Por Antônio Paulino
A internet é um ambiente hostil. Não são incomuns notícias sobre vazamento de dados e hackers comprometendo aplicações e sistemas online. De fato, qualquer sistema que interage com a internet, deve estar preparado para se defender de um grande arsenal de técnicas e ataques, usados por agentes maliciosos, na tentativa de subverter funcionalidades de uma aplicação. Entre as muitas técnicas empregadas por esses agentes, uma das mais comuns, e mais básicas, é o Ataque de Força Bruta.
Segundo o 2020 Data Breach Investigations Report, dos 3.950 vazamentos de dados analisados, mais de 80% deles fizeram uso de credenciais roubadas ou Ataques de Força Bruta.
Um Ataque de Força Bruta, do inglês Brute-force attack, consiste em tentar acertar credenciais válidas para uma aplicação a partir de tentativa e erro de todos os valores possíveis — ou pelo menos de uma grande quantidade de valores possíveis. São ataques feitos por scripts ou programas que automatizam as requisições para a funcionalidade de login da aplicação, enviando diferentes combinações de nomes de usuário e senhas, até que uma credencial válida seja encontrada.
Embora a Força Bruta seja comumente utilizada contra mecanismos de autenticação, um atacante pode se beneficiar de ataques contra quaisquer funcionalidades que processem dados. Nos mecanismos de cadastro e recuperação de senha, por exemplo, este abuso pode gerar consequências danosas à aplicação alvo.
Neste blogpost, vamos discorrer sobre os problemas relacionados a ataques de Força Bruta, apresentando assim algumas ferramentas utilizadas pelos atacantes, soluções propostas para defesa desses ataques, as consequências respectivas para cada solução proposta, e, por fim, as camadas de proteção necessárias contra a Força Bruta.
Impacto
Uma vez que é possível automatizar o envio de requisições para um mecanismo de autenticação, realizando inúmeras tentativas de login, um atacante, suficientemente motivado, comprometerá o alvo com credenciais válidas, numa questão de tempo.
Ataques de Força Bruta podem também ser usados para enumerar usuários válidos na aplicação quando esta apresenta os comportamentos característicos de enumeração. Assim, torna-se possível a confecção de uma lista de nomes válidos, antes mesmos das tentativas de login começarem de fato (para maiores detalhes sobre enumeração, veja o blogpost Era uma vez uma enumeração de usuários).
Outro uso comum desses ataques, é a exploração de funcionalidades disponíveis em áreas não autenticadas, e que podem gerar incômodo e prejuízos a usuários ou à instituição responsável pela aplicação. Um exemplo é o abuso de funcionalidades de envio de SMS com código de confirmação de autenticação multifatores; que, podendo ser solicitado em massa, gerará custos para a empresa e atormentará os usuários.
Estes são apenas alguns possíveis impactos que tal investida pode acarretar nas funcionalidades mencionadas.
As faces do problema
Ataques de Força Bruta, especialmente contra mecanismos de autenticação, podem ser efetuados de forma vertical e horizontal.
Ataque vertical
O ataque vertical, sendo o mais comum deles, consiste em realizar um grande número de tentativas de autenticação para senhas diferentes aplicadas a um mesmo nome de usuário (login); e seguindo para o próximo usuário depois que a senha do anterior for encontrada ou depois da lista de senhas utilizada ser finalizada.
O ataque vertical é, normalmente, o método adotado quando não há restrições para múltiplas tentativas. A imagem a seguir é um exemplo de setup para um Ataque Vertical usando o Burp Intruder:
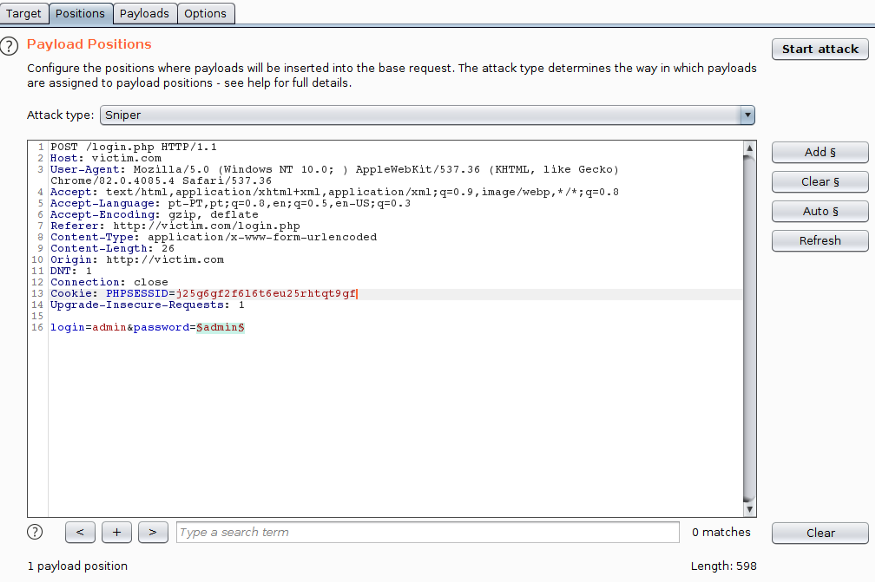
Na próxima imagem, vemos um ataque vertical bem sucedido:
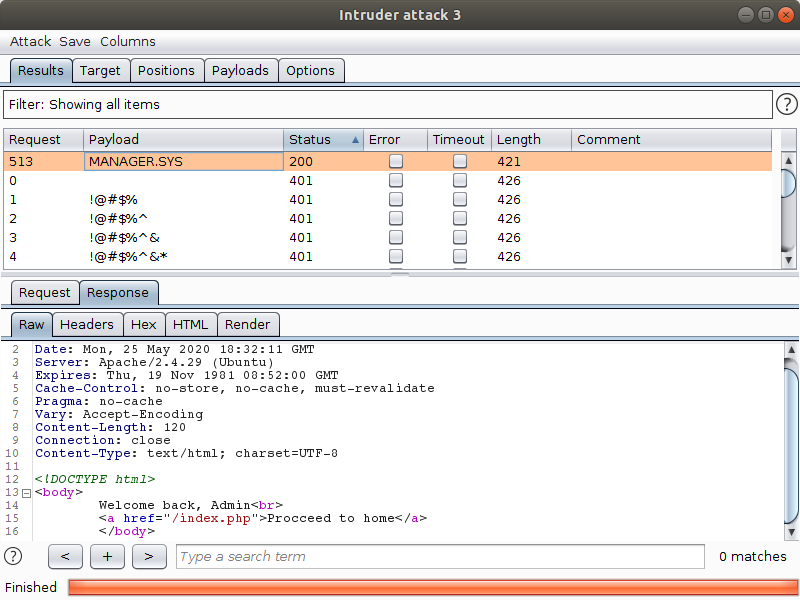
Ataque horizontal
O ataque horizontal é uma abordagem mais discreta de Ataques de Força Bruta. Ao contrário do ataque vertical, nele, várias tentativas de autenticação são feitas para diferentes usuários usando a mesma senha. Desta forma, ele pode ser empregado como medida de contorno a mecanismos mais restritivos que limitem o número de tentativas de login de um mesmo usuário. Quando uma aplicação possui uma política fraca de senhas, esse ataque pode ser feito usando uma lista de senhas fracas e comuns (existem muitas listas públicas com credenciais comuns, disponíveis na Internet), na tentativa de acertar usuários que usem esse tipo de senha. Esse processo pode também ser chamado de password spraying.
Dicionário
Ataques de Dicionário são uma estratégia refinada de Ataques de Força Bruta, que podem gerar uma diminuição do número de tentativas totais realizadas na investida. Os dicionários são listas contendo nomes de usuários e/ou senhas a serem aplicadas às tentativas. Assim, ao invés de automatizar a geração, com o intuito de diminuir o número de requisições feitas, pode-se utilizar os Ataques de Dicionário.
É comum que dicionários sejam compostos por credenciais vazadas de bancos de dados, ou de usuários conhecidos, enumerados a partir da própria aplicação. Outra forma de compor dicionários é usando informações de um alvo específico para compor uma lista de possíveis senhas da potencial vítima. Existem algumas ferramentas que contribuem com o processo de geração dessas listas, como o cupp, o CeWL ou o Mentalist.
Automatização de Tarefas
O processo de automatização que constitui o ataque em questão pode ser realizado através de Softwares desenvolvidos com esse objetivo, como o Burp Intruder, do Burp Suite. Entretanto, é comum que scripts personalizados sejam escritos para essa tarefa, especialmente quando é necessária alguma manipulação dos dados na requisição, ou quando o processo ocorre em múltiplas etapas.
As mais diversas linguagens de programação podem ser usadas para construção desses scripts, entretanto, a mais comum para esse tipo de composição é Python.
Python dispõe de inúmeras bibliotecas relacionadas à Internet. De fato, graças a ferramentas como a biblioteca HTTP Requests, é possível fazer uma requisição com menos de duas linhas. Assim, naturalmente, Python acaba sendo a principal linguagem escolhida por iniciantes e veteranos, para esse tipo de tarefa.
A seguir, estão descritas algumas ferramentas para composição de scripts de automação, todas disponíveis em bibliotecas para a linguagem Python.
Selenium Webdriver
Selenium é um framework de testes de aplicações web que permite escrever scripts para enviar comandos diretamente para o browser, simulando a interação do usuário com os elementos da página.
É uma ferramenta especialmente útil quando as requisições feitas para um servidor envolvem processos complexos como cifragem e cálculo de hash, ou quando a quantidade de requisições necessárias para a ação é grande, com parâmetros e valores sendo reutilizados entre requisições. O Selenium controla o browser remotamente, sendo então desnecessária a programação de qualquer tarefa que não precise ser executada pelo usuário.
#!/usr/bin/env python3
from selenium import webdriver
from time import sleep
browser = webdriver.Firefox()
browser.get(“https://www.google.com.br”)
element = browser.find_element_by_xpath(“/html/body/div/div[3]/form/div[2]/div[1]/div[1]/div/div[2]/input”)
element.click()
element.send_keys(“Tempest”, u’\ue007')
sleep(3)
link_list = browser.find_elements_by_partial_link_text(“Home”)
for link in link_list:
if “Tempest” in link.text:
link.click()
break
O script acima, por exemplo, automatiza uma busca no Google pela palavra chave “Tempest” e clica no primeiro link que leve a uma página com “Tempest” e “Home” no título.
Monkeyrunner
Monkeyrunner é um framework de testes para aplicações Android que permite simular a interação do usuário com o dispositivo, controlando funcionalidades através de scripts Python.
Parte integrante do Android Studio Development Kit, o Monkeyrunner pode ser usado para automatizar ações em dispositivos Android e emuladores como o Genymotion. Assim como o Selenium, é especialmente útil quando as requisições para conclusão de uma ação são intrincadas ou numerosas, ou quando a aplicação realiza algum tipo de criptografia ou ofuscação. A ferramenta mencionada pode ser utilizada em um dispositivo com o modo desenvolvedor habilitado, mesmo que não tenha passado por um processo de ‘Rooting’.
from com.android.monkeyrunner import MonkeyRunner, MonkeyDevice
device = MonkeyRunner.waitForConnection()
logins = []
for line in open(‘~/Documents/logins.txt’,’r’):
logins.append(line.rstrip())
activity = ‘br.com.app.activity.LoginActivity_’
runComponent = activity
device.startActivity(component = runComponent)
for login in logins:
MonkeyRunner.sleep(6)
device.touch(200,785,’DOWN_AND_UP’)
device.type(conta)
MonkeyRunner.sleep(1)
device.touch(550,1101,’DOWN_AND_UP’)
MonkeyRunner.sleep(2)
device.touch(286,1502,’DOWN_AND_UP’)
MonkeyRunner.sleep(2)
device.touch(286,1502,’DOWN_AND_UP’)
MonkeyRunner.sleep(2)
device.press(‘KEYCODE_BACK’,MonkeyDevice.DOWN_AND_UP)
MonkeyRunner.sleep(1)
device.startActivity(component=runComponent)
O script acima simula a interação do usuário com a tela da atividade de login. A partir de uma lista de logins, o script insere os valores no campo de input do formulário de autenticação na tela, pressionando o botão de confirmação logo em seguida, repetindo o processo até que todos os logins tenham sido avaliados.
Frida
Frida é uma ferramenta de injeção de comandos em aplicações nativas de diversos sistemas operacionais. Pode ser usada para engenharia reversa e debugging de aplicações compiladas nesses sistemas. É a ferramenta comumente usada para o bypass de proteções como SSL Pinning e Root Detection. Tal ferramenta pode ser utilizada para a criação de tarefas automatizadas em aplicações para a realização de ataques de força bruta.
Soluções
Na prática, desenvolvedores empregam diversos mecanismos na tentativa de se prevenir contra esses ataques; no entanto, algumas implementações podem introduzir novos problemas de segurança às aplicações. A seguir, estão listadas algumas das soluções encontradas em aplicações reais, bem suas consequências.
Bloqueio de IP
Uma solução pouco ortodoxa, mas que vem, sendo aplicada, é a de bloqueio de IP. Essa abordagem consiste em, após um determinado número de tentativas malsucedidas, adicionar o IP do usuário a uma lista de IPs bloqueados que perdem o direito de acesso parcial ou total à aplicação, por um determinado período de tempo ou, em alguns casos, indefinidamente.
Embora, a princípio, esta possa parecer uma boa solução para o problema de muitas requisições sendo feitas de forma automatizada por um atacante, a adoção de uma funcionalidade de bloqueio de qualquer tipo abre a possibilidade de exploração dessa funcionalidade em ataques de negação de serviço direcionados aos usuários. Isto é, um usuário malicioso pode usar de ferramentas para compor pacotes disfarçando seu IP com o endereço IP de uma vítima e fazer uma quantidade excessiva de requisições até causar o bloqueio da vítima. Em situações mais extremas, todos os usuários de uma rede compartilhada podem ser bloqueados por consequência da implementação desse mecanismo de suspensão automática.
Bloqueio de Usuários
Similar ao Bloqueio de IP, essa solução opta por bloquear contas de usuários cujas credenciais foram incorretamente fornecidas por um usuário, um determinado número de vezes. Em alguns casos, há um intervalo de tempo, dentro do qual, as credenciais devem ser erroneamente tentadas para que haja o bloqueio. Além disso, casos assim podem ser contornados com uma abordagem de Força Bruta Horizontal, na tentativa de evitar o bloqueio durante a busca por uma credencial válida.
Assim como em uma funcionalidade de bloqueio de IP, existe aqui também o potencial de exploração dessa funcionalidade e uso em ataques de negação de serviço direcionados a usuários da aplicação.
Ademais, tal bloqueio pode gerar a enumeração de usuários a depender da forma como se comportam (como pode ser visto no blogpost citado anteriormente).
CAPTCHA
A sigla CAPTCHA, que significa “Completely Automated Public Turing Test to Tell Computers and Humans Apart”, traduzida para “teste de Turing público e completamente automático para diferenciar computadores e humanos”, consiste num desafio cognitivo facilmente resolvido por um humano, mas computacionalmente complicado de se resolver. Testes comuns são: escolher imagens específicas entre um grupo de imagens, dada uma palavra-chave; ou ler caracteres ofuscados em uma imagem.

CAPTCHAs comuns, baseados em desafios e respostas, devem implementar desafios computacionalmente difíceis de serem resolvidos e cujas probabilidades de acerto baseadas em pura sorte sejam baixas.
A imagem acima, temos um CAPTCHA falho. Seu desafio é, dada uma palavra-chave, encontrar a imagem que melhor represente essa palavra. Assim, independente das imagens serem simples ou intrincadas, por serem apenas 4, um script tem uma chance de 25% de acertar o desafio por pura sorte. Essa porcentagem pode ser aceitável para um atacante, dependendo da funcionalidade protegida por esse CAPTCHA.
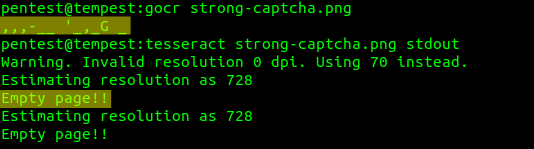
Outra falha comum na implementação do desafio de CAPTCHA é o uso de imagens facilmente reconhecidas por programas de reconhecimento óptico de caracteres, como GOCR e Tesseract. A imagem a seguir, por exemplo, pode ser completamente interpretada por um software de reconhecimento de caracteres:
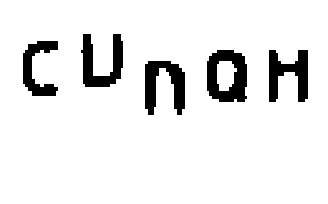

Outras imagens podem ser parcialmente seguras, isto é, os programas de reconhecimento de caracteres podem resolver parte do CAPTCHA, mas acabam por errar em alguns caracteres, como mostram as imagens a seguir:
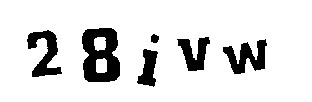

Implementações de CAPTCHA que consideram corretas respostas com um ou dois caracteres errados estão vulneráveis a ataques de Força Bruta caso usem imagens que podem ser parcialmente resolvidas por esses softwares.
Existem ainda alguns métodos para tentar otimizar a análise desses desafios. É possível realizar tratamento de imagem nos CAPTCHAs, na tentativa de aumentar a taxa de acerto do software, no entanto, uma opção mais simples é a de “treinar” o GOCR usando imagens previamente coletadas como amostras. Quanto maior o banco de amostras, maior a probabilidade de um aumento na taxa de acerto.
Imagens usadas como CAPTCHA devem ser geradas dinamicamente, tendo um nível de ofuscação grande o suficiente para impedir, ou pelo menos dificultar, as técnicas de otimização anteriormente citadas.

O NoCAPTCHA ReCAPTCHA é uma implementação de CAPTCHA que visa diminuir a quantidade de desafios apresentados aos clientes, tendo como principal fator de diferenciação o comportamento do usuário ao fazer uma requisição. Esse tipo de implementação avalia aspectos como tempo passado na página, padrão de digitação, movimentos de mouse e cliques para estimar um nível de risco para cada usuário. Quando o nível de risco calculado para um usuário é alto, um desafio com igual nível de solução é, então, proposto para este usuário.
CAPTCHAs são uma das medidas mais comuns contra ataques de Força Bruta e, por isso, usuários maliciosos vão sempre procurar uma forma de os contornar. Seja através das medidas anteriormente citadas ou, em alguns casos, pagando por serviços de resolução de CAPTCHA. Sendo assim, a implementação ideal de CAPTCHAs é uma camada de segurança a mais para sua aplicação.
Multi-factor authentication
Multi-factor authentication, ou autenticação em múltiplos fatores, é um método de autenticação que depende de um segundo canal de comunicação além da conexão com o servidor. É muito comum como uma segunda camada de segurança para ações críticas em uma aplicação, como login, mudanças de senha e confirmação de compras. Normalmente, consiste no envio de um código de confirmação por SMS, e-mail ou serviço de autenticação, como Google Authenticator e Authy. A confirmação multi-fator pode também ser realizada através de token de identificação instalado em dispositivo autorizado, como é o caso para muitos aplicativos bancários.
Autenticação em múltiplos fatores pode funcionar como uma boa forma de impedir pessoal não autorizado de realizar ações em nome de terceiros, mas deve ser implementada com cuidado para evitar a enumeração de usuários. Quando a autenticação acontece em múltiplas etapas, deve-se ter cautela para evitar que credenciais sejam comprometidas pela solicitação do código de autenticação.
Uma possível desvantagem da Autenticação multifatores é que, a depender do meio utilizado (como SMS, por exemplo), ela pode gerar um outro problema para a empresa. Usuários capazes de solicitar uma quantidade ilimitada de códigos podem usar Ataques de Força Bruta para solicitar o envio de uma grande quantidade de SMS para um ou muitos usuários, possivelmente gerando custos para a empresa vítima do ataque, além de causar desconforto para o usuário que venha a ser alvo desse ataque. O ideal nesse caso é limitar a quantidade de SMS que pode ser solicitada por um determinado IP (veja Rate Limiting adiante), ou optar pelo uso de serviço de autenticação.
Prova de Trabalho
Do inglês “proof-of-work”, o protocolo de prova de trabalho surgiu como uma forma de prevenção contra spams de e-mail e ataques de negação de serviço. Esse protocolo tem como objetivo garantir que o usuário gastou algum tempo para realizar uma determinada tarefa a partir de um desafio computacionalmente custoso e que precisa ser resolvido para que uma determinada ação seja autorizada. Esse é o protocolo empregado por algumas criptomoedas, como o bitcoin.
Prova de trabalho funciona da seguinte forma:
- O cliente solicita a execução de uma ação ou acesso a um serviço;
- O servidor responde ao usuário com um desafio a ser resolvido;
- O cliente resolve o desafio e envia a resposta para o servidor;
- O servidor analisa a resposta do desafio e, se estiver correta, autoriza o pedido do cliente.
Em algumas implementações, o processo de solicitação de serviço se dá em paralelo ao envio da resposta do desafio, mas o fluxo do protocolo é basicamente o mesmo.
Semelhante ao CAPTCHA, onde um desafio deve ser resolvido. O protocolo de prova de trabalho, no entanto, propõe um desafio que é resolvido automaticamente pelo cliente, isto é, a resolução do desafio consiste na execução de código no computador do usuário e a resposta para esse desafio é a saída dessa execução.
O mais popular dos mecanismos de Prova de Trabalho é o HashCash, onde a prova consiste em, dada uma string fornecida pelo servidor, encontrar o complemento dessa string de modo que o hash resultante comece com a quantidade de zeros esperada pelo servidor.
No exemplo a seguir, ao se fazer uma requisição para o site destino, um cookie “Challenge” e um cookie “Zeroes” são servidos ao cliente. Em seguida, ambos os cookies são usados para calcular o valor que é enviado no campo “challenge” do formulário de Login:
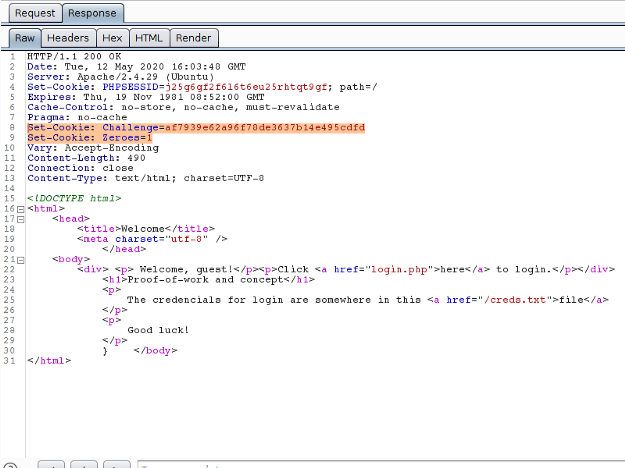
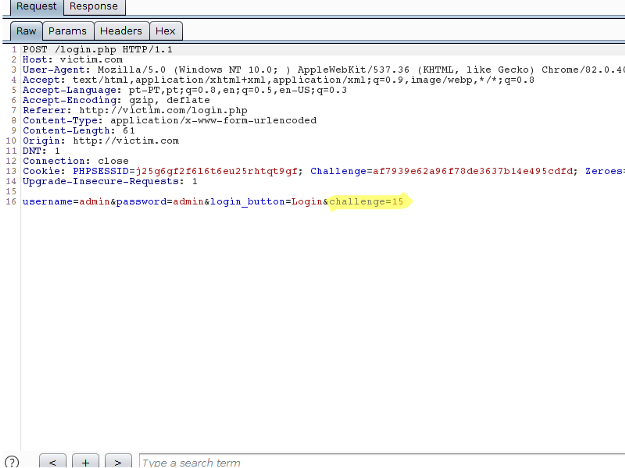
Note que a resposta para o desafio é simplesmente uma string que, quando concatenada com a string no cookie “Challenge”, pode ser usada para obter um hash SHA256 iniciando com a quantidade de zeros especificada pelo servidor.
Ainda no mesmo servidor, quando o parâmetro Challenge está ausente ou contém um valor incorreto, a resposta do servidor é um erro, e a requisição não é processada.

Na medida em que tentativas erradas vão sendo feitas, o servidor incrementa a dificuldade do desafio, aumentando a quantidade de zeros necessários para que a resposta seja considerada correta. Esse aumento de poder computacional necessário visa prejudicar requisições automatizadas, que passam a demandar mais tempo para calcular a resposta para o desafio proposto.
A partir do quinto zero, o navegador começa a levar cerca de 1 minuto para calcular a resposta para o desafio. E a partir do sexto, o navegador entende que a aba não está mais respondendo, levando cerca de 8 minutos para concluir o cálculo do hash.
O protocolo de prova de trabalho pode, de certa forma, atrasar ataques automatizados, uma vez que é necessária, não somente a automação das requisições a serem executadas, como também da resolução do problema proposto pelo protocolo, que é resolvido por código implementado no lado do cliente. Em aplicações mobile, por exemplo, a obtenção do trecho de código responsável pela resolução desse problema pode ser uma tarefa complicada, envolvendo a engenharia reversa do aplicativo. Mesmo em aplicações web, o Javascript responsável pela resolução do problema proposto pode estar ofuscado, minificado e pouco legível.
Uma forma de contornar essas soluções é com o uso de automatização de comportamento, com ferramentas como Selenium e Monkeyrunner. A automatização por meio dessas ferramentas é um pouco mais lenta, uma vez que o script simula o comportamento do usuário e não as requisições necessárias para a conclusão da solicitação de serviço. Se essa possibilidade de automatização, mesmo que mais lenta, ainda é um problema para uma determinada funcionalidade, a melhor opção para impedir esse tipo de ataque é o uso de CAPTCHA robusto.
Rate Limiting
Os algoritmos de Rate Limiting tem por objetivo controlar a taxa com que usuários podem fazer requisições para o servidor, seja o limite controlado a partir do IP ou do usuário. Existem algumas implementações para esse tipo de controle, mas de forma geral, os algoritmos mantém um registro com as requisições de cada usuário e o timestamp do momento em que elas foram feitas. Sempre que uma nova requisição do usuário chega ao servidor, os valores anteriores são consultados para determinar se a requisição está ou não autorizada a ser processada pela aplicação.
Ao optar por usar Rate Limiting como método de controle, deve-se tomar cuidado com parâmetro que será limitado. Atrelar o limite de requisições à sessão do usuário pode-se mostrar uma defesa inútil, especialmente para ataques contra mecanismos de autenticação; uma vez que o comportamento padrão de aplicações web para requisições sem um token de sessão é o fornecimento de um token novo com uma sessão totalmente nova.
Algumas APIs implementam o mecanismo de Rate Limiting em áreas autenticadas. Assim, uma vez que o token do usuário é conhecido, assim que a tentativa de abuso é detectada, este tem seu acesso à funcionalidade em questão, ou mesmo a própria aplicação, suspenso.
Teclado Virtual
Uma alternativa pouco ortodoxa, mas que pode ser encontrada implementada em ambientes em produção, é o uso de teclados virtuais. Comumente usados como defesa contra keyloggers e spywares, os teclados virtuais costumam ser implementados em aplicações bancárias, forçando o usuário a digitar seu pin ou senha a partir da interface virtual e não do teclado físico. Eles podem, ainda, mudar a ordem das teclas e, algumas vezes, até ofuscar seu real valor, trocando os números do pin por códigos que correspondam ao valor das teclas digitadas.
Uma confusão comum entre desenvolvedores, no entanto, é acreditar que ao impedir o usuário de digitar usando seu próprio teclado na interface web ou aplicativo, eles podem, de alguma forma, impedir que os scripts sejam automatizados; ou que a ofuscação, por mais simples que seja, o faça.
Contornar essas proteções pode ser algo trivial, mesmo para atacantes inexperientes. A ferramenta mais simples para isso é o Selenium Webdriver, mas uma análise simples do Javascript responsável pelo teclado virtual é mais do que suficiente para entender esse tipo de mecanismo. Uma vez entendido o processo de ofuscação, a confecção de scripts para automatizar as requisições necessárias torna-se descomplicada.
Conclusão
Assim como com qualquer outro problema de segurança, não existem soluções universais para ataques de Força Bruta. A melhor escolha para qualquer solução depende de uma análise do cenário de seu sistema, para ter certeza do que melhor se adequa ao seu contexto. Seu sistema pode ser uma API consumida por outras aplicações e, por isso, não haverá como empregar o uso de CAPTCHAs. Ou, imagine que sua funcionalidade seja de crítica importância, mas seus usuários tenham dificuldades para resolver desafios mais complexos. Esses são apenas dois possíveis cenários, que ilustram a necessidade de soluções bem estudadas para cada caso.
De todo modo, as diferentes soluções apresentadas aqui podem ser usadas como um só mecanismo de defesa, com diferentes camadas de proteção, oferecendo, assim, maior defesa para funcionalidades mais críticas. No entanto, deve-se prestar atenção às possíveis consequências da adoção de cada uma dessas soluções, já que a escolha do mecanismo anti-automação deve ser feita com cautela, de modo a considerar as funcionalidades a serem protegidas.
É importante salientar que, muitas vezes, ataques de Força Bruta são usados para explorar alguma outra vulnerabilidade na aplicação, seja esta um vazamento de informações, escalação de privilégios ou injeção de comandos. Proteger a sua aplicação de Força Bruta e não resolver as vulnerabilidades exploradas vai, no máximo, atrasar um atacante determinado. Ataques de Força Bruta podem, então, ser tomados como sintomas, e uma análise mais cuidadosa deve ser efetuada.
Referências
3.8.3 Documentation. 2020. Disponível em: https://docs.python.org/3/. Acesso em: 20 maio 2020.
FRIDA: A world-class dynamic instrumentation framework. A world-class dynamic instrumentation framework. 2020. Disponível em: https://frida.re/. Acesso em: 20 maio 2020.
GOCR. 2018. Disponível em: http://jocr.sourceforge.net/. Acesso em: 20 maio 2020.
MONKEYRUNNER. 2020. Disponível em: https://developer.android.com/studio/test/monkeyrunner. Acesso em: 20 maio 2020.
STUDDARD, Dafydd; PINTO, Marcus. The Web Application Hacker’s Handbook: discovering and exploiting security flaws. 2. ed. Indianapolis: John Wiley & Sons, Inc., 2011. 853 p.
TESSERACT documentation: Tesseract OCR. Tesseract OCR. 2020. Disponível em: https://tesseract-ocr.github.io/. Acesso em: 22 maio 2020.
WEBDRIVER: Documentation for Selenium. Documentation for Selenium. 2020. Disponível em: https://www.selenium.dev/documentation/en/webdriver/. Acesso em: 22 maio 2020.