time.
Brute Force attacks can also be used to enumerate valid users in the application when it displays the characteristic enumeration behaviors. This makes it possible to make a list of valid names even before login attempts actually begin (for more details on enumeration, see the blogpost Once upon a time the enumeration of users ).
Another common use of these attacks is the exploitation of functionalities available in non-authenticated areas, which can generate nuisance and damage to users or to the institution responsible for the application. An example is the abuse of functionalities for sending SMS with multi-factor authentication confirmation code; which, if requested in large scale, will generate costs for the company and torment users.
These are just some of the possible impacts that such an onslaught may have on the mentioned functionalities.
The faces of the problem
Raw Force Attacks, especially against authentication mechanisms, can be performed vertically and horizontally.
Vertical attack
The vertical attack, being the most common one, consists of performing a large number of authentication attempts for different passwords applied to the same username (login); and following to the next user after the password of the previous one is found, or after the list of passwords used is finalized.
Vertical attack is usually the method adopted when there are no restrictions for multiple attempts. The following image is an example of a setup for a Vertical Attack using the Burp Intruder:
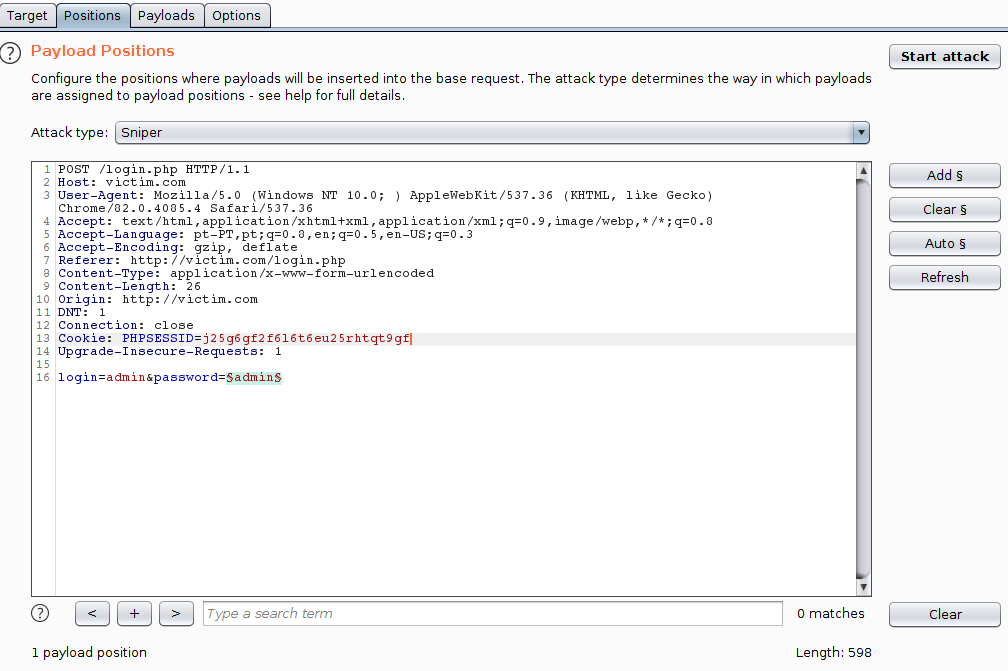
In the next image, we see a successful vertical attack:
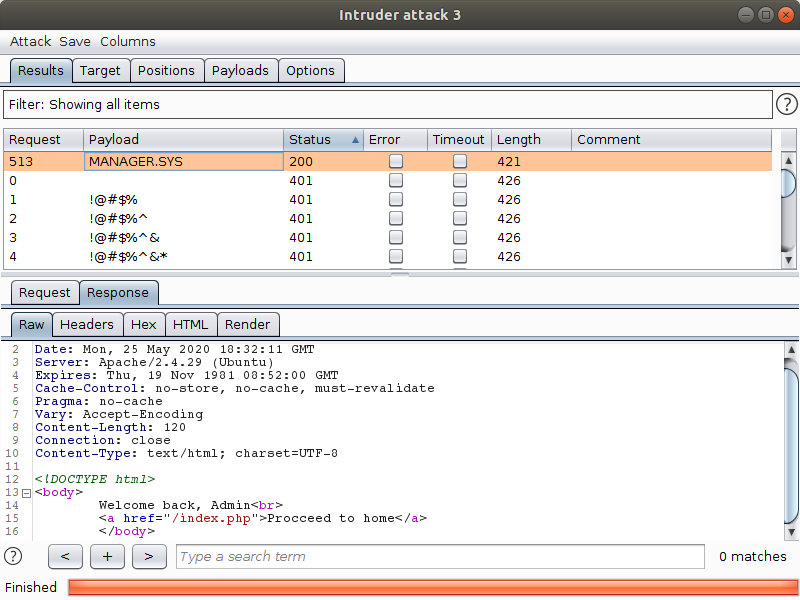
Horizontal Attack
Horizontal attack is a more discrete approach of Raw Force Attacks. Unlike the vertical attack, in it, several authentication attempts are made for different users using the same password. In this way, it can be used as an outline measure to more restrictive mechanisms that limit the number of login attempts of the same user. When an application has a weak password policy, this attack can be done using a list of weak and common passwords (there are many public lists with common credencials available on the Internet), in an attempt to hit users who make use of this type of password. This process can also be called password spraying.
Dictionary
Dictionary Attacks are a refined strategy of Brute Force Attacks, which can generate a decrease in the total number of attempts made on the attack. Dictionaries are lists containing user names and/or passwords to be applied to the attempts. Thus, instead of automating the generation, in order to decrease the number of requests made, the Dictionary Attacks can be used.
It is common for dictionaries to be composed of credentials leaked from databases, or from known users, listed from the application itself. Another way to compose dictionaries is to use information from a specific target to compose a list of possible passwords from the potential victim. There are some tools that contribute to the process of generating these lists, such as cupp, CeWL or Mentalist.
Task Automation
The automation process that constitutes the attack in question can be performed through software developed for this purpose, such as Burp Intruder, from Burp Suite. However, it is common for custom scripts to be written for this task, especially when some data manipulation is required in the request, or when the process occurs in multiple steps.
The most diverse programming languages can be used to build these scripts, however, the most common for this type of composition is Python.
Python has numerous libraries related to the Internet. In fact, thanks to tools like the HTTP Requests library, it is possible to make a request with less than two lines. So, of course, Python ends up being the main language chosen by beginners and veterans for this kind of task.
Below we describe some tools for composing automation scripts, all available in libraries for the Python language.
Selenium Webdriver
Selenium is a web application testing framework that allows you to write scripts to send commands directly to the browser, simulating user interaction with page elements.
It is an especially useful tool when the requests made to a server involve complex processes such as encryption and hash calculation, or when the amount of requests needed for the action is large, with parameters and values being reused between requests. Selenium controls the browser remotely, so it is unnecessary to program any task that does not need to be executed by the user.
#!/usr/bin/env python3 from selenium import webdriver from time import sleep browser = webdriver.Firefox() browser.get(“https://www.google.com.br”) element = browser.find_element_by_xpath(“/html/body/div/div[3]/form/div[2]/div[1]/div[1]/div/div[2]/input”) element.click() element.send_keys(“Tempest”, u’\ue007') sleep(3) link_list = browser.find_elements_by_partial_link_text(“Home”) for link in link_list: if “Tempest” in link.text: link.click() break
The above script, for example, automates a Google search for the keyword “Tempest” and clicks on the first link that leads to a page with “Tempest” and “Home” in the title.
Monkeyrunner
Monkeyrunner is a testing framework for Android applications that allows you to simulate user interaction with the device, controlling features through Python scripts.
Part of Android Studio Development Kit, Monkeyrunner can be used to automate actions on Android devices and emulators like Genymotion. Like Selenium, it is especially useful when requests to complete an action are intricate or numerous, or when the application performs some kind of encryption or obfuscation. This tool can be used on a device with developer mode enabled, even if it has not gone through a ‘Rooting’ process.
from com.android.monkeyrunner import MonkeyRunner, MonkeyDevice device = MonkeyRunner.waitForConnection() logins = [] for line in open(‘~/Documents/logins.txt’,’r’): logins.append(line.rstrip()) activity = ‘br.com.app.activity.LoginActivity_’ runComponent = activity device.startActivity(component = runComponent) for login in logins: MonkeyRunner.sleep(6) device.touch(200,785,’DOWN_AND_UP’) device.type(conta) MonkeyRunner.sleep(1) device.touch(550,1101,’DOWN_AND_UP’) MonkeyRunner.sleep(2) device.touch(286,1502,’DOWN_AND_UP’) MonkeyRunner.sleep(2) device.touch(286,1502,’DOWN_AND_UP’) MonkeyRunner.sleep(2) device.press(‘KEYCODE_BACK’,MonkeyDevice.DOWN_AND_UP) MonkeyRunner.sleep(1) device.startActivity(component=runComponent)
The above script simulates the user interaction with the login activity screen. From a list of logins, the script inserts the values in the input field of the authentication form on the screen, pressing the confirmation button right after, repeating the process until all logins have been evaluated.
Frida
Frida is a command injection tool in native applications of several operating systems. It can be used for reverse engineering and debugging of applications compiled in these systems. It is the commonly used tool for bypassing protections like SSL Pinning and Root Detection. This tool can be used to create automated tasks in applications to perform brute force attacks.
Solutions
In practice, developers employ several mechanisms in an attempt to prevent these attacks; however, some implementations may introduce new security problems to applications. The following is a list of some of the solutions found in real applications, as well as their consequences.
IP Blocking
An unorthodox solution, but which is being usually applied, is IP blocking. This approach consists in adding the user’s IP to a list of blocked IPs that lose the right to partial or total access to the application, for a certain period of time or, in some cases, indefinitely.
Although, at first, this may seem a good solution to the problem of many requests being made in an automated way by an attacker, the adoption of a blocking functionality of any kind opens the possibility of exploiting this functionality in denial of service attacks directed to users. That is, a malicious user can use tools to compose packets disguising their IP with the IP address of a victim and make an excessive number of requests until causing the blocking of the victim. In more extreme situations, all users on a shared network can be blocked as a result of the implementation of this automatic suspension mechanism.
User Blocking
Similar to IP Blocking, this solution chooses to block accounts of users whose credentials were incorrectly provided by a user, a certain number of times. In some cases, there is a time interval, within which the credentials must be mistakenly attempted for the blocking. In addition, such cases can be bypassed with a Horizontal Brute Force approach in an attempt to avoid blocking while searching for a valid credential.
As with an IP blocking feature, there is also the potential here to exploit this feature and use it in denial of service attacks targeted at application users.
Furthermore, such blocking can generate the enumeration of users depending on how they behave (as can be seen in the blogpost mentioned above).
CAPTCHA
The acronym CAPTCHA, which stands for “Completely Automated Public Turing Test to Tell Computers and Humans Apart,” translated to “public and fully automatic turing test to differentiate computers from humans,” consists of a cognitive challenge easily solved by a human, but computationally complicated to solve. Common tests are: choosing specific images from a group of images, given a keyword; or reading blurred characters in an image.

Common CAPTCHAs, based on challenges and responses, should implement computationally difficult challenges to be solved and whose probabilities of success based on pure luck are low.
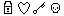
On the image above, we have a failed CAPTCHA. Your challenge is, given a keyword, find the image that best represents that word. So, regardless of whether the images are simple or intricate, because they are only 4, a script has a 25% chance of getting the challenge right by pure chance. This percentage may be acceptable for an attacker, depending on the functionality protected by this CAPTCHA.
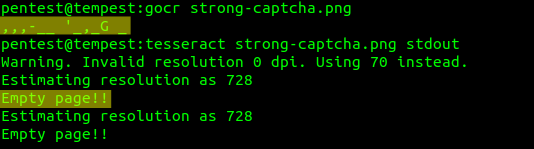
Another common failure in implementing the CAPTCHA challenge is the use of images easily recognized by optical character recognition programs such as GOCR and Tesseract. The following image, for example, can be completely interpreted by a character recognition software:
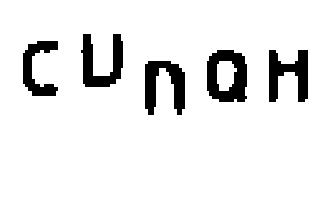

Other images can be partially safe, that is, the character recognition programs can solve part of the CAPTCHA, they end up erring on some characters, as the following images show:
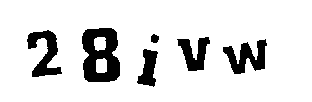

CAPTCHA implementations that consider correct answers with one or two wrong characters are vulnerable to Brute Force attacks if they use images that can be partially solved by this software.
There are also some methods to try to optimize the analysis of these challenges. It is possible to perform image treatment on CAPTCHAs, in an attempt to increase the software hit rate; however, a simpler option is to “train” the GOCR using previously collected images as samples. The larger the sample bank, the more likely it is to increase the hit rate.
Images used as CAPTCHA should be generated dynamically, having a level of obfuscation large enough to prevent, or at least hinder, the aforementioned optimization techniques.

NoCAPTCHA ReCAPTCHA is an implementation of CAPTCHA that aims to reduce the amount of challenges presented to customers, having as its main differentiation factor the user behavior when making a request. This type of implementation evaluates aspects such as time spent on the page, typing pattern, mouse movements and clicks to estimate a level of risk for each user. When the calculated risk level for a user is high, a challenge with the same level of solution is then proposed to this user.
CAPTCHAs are one of the most common measures against Brute Force attacks, so malicious users will always look for a way around them. Either through the aforementioned measures or, in some cases, by paying for CAPTCHA resolution services. Therefore, the ideal implementation of CAPTCHAs is an extra layer of security for your application.
Multi-factor authentication
Multi-factor authentication is a method of authentication that depends on a second communication channel in addition to the connection to the server. It is very common as a second layer of security for critical actions in an application such as login, password changes and purchase confirmation. It usually consists of sending a confirmation code by SMS, email or authentication service such as Google Authenticator and Authy. The multi-factor authentication can also be performed through an identification token installed on an authorized device, as is the case for many banking applications.
Multi-factor authentication can work as a good way to prevent unauthorized personnel from performing actions on behalf of third parties but should be implemented with care to avoid listing users. When authentication takes place in multiple steps, care should be taken to avoid that credentials are compromised by requesting the authentication code.
A possible disadvantage of Multi-factor authentication is that, depending on the medium used (such as SMS, for example), it can generate another problem for the company. Users capable of requesting an unlimited amount of code can use Brute Force Attacks to request the sending of a large amount of SMS to one or many users, possibly generating costs for the company that is the victim of the attack, as well as causing discomfort for the user that is the target of that attack. Ideally, you should limit the amount of SMS that can be requested by a given IP (see Rate Limiting below) or choose to use an authentication service.
Proof of Work
The Proof of Work protocol emerged as a form of prevention against email spam and denial of service attacks. This protocol aims to ensure that the user has spent some time to perform a certain task from a computationally costly challenge that needs to be resolved for a certain action to be authorized. This is the protocol used by some cryptomites, such as bitcoin.
Proof of Work functions as follows:
1. The client requests the execution of an action or access to a service;
2. The server responds to the user with a challenge to be solved;
3. The client solves the challenge and sends the response to the server;
4. The server analyzes the response to the challenge and, if correct, authorizes the client’s request.
In some implementations, the service request process takes place in parallel to the challenge response, but the protocol flow is basically the same.
Similar to the CAPTCHA, where a challenge must be solved. The proof of work protocol, however, proposes a challenge that is automatically solved by the customer, that is, the resolution of the challenge consists of the execution of code on the user’s computer, and the answer to that challenge is the output of that execution.
The most popular of the Proof of Work mechanisms is HashCash, where the proof consists of, given a string provided by the server, finding the complement of this string so that the resulting hash starts with the amount of zeros expected by the server.
In the following example, when making a request to the target site, a “Challenge” cookie and a “Zeroes” cookie are served to the customer. Both cookies are then used to calculate the value that is sent in the “challenge” field of the Login form:
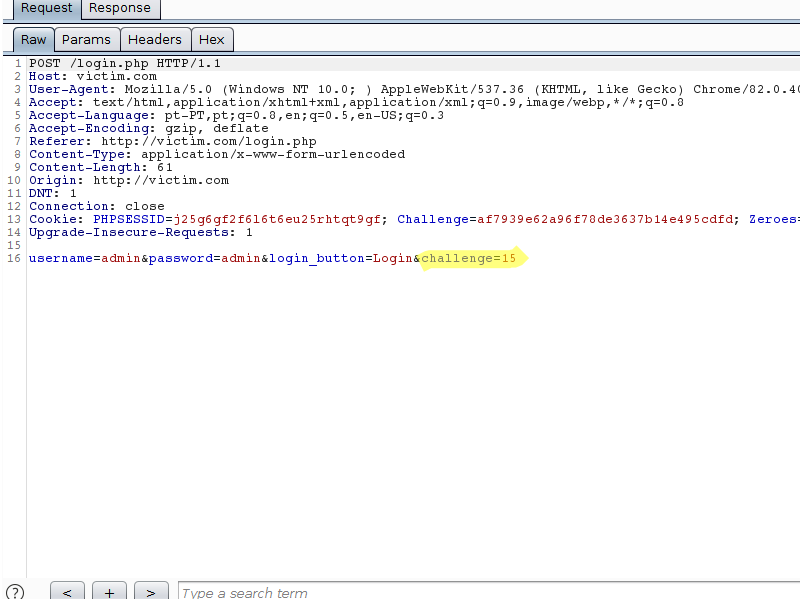
Note that the answer to the challenge is simply a string which, when concatenated with the string in the “Challenge” cookie, can be used to obtain a SHA256 hash starting with the amount of zeros specified by the server.
Still on the same server, when the Challenge parameter is missing or contains an incorrect value, the server response is an error, and the request is not processed.
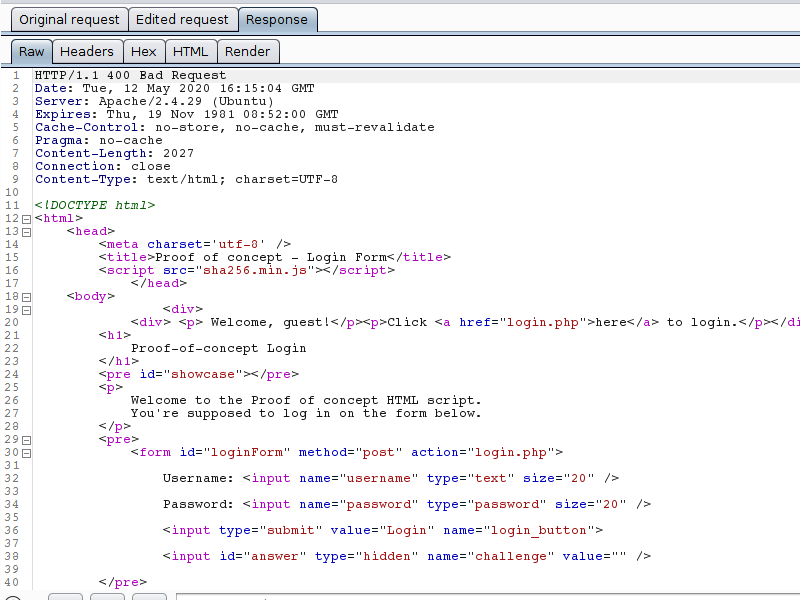
As wrong attempts are made, the server increases the difficulty of the challenge, by increasing the number of zeros needed for the answer to be considered correct. This increase in computational power is aimed at damaging automated requests, which require more time to calculate the response to the proposed challenge.
From the fifth zero, the browser starts to take about 1 minute to calculate the response to the challenge. And from the sixth, the browser understands that the tab is no longer responding, taking about 8 minutes to complete the hash calculation.
The Proof of Work protocol can, in a certain way, delay automated attacks, since it is necessary, not only the automation of the requests to be executed, but also the resolution of the problem proposed by the protocol, which is solved by code implemented on the client side. In mobile applications, for example, obtaining the code snippet responsible for solving this problem can be a complicated task, involving reverse engineering of the application. Even in web applications, the Javascript responsible for solving the proposed problem may be overshadowed, undermined and poorly readable.
One way to get around these solutions is to use behavior automation, with tools like Selenium and Monkeyrunner. The automation through these tools is a little slower, since the script simulates the user’s behavior and not the requisitions needed to complete the service request. If this possibility of automation, even if slower, is still a problem for a certain functionality, the best option to prevent this type of attack is the use of robust CAPTCHA.
Rate Limiting
Rate Limiting algorithms aim to control the rate at which users can make requests to the server, whether the limit is controlled from the IP or the user. There are some implementations for this type of control, but, in general, the algorithms keep a record with the requests of each user and the timestamp of the moment they were made. Whenever a new user request arrives to the server, the previous values are consulted to determine if the request is or not authorized to be processed by the application.
When choosing to use Rate Limiting as the control method, care must be taken with parameters that will be limited. Attaching the request limit to the user’s session can show a useless defense, especially for attacks against authentication mechanisms; since the default behavior of web applications for requests without a session token is the provision of a new token with a completely new session.
Some APIs implement the Rate Limiting mechanism in authenticated areas. Thus, once the user’s token is known, as soon as the abuse attempt is detected, it has its access to the functionality in question, or even the application itself, suspended.
Virtual Keyboards
An unorthodox alternative, but one that can be found implemented in production environments, is the use of virtual keyboards. Commonly used as a defense against keyloggers and spyware, virtual keyboards are usually implemented in banking applications, forcing the user to type his pin or password from the virtual interface and not the physical keyboard. They can also change the order of keys and sometimes even obfuscate their real value by changing the numbers of the pin for codes that correspond to the value of the keys typed.
A common confusion among developers, however, is to believe that, by preventing the user from typing using their own keyboard in the web interface or application, they can somehow prevent scripts from being automated; or that obfuscation, however simple it may be, does so.
Bypassing these protections can be somewhat trivial, even for inexperienced attackers. The simplest tool for this is Selenium Webdriver, but a simple analysis of the Javascript responsible for the virtual keyboard is more than enough to understand this type of mechanism. Once the process of obfuscation is understood, the preparation of scripts to automate the necessary requests becomes uncomplicated.
Conclusion
As with any other security problem, there are no universal solutions for Brute Force attacks. The best choice for any solution depends on an analysis of your system scenario, to be sure of what best fits your context. Your system may be an API consumed by other applications, so there is no way to employ CAPTCHAs. Or, imagine that its functionality is of critical importance, but its users have difficulties to solve more complex challenges. These are just two possible scenarios, which illustrate the need for well-studied solutions for each case.
In any case, the different solutions presented here can be used as a single defense mechanism, with different layers of protection, thus offering greater defense for more critical functionalities. However, attention should be paid to the possible consequences of adopting each of these solutions, since the choice of the anti-automation mechanism should be made with caution, in order to consider the functionalities to be protected.
It is important to point out that, many times, Brute Force attacks are used to exploit some other vulnerability in the application, be it an information leak, privilege escalation or command injection. Protecting your Brute Force application and not solving the exploited vulnerabilities will, at most, delay a determined attacker. Brute Force attacks can then be taken as symptoms, and a more careful analysis should be performed.
References
3.8.3 Documentation. 2020. Available at: https://docs.python.org/3/. Access: 20 May 2020.
FRIDA: A world-class dynamic instrumentation framework. A world-class dynamic instrumentation framework. 2020. Available at: https://frida.re/. Access: 20 May 2020.
GOCR. 2018. Available at: http://jocr.sourceforge.net/. Access: 20 May 2020.
MONKEYRUNNER. 2020. Available at: https://developer.android.com/studio/test/monkeyrunner. Access: 20 May 2020.
STUDDARD, Dafydd; PINTO, Marcus. The Web Application Hacker’s Handbook: discovering and exploiting security flaws. 2. ed. Indianapolis: John Wiley & Sons, Inc., 2011. 853 p.
TESSERACT documentation: Tesseract OCR. Tesseract OCR. 2020. Available at: https://tesseract-ocr.github.io/. Access: 22 May 2020.
WEBDRIVER: Documentation for Selenium. 2020. Available at: https://www.selenium.dev/documentation/en/webdriver/. Access: 22 May 2020.