Por Magnon Souza
Introdução
Vivemos em uma era de explosão de dados, estima-se que em 2020 criamos cerca de 1,7 MB a cada segundo. Isso equivale a 2,5 quintilhões bytes de dados por dia (um quintilhão é nada menos que 18 zeros). Esse volume surreal de informação tem feito muita gente questionar sobre a segurança e a privacidade dos seus dados, movimentando a discussão sobre dados pessoais identificáveis, capazes de reconhecer um indivíduo direta ou indiretamente.
Nesse cenário nasceu a General Data Protection Regulation (GDPR) na Europa, a Lei Geral de Proteção de Dados (LGPD) em terras tupiniquins, e diversas outras leis e regulamentações pelo mundo. Juntamente com essas regulamentações, surge a necessidade das empresas tratarem tal tipo de dado adequadamente. Para que esse procedimento possa ser feito de forma apropriada é importante que a organização atente para fatores, tais como: a natureza e o tipo dos dados que a organização pretende anonimizar, a administração do risco pela empresa ao impor ferramentas de controle para proteção e a utilidade dessas bases anonimizadas.
Mas o que seria anonimização de dados?
Um dado anônimo nada mais é do que uma informação que teve seus vínculos identificáveis removidos. Isso pode ser resultado de um processo de quebra de vínculo entre o titular e a informação bruta. A esse processo damos o nome de anonimização ou impersonificação de dados.
A partir de um dado bruto aplica-se uma ou mais técnicas de anonimização e verifica-se o risco de reidentificação. O risco foi muito baixo? Se sim, classificamos o dado como anonimizado. Caso contrário, continuaremos a aplicar diferentes técnicas de anonimização e reiniciamos a verificação.
Vale ressaltar que, segundo a literatura especializada, a anonimização que garanta 100% de eficácia não passa de um mito ou de uma idealização teórica. Qualquer dado anonimizado corre risco inerente de ser convertido em dado pessoal novamente. Isso significa que a anonimização deve ser posta em segundo plano ou vista como uma atividade de baixa prioridade? Jamais! A realidade é que assim como novas técnicas de anonimização surgem, novas táticas para burlar os processos de impersonificação são desenvolvidas. Sejam elas: novos algoritmos, maior poder computacional, cruzamento de dados de bases distintas, entre outras. Essa realidade só ratifica a importância da constante busca por aperfeiçoamento na aplicação de técnicas de anonimização e manutenção da proteção dos dados já anonimizados.
E qual a vantagem disso tudo?
Pode-se pensar que, só o fato de existir uma regulamentação coercitiva sobre o tratamento de dados pessoais e estar de acordo com a lei, seria motivo suficiente, mas vamos aqui elencar mais alguns outros pontos relevantes que corroboram com a importância e o valor do processo de anonimização de dados pessoais.
O primeiro ponto a ser comentado é o da proteção contra as perdas de confiança e participação no mercado. Não é difícil se deparar com uma notícia sobre vazamento de dados. Só até março de 2021 ocorreram ao menos 8 (oito) casos no Brasil. Episódios como esses podem gerar uma perda de confiança da sociedade na empresa que sofreu o vazamento e, assim, resultar em impactos no mercado. Isso se dá pelo fato de que essas bases vazadas podem ser usadas como referência para cruzamento de dados em outras bases, aumentando ainda mais o risco de reidentificação dos dados. Nesse caso, um processo de anonimização bem aplicado funciona como uma medida de controle de danos.
Outra vantagem que se pode notar é a proteção contra o mau uso e exploração de vulnerabilidades internas. Por mais que você confie na equipe que lida ou tem acesso à dados sensíveis, não há como garantir as intenções da pessoa que os manipula. Dessa forma, o processo de anonimização ajuda a dificultar que possíveis atacantes internos façam mau uso dos dados que a empresa tenha armazenado.
O que se deve saber antes de iniciar o processo de anonimização?
Para que se possa sair do campo conceitual e começar a pensar na impersonificação de dados é de fundamental importância ter um bom entendimento dos conceitos, desta forma será possível determinar quais as técnicas mais apropriadas, bem como, o nível adequado de anonimização. Os conceitos relevantes são:
- Propósito da anonimização e utilidade dos dados: parece meio óbvio, mas é importante, antes de tudo, entender bem a motivação por trás da ideia de aplicar técnicas de anonimização para um determinado conjunto de dados. Isso porque o processo, independentemente do nível ou da técnica, reduzirá em algum nível o detalhamento da informação contida no dataset original. Esse fato cria um trade-off entre utilidade aceitável (ou esperada) e tentativa de redução de risco de reidentificação. É importante ter em mente também que essa utilidade deve ser observada em nível do dataset inteiro e não unicamente no atributo.
- Características próprias das técnicas: é necessário atentar ao fato de que certos métodos são mais apropriados para determinadas situações que outros. Além disso, diferentes técnicas modificam dados de formas distintas.
- Inferência de informação: precisa-se atentar ao risco de cruzamento de informações. Ainda que certo atributo esteja anonimizado e com baixo risco de reidentificação, deve ser analisado o risco de obtê-lo através de inferência com a ajuda de outros atributos.
- Expertise do domínio: a escolha adequada depende do entendimento das informações explícitas e implícitas contidas no conjunto de dados, bem como, a quantidade ou tipo de informação a ser anonimizada.
- Competência no processo e nas técnicas: a tarefa de anonimização precisa ser cuidada por alguém com bom entendimento de todo o procedimento e suas implicações, principalmente para dados que serão compartilhados com terceiros.
- Destinatário: esse é quem vai receber os dados anonimizados. Assim, fatores como o conhecimento sobre o assunto e aplicação de ferramentas de controle para limitar sua manipulação dos dados têm um papel importante na escolha das técnicas mais adequadas.
Pode ser qualquer tipo de dado?
Uma das questões que irão determinar quais técnicas de anonimização serão aplicadas é o contexto. Uma forma de pensar nele é como esses dados se caracterizam. A depender dessas características, as técnicas descritas neste texto podem não fazer sentido ou não surtir o efeito apropriado ou esperado. Portanto, antes de falar sobre essas estratégias de anonimização é preciso primeiramente entender o escopo dos dados.
Uma outra distinção importante a ser observada, que impacta na escolha da estratégia de anonimização, é a natureza do atributo em si: numérico ou categórico. Um dado numérico é aquele que, como o nome já diz, se trata de um número. Sendo assim, técnicas que ocultam o valor ou o substituem por outro provocam uma queda considerável na utilidade daquele dado. Já dados categóricos são aqueles que podem ser vistos como grupos distintos e finitos com base em alguma propriedade qualitativa. Em ambos os casos, a análise do conteúdo do próprio atributo é que irá determinar qual a técnica mais apropriada. O conhecimento da utilidade daquele atributo e o risco de reidentificação (dada uma certa técnica e o nível de anonimização aplicado) guiarão a decisão.
Técnicas
Com o propósito da tarefa em mente, bem como, o formato dos dados que serão anonimizados e suas particularidades, pode-se então iniciar o processo de análise e escolha de quais técnicas serão utilizadas e em que atributos (ou colunas) elas serão aplicadas. São algumas técnicas:
a)Generalização (Generalization)
Consiste na redução da precisão dos dados: os valores dos atributos são substituídos por outros semanticamente semelhantes, porém, menos específicos. Dessa forma, a generalização preserva a veracidade dos dados.
Esta é uma técnica que pode ser aplicada tanto em atributos categóricos como também numéricos. Quando se fala de atributos numéricos, pode-se pensar em atribuir um intervalo. Desse modo, o dado se mantém útil do ponto de vista analítico, sem deixar explícito qual seria o dado real. Já em atributos categóricos a estratégia é semelhante, todavia, com uma hierarquia semântica que abstrai o valor exato do dado, mas preserva o sentido.
É importante notar que a generalização não pode ser feita de forma ingênua, pois isso pode levar à dados inúteis, em particular para tarefas de análise. Assim sendo, deve-se buscar um conjunto mínimo de modificações de forma que favoreça a utilidade e atenda aos requisitos mínimos de impersonificação . Uma solução ótima para esse problema está, infelizmente, dentro da classe NP-difícil. Por isso, o caminho mais adequado é buscar uma heurística que reduza o espaço de busca e encontre uma solução próxima da ótima.
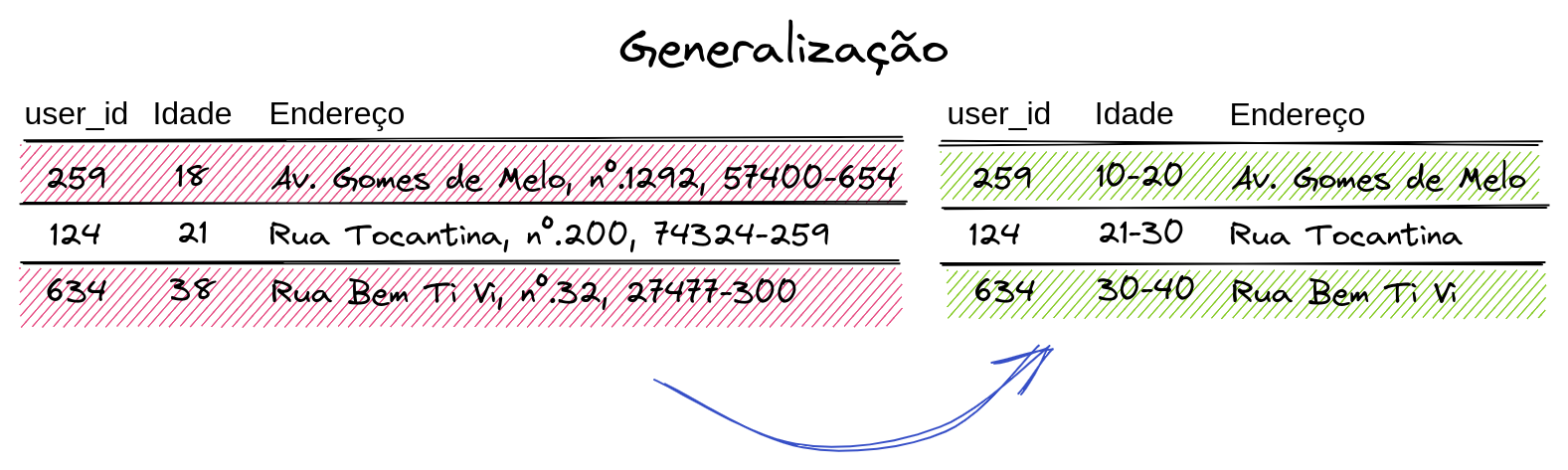
No exemplo acima podemos notar a aplicação da técnica nas colunas “Idade” e “Endereço”. Na primeira, transformou-se o valor bruto da idade do indivíduo num intervalo; já na segunda, houve uma abstração hierárquica do valor do campo endereço que em vez de possuir o logradouro, número e CEP, possui apenas o nome do logradouro. Essas generalizações possibilitam que a informação preserve um certo nível de poder analítico e oculte o seu valor exato.
b)Agregação de dados (Data aggregation)
Corresponde ao processo de converter um conjunto de dados em uma lista de valores resumidos. Em outras palavras, em vez de uma coleção com diversas entradas contendo dados pessoais, transformamos em novas colunas, que preservam as propriedades estatísticas da base e mascaram a identidade dos portadores da informação.
Essa tática se diferencia da generalização para atributos numéricos, ao passo que esta, apenas abstrai o valor de cada célula de uma determinada coluna, enquanto aquela transforma a estrutura do dataset, removendo colunas e criando outras.
É preciso ter cuidado com o tamanho dos grupos agregados para evitar que eles tenham poucas entradas. Para um atacante com informação suficiente, um grupo com um único indivíduo pode conter informações necessárias para a reidentificação.
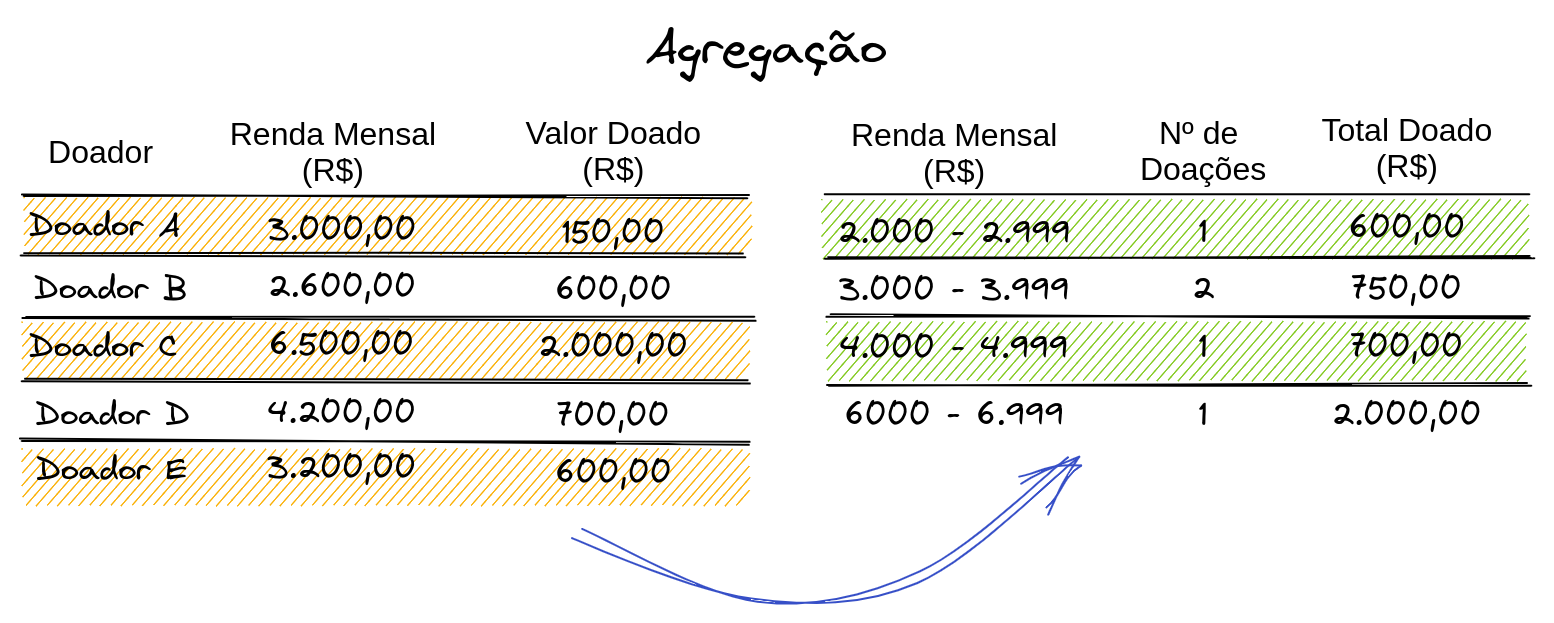
Aqui podemos notar que a informação de Doador foi ocultada através da agregação dos valores de salário mensal num intervalo, bem como, o total doado deixou de identificar um indivíduo para corresponder à soma de cada conjunto de intervalos.
c)Mascaramento de dados (Data masking)
Também chamado de mascaramento de caracteres, essa é uma estratégia focada em substituir caracteres do valor de uma coluna ou atributo por símbolos como, por exemplo, “*” ou “x”.
O mascaramento normalmente é feito parcialmente sobre o valor do atributo, ou seja, apenas parte do dado fica oculto. Assim, a depender de sua natureza, a técnica pode ser aplicada numa quantidade fixa de caracteres (por exemplo, em números de cartões de crédito, já que possuem um comprimento específico) ou em uma quantidade variável (para casos como e-mails, que são de tamanhos distintos). Para tomar essa decisão é preciso analisar qual parte e tamanho são mais apropriados para o mascaramento de forma que os caracteres que permanecerem visíveis não viabilizem a reidentificação.
Para o caso especial em que o proprietário do dado deve ser capaz de reidentificá-lo (como por exemplo, o mascaramento dos últimos cinco dígitos do CPF num resultado de um concurso), foge-se ao propósito das técnicas de anonimização, que é inviabilizar todas possibilidades de reconhecimento por qualquer indivíduo. Por isso, esse cenário deve ser tratado fora do escopo da tarefa de impersonificação.
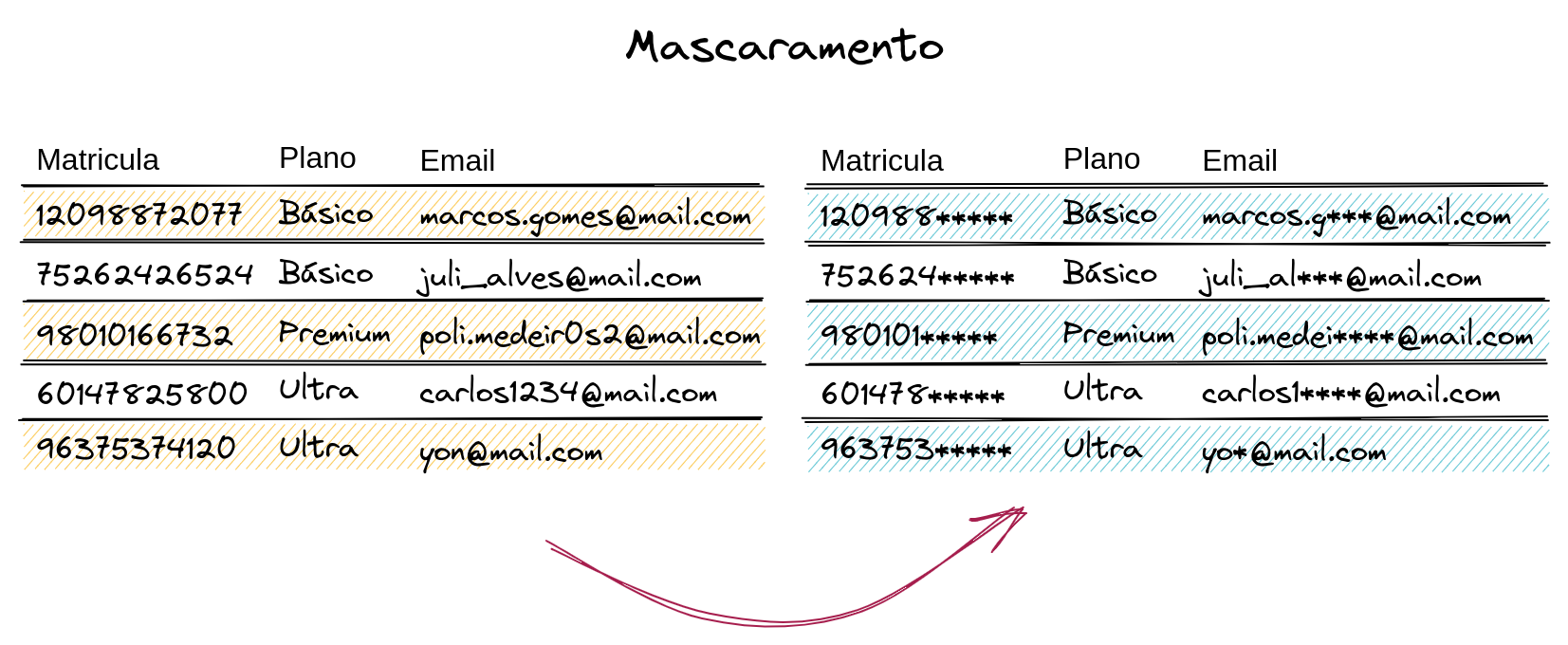
No contexto acima, podemos observar os dois casos de mascaramento: para a coluna de Matrícula, foi ocultado uma quantidade fixa de caracteres; já o campo Email, por apresentar tamanho variável, foi escolhida uma fração da cadeia (no caso, ⅓). É preciso atentar para que não seja determinado um número exato de caracteres, pois isso pode levar ao ocultamento completo da informação.
Para casos que a ocultação completa do dado seja mais apropriada, é mais adequado e menos custoso, que seja aplicado uma supressão de dados (técnica em que a coluna é completamente removida da base de dados).
d)Pseudo Anonimização
Provavelmente uma das técnicas de anonimização mais conhecidas, pseudoanonimização é a substituição de um identificador com valores falsos. Esses devem ser únicos e não apresentar qualquer relação com os dados originais.
Os pseudônimos podem ser aleatórios ou gerados deterministicamente, mas ainda assim, a informação do dado original é completamente perdida. Dessa forma, percebe-se uma grande perda de utilidade. Uma tentativa de preservá-la é o uso de pseudônimos persistentes, ou seja, usar o mesmo pseudônimo para identificar o mesmo indivíduo em diversas bases de dados.

Observe, no exemplo acima, que para a coluna Aluno foram gerados valores falsos e aleatórios para substituírem os valores originais. Como essa técnica provoca a perda total da informação, é utilizada, comumente, uma outra tabela que relaciona os dados antes da anonimização com os dados após, e ela é preservada em posse de terceiros.
e)Perturbação de dados (Data perturbation)
De forma geral, essa técnica consiste em substituir os valores originais dos atributos por outros levemente distintos. Diferentemente da generalização, essa abordagem não preserva a veracidade dos dados originais, por isso, a utilidade do dado é fortemente afetada, apesar da modificação ser sutil.
O grau de perturbação deve ser proporcional ao intervalo dos valores do atributo. Em outras palavras, se a base é pequena, o efeito será mais fraco, mas se a base for muito grande, a diferença dos valores pode vir a ser muito elevada. A perturbação pode ser feita através da adição de ruído (típica de atributos numéricos), que consiste na adição ou multiplicação do valor original por um offset .
Dessa forma, certas propriedades estatísticas são preservadas, como média e correlação. Por outro lado, pode produzir valores sem significado expressivo. Outra maneira de perturbação, aplicável a atributos numéricos e categóricos, seria por meio de uma outra técnica de anonimização denominada permutação de dados. Nela, registros diferentes são trocados entre si. Essa abordagem, semelhante à adição de ruído, preserva algumas propriedades estatísticas (como contagem e frequência), mas acaba gerando entradas sem valor semântico.

Para o exemplo acima podemos notar que os dados após a aplicação da técnica sofreram uma pequena variação se comparados aos valores originais, com a adição de um ruído. Nesse caso, foi aplicado um arredondamento para os múltiplos mais próximos de cinco (altura) e de três (peso e idade).
Conclusão
A anonimização de dados é, portanto, uma tarefa de importância latente nos tempos atuais. Ela demanda um esforço não apenas suficiente a fim de que possa ser bem aplicada, mas também um esforço para que haja um trabalho aprofundado na investigação e compreensão dos dados, bem como, das diversas técnicas de impersonificação.
O formato e o uso dos dados são os pontos centrais para a definição dos riscos de reidentificação do dado original. Estes permitirão identificar quais atributos são os mais favoráveis para a impersonificação. A partir desse ponto a natureza da informação determinará quais serão as técnicas mais apropriadas de forma que seja preservada ao máximo a utilidade do dado sem comprometer o mascaramento da informação. Assim, é importante que haja conhecimento aprofundado do comportamento dessas estratégias, não apenas para evitar que o dado possa ser associado a seu proprietário, maspara que não perca seu valor do ponto de vista analítico.
A discussão sobre anonimização de dados não se limita ao escopo deste texto. O propósito aqui foi trazer uma introdução ao tema com a finalidade de ratificar sua importância e demonstrar alguns exemplos da sua diversidade de estratégias. Com esta discussão espera-se, então, que o leitor possa iniciar uma análise do seu cenário para começar a buscar a forma mais adequada de aplicar anonimização em suas bases de dados.
Referências
BIONI, Bruno. Compreendendo o conceito de anonimização e dado anonimizado. Disponível em http://genjuridico.com.br/2020/08/05/conceito-anonimizacao-dado-anonimizado/ . Acesso em 25 de Julho de 2021.
BRITO, Felipe Timbó. MACHADO, Javam. Preservação de Privacidade de Dados: Fundamentos, Técnicas e Aplicações. Disponível em https://www.researchgate.net/publication/318726149_Preservacao_de_Privacidade_de_Dados_Fundamentos_Tecnicas_e_Aplicacoes. Acesso em 10 de Agosto de 2021.
CORPORATE FINANCE INSTITUTE. Data Anonymization: The process of preserving private or confidential information by deleting or encoding identifiers that link individuals and the stored data. Disponível em https://corporatefinanceinstitute.com/resources/knowledge/other/data-anonymization/. Acesso em 11 de Agosto de 2021.
IMPERVA. What is Data Anonymization. Disponível em https://www.imperva.com/learn/data-security/anonymization/. Acesso em 11 de Agosto de 2021.
MURTHY, S., BAKAR, A. Abu, RAHIM, F. Abdul, RAMLI, R. A Comparative Study of Data Anonymization Techniques | IEEE 2019 Conference Publication. Disponível em https://ieeexplore.ieee.org/document/8819477. Acesso em 12 de Agosto de 2021.
PERSONAL DATA PROTECTION COMISSION SINGAPURE. Guide to Basic Data Anonymisation Techniques – 2018. Disponível em https://iapp.org/media/pdf/resource_center/Guide_to_Anonymisation.pdf. Acesso em 11 de Agosto de 2021.
VASCONCELLOS, Hygino. Vazamento de dados de 220 milhões de pessoas: o que sabemos e quão grave é. Disponível em https://www.uol.com.br/tilt/noticias/redacao/2021/01/28/vazamento-expoe-dados-de-220-mi-de-brasileiros-origem-pode-ser-cruzada.htm. Acesso em 11 de Agosto de 2021.